
活動報告: データ利活用分科会 第四回イベントレポート
みなさん、こんにちは!先日ほんのり暖かい陽気を感じましたが、みなさんの地域はいかがでしょうか。
さて、2022年2月17日12:00 – 13:00に開催された第四回イベントレポートをお届けいたします。
毎回多くの方にご参加いただいておりますが、今回は分科会メンバーの半数以上の方々にご出席いただきました。ちなみにLunch & Learnということで、当日のチャットに上がったみなさんのLunchの一部をご紹介すると、タコライス、パスタ、シチューなどなど!うどん?を茹でている方もいました(笑)
今回のご登壇者の方々をご紹介いたします。
アクセンチュア 青柳様、横山様
ちゅらデータ 秋山様
澪標アナリティクス 藤原様
G-gen 杉村様
10分のLTと思えない濃い充実した内容をご発表いただき、誠にありがとうございました!!
それではLearnのイベント模様もご紹介いたします。
(wywy 合同会社 / 遠藤 祥子)
LT のご紹介
LT1. アクセンチュア 青柳 雅之 様、横山 祐樹 様
「データマネジメントとGCP」
今では当たり前に耳にする「データマネジメント」の導入のアプローチと事例紹介を頂きました。
データマネジメントは何から始めるべきか
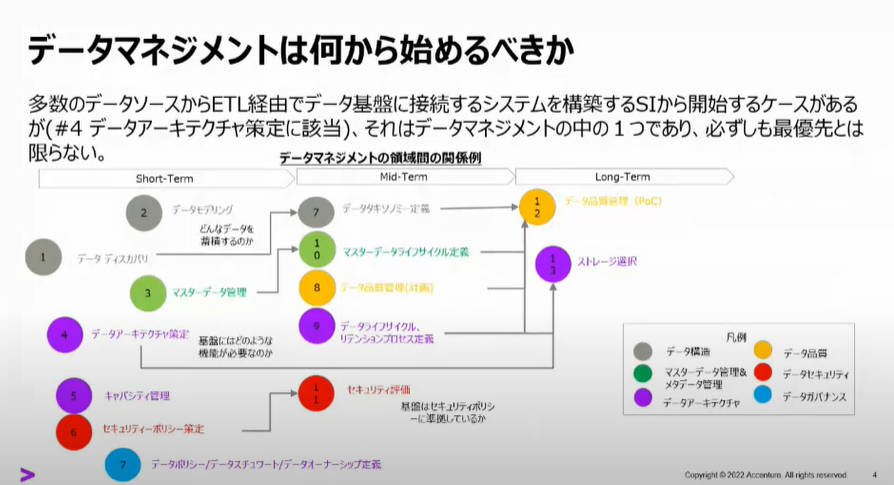
データマネージメントの導入順序についてのご紹介。
本来は、蓄積対象とするデータの選定①から開始するのが正攻法なのだけれども、
市場(User側)は、環境の構築④から始めることが多いとのこと。(実は筆者のところも・・・)
そんなときに取り組むべきアプローチとして次の2つのご案内。
データディスカバリーとデータ品質に早期に取り組む
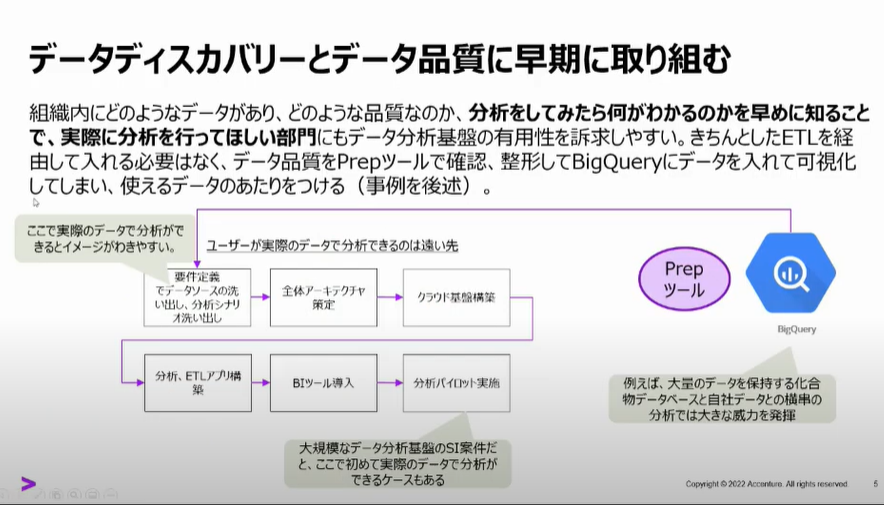
蓄積対象とするデータの選定①作業を「現場を巻き込む」「hands-onで実体験を積ませる」ことで必要なデータの棚卸しと、効果測定を行うPoC的なアプローチなのだな。と感じました。
環境があっても利用目的、方法が明確でないとただの箱になってしまいますものね。
重要なデータから統合する
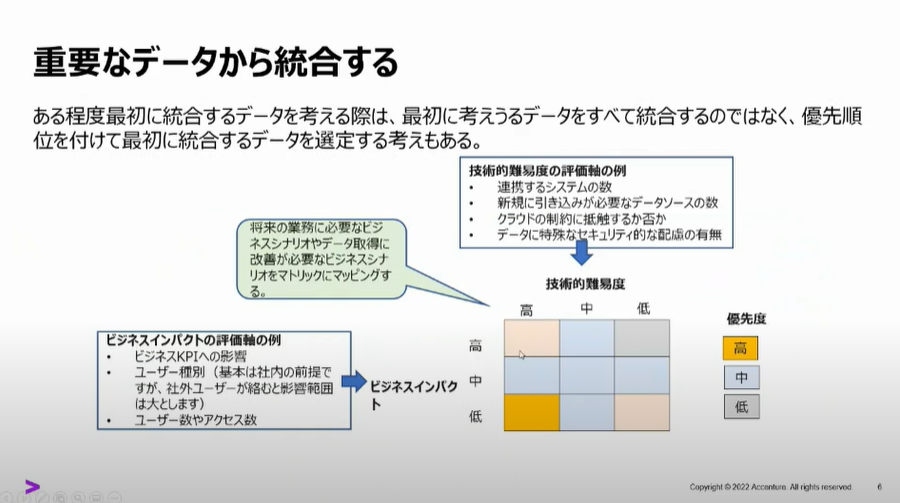
優先順位づけしてデータを統合するアプローチ。
こちらは筆者の会社が該当していまして事業会社ごとに優先されるものは違いますが、例として筆者の会社の優先順位をご紹介すると、基幹データ(販売、購買、生産、財務)が最優先で統合しその後、工場センサーデータやオープンデータなどを統合するアプローチをとっています。
データ利用者とデータオーナー間の利用規約を定義する
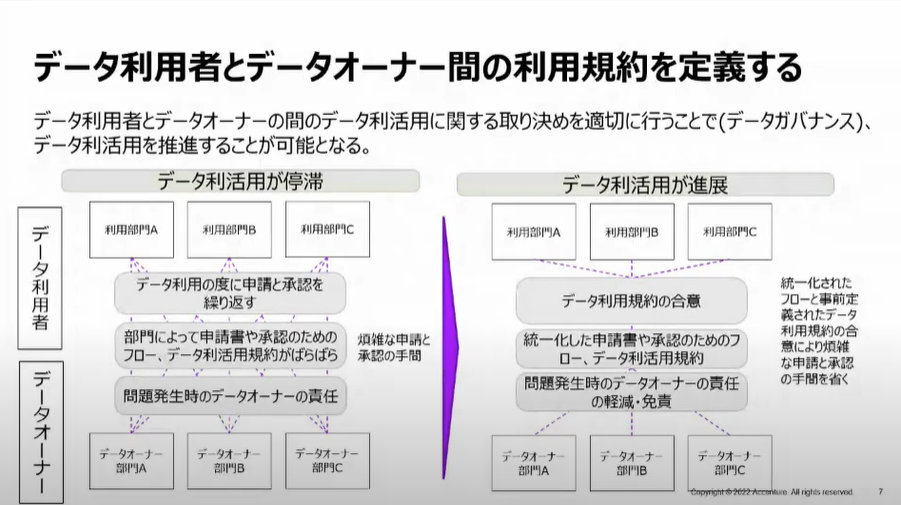
「利用規約の定義」こちら、非常に共感するご紹介でした。
記載にある「煩雑な申請と承認の手間」これが本当に利用を停滞させます。させました!
利用者からすると申請が煩雑なだけで利用の意欲がぐっと落ち込むだけでなく
現状維持バイアスも相まって嫌いになってしまう人もいますので要注意ですね。
ガバナンスプロセスでデータを追加する
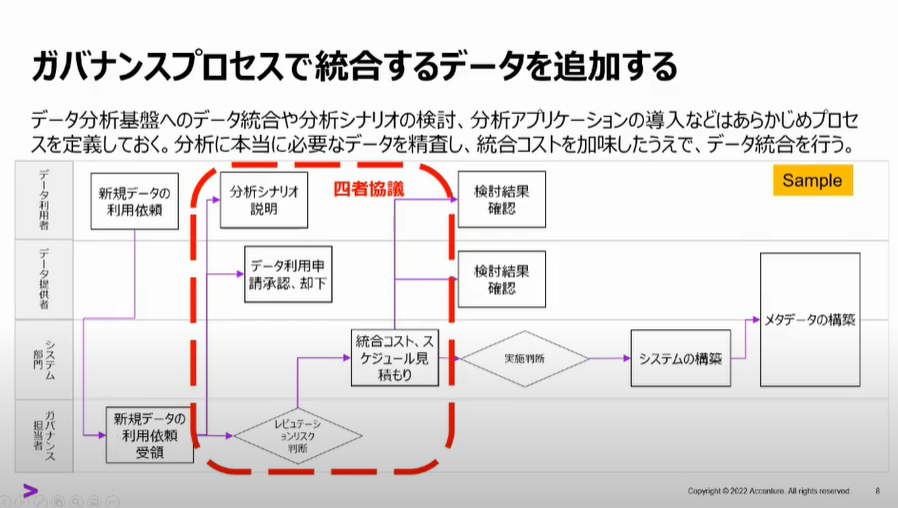
データとアプリの氾濫を抑え、投資対効果を得る為に必要なプロセスになりますね。
このプロセスがない企業様があったとするとデータが重複して環境にあったり、分析ツールが部門によってバラバラだったりとデータマネージメントから離れた結果を見てしまうことになりえます。怖っ。
レピュテーションリスクへ対応する
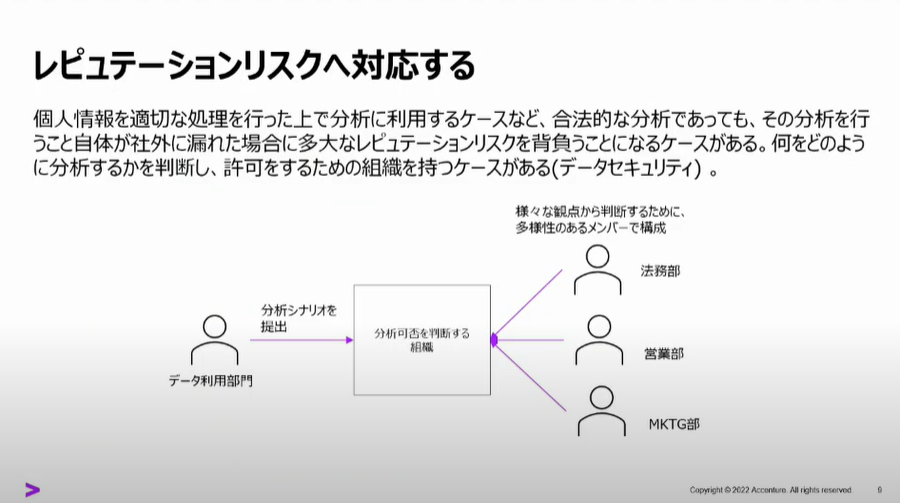
レピュテーション(評判)のリスク対応
「個人情報を合法的な分析であっても、分析行為が社外に漏れた場合のリスク」というのが「個人情報のデータでなにかしているらしい」といういかにも情報拡散社会を象徴するリスク対応ですね。
事例:化学メーカーでのオープンデータの活用
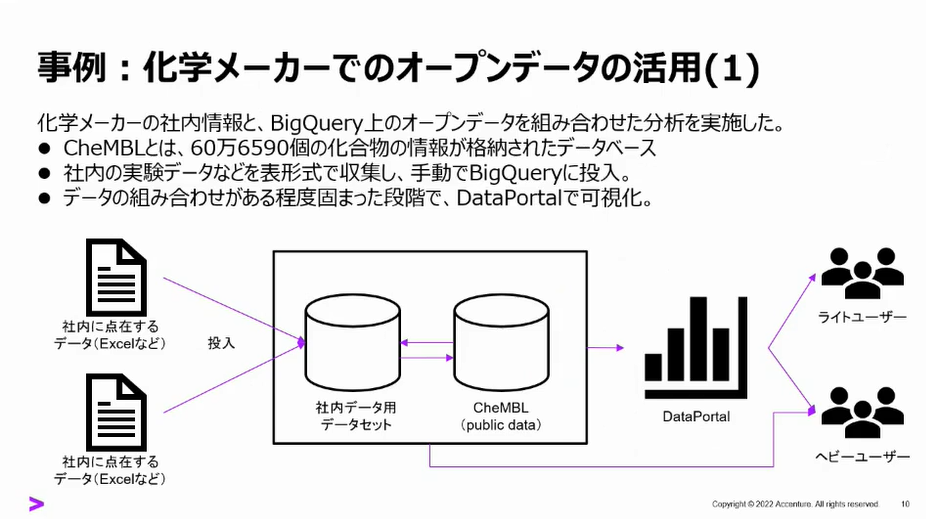
社内の実験データとオープンデータ(CheMBL)をBigQuery上で統合、分析をされたとのこと。
BigQueryの利点である、数PB(1ペタバイト=1,024TB)も処理しきるパワーと環境立ち上げの即効性が非常に役立った!(ですよね。これしっちゃうとね?)
加えて、オープンデータの利活用もBigQueryを利用することで容易にコネクトし、データの収集、分析が出来たそうです。
アジャイル工法を下支えするBigQueryということなのですね。
まとめ

データ利活用が目的であり、BigQueryを始め分析基盤は方法でしかない、
目的達成のためにBigQueryが非常に有効であったという結論でした。
筆者はBigQueryを使い始めてまだ日が浅いですが、他のDWHと比較して処理のパワー以外にも利便性(各APPとの連携、ユーザービリティ)に改めてGoogle社の恐ろしさ(いい意味で)を感じております。
青柳さん、横山さん
ご登壇ありがとうございました。
(株式会社 LIXIL / 平野 圭一)
LT2. ちゅらデータ 秋山 解 様
日本がAI先進国になるために著作権法が神改正された話
データを扱う上で重要な問題「著作権」。
その著作権を定めた著作権法がどう改正されたのか?メリットは?を秋山さんからご紹介頂きました。
AI開発をやる上で欲しくなるもの3つ

- 優れた技術
- 無尽蔵の計算資源
- 無尽蔵のデータ
まずはAI開発といえば、機械学習やディープラーニングがありますが共通して必要な(欲しい)要素がこの3つ。
著作権が関連する③の無尽蔵のデータについて以降、ご紹介。
無尽蔵のデータがWebで手に入る時代

- CC-100
- ImageNet
- など
データを集める方法。
(オジサン的には)昔はデータといえば、商社やマーケティング会社から物理媒体を介して自社のDBMSへ格納するなんて時代でしたが・・・
今は、手軽に、簡単に、迅速にWebから入手できるけど「誰かのもの」のはず。
さて、「誰かのもの」はどう扱えばいいのでしょうか?
「えっ?勝手に使っていいの?」という驚きと「どこまで勝手に?」という疑問。
平成29年までの著作権法

平成29年まではデータ解析に使用してもいいとあるが…
中途半端!不明瞭!そうなのです。
グレーゾーンがあって利便性が悪い法になっていたということでした。
平成30年改正著作権法

そこから改正された平成30年著作権法。
緩和されました。
ちなみに享受とは一般的には、以下のように定義付けられています。
「精神的にすぐれたものや物質上の利益などを,受け入れ味わいたのしむこと」
* 新村出編(2017)広辞苑(第七版)岩波書店 p762
また、「法第30条の4に規定する 「著作物に表現された思想又は感情」の「享受」を目的とする行為に該当するか否か」については、
同条の立法趣旨及び「享受」の一般的な語義を踏まえ,著作物等の視聴等を通じて,視聴 者等の知的・精神的欲求を満たすという効用を得ることに向けられた行為であるか否か
*「デジタル化・ネットワーク化の進展に対応した 柔軟な権利制限規定に関する基本的な考え方」
https://www.bunka.go.jp/seisaku/chosakuken/hokaisei/h30_hokaisei/pdf/r1406693_17.pdf
という観点に基づいて判断されるそう。
つまり「人が著作物から経験、体験するものでないならOK!」ということ。
なので機械学習、ディープラーニングなどの分析にはなんの支障もないという結論に至ると。
なるほど。
具体的にできること例1

享受しないのでできちゃいますね。
2点目のGitHubでコメントされていましたが、自動生成したものは問題ないですが
学習に使用した著作物とよく似たものが出力で再現されてしまうようなことがあると複製権や翻案権の侵害となる可能性が高いのでご注意を。
「材料としての利用だけに限定し、再生しない」ことが大事ということですね。
社内事例1

ちゅらデータさんの事例、文章校正ツール「ちゅらいと」。
Webからクローリングしてきた文章を学習として利用し学習モデルを構築したということなのかな?と秋山さんご自身が関わったものではないとのことでご紹介まで。
具体的にできること例2

できること例2。著作物を含むデータセットを第三者に提供・販売できる。
著作物を自分のものとして転売するとアウトですが、著作物が本来の目的と異なった利用で著作権者の不利益にならなければOK。
社内事例2
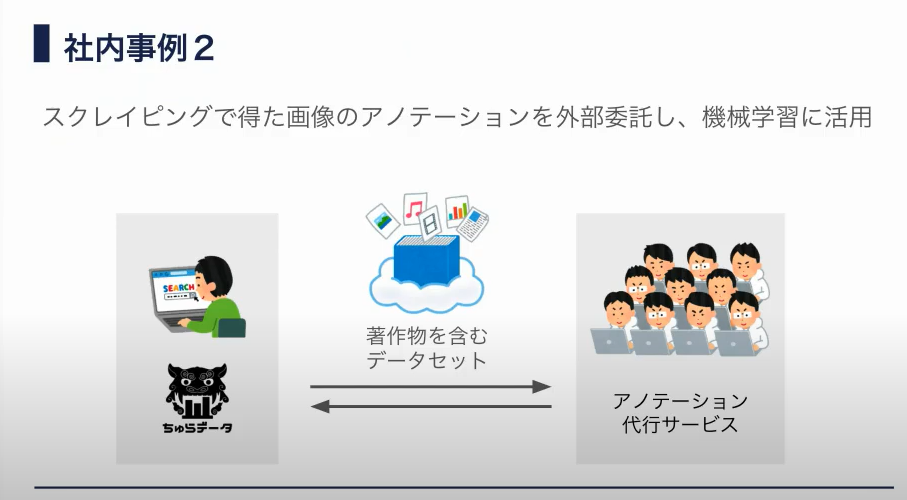
非常に分かりやすい例で筆者は助かりました。
著作物自体の目的(例えば写真)と異なる利用(機械学習データ)なのでOK。
著作物の利用について判断が難しいなぁと感じたら法務・弁護士に相談しましょう。
まとめ

日本はテクノロジーが10年遅れと揶揄されて久しいですが、
AI先進国になれるか?!いやみんなでしていこう!という力強いメッセージで締めていただきました。
秋山様、ご登壇ありがとうございました。
(株式会社 LIXIL / 平野 圭一)
LT3. 澪標アナリティクス 藤原 伸哉 様
「グラフィカルモデリングから読み解くユーザー行動分析事例 」
次の登壇者は、データ利活用分科会の運営メンバーでもある、澪標アナリティクスの藤原さんです。
藤原さんは、社員の約85%をアナリストが占める(!)アナリスト集団の会社、澪標アナリティクスで人材開発チームマネージャーを務めています。
藤原さんはゲームやエンタメの分析がご専門。今回は、ゲームユーザーの離反防止分析の事例をご紹介いただきました。
分析事例の背景

まず今回の分析のスタート地点のご紹介。以下は藤原さんの分析の対象・目的・前提・分析のモチベーション・分析方針の要約です。
<分析対象>
ゲームアプリの新規登録ユーザー
<目的>
ユーザーの離反防止
<前提>
- 離反防止に関わる要因Aは事前分析からすでにわかっている
<分析のモチベーション>
- 継続ユーザーと離反ユーザーの行動の違いを把握したい
- ユーザーにどんな行動を促せばいいのか示唆を得たい
- 要因Aに関連する変数同士の繋がり(構造)を俯瞰的に理解したい
<分析方針>
- 俯瞰的理解が可能なグラフィカルモデリングを採用
- 事前分析に用いた決定木分析では局所的理解に留まっていたため
グラフィカルモデリング
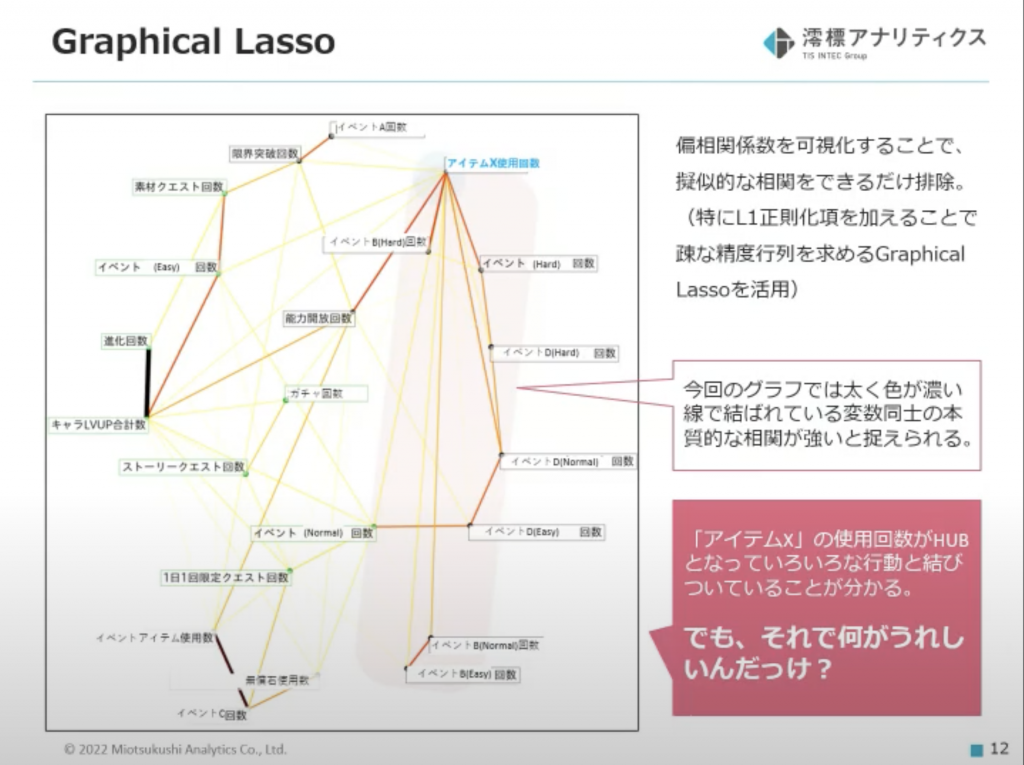
こちらがグラフィカルモデリングによる分析結果です。グラフによって変数間の繋がりを俯瞰できました。
グラフのノード(頂点)を結ぶエッジ(線)が太く、色が濃いほど、偏相関係数が強いことを示しているそうです。
通常の相関係数だと「アイスクリームの売り上げが高いとプールでの溺死事故が増える」みたいな見せかけの相関が混じっても区別がつきませんが、偏相関係数だと本当に知りたい本質的な相関と区別ができるわけですね。これもグラフィカルモデリングの嬉しさです。
<示唆>
- 変数「アイテムXの使用回数」がハブになって他のいろんな行動が繋がっている
ただ、この繋がりが見えたところでKPIが良くなるのか悪くなるのかをこのグラフからだけでは判断できない!このグラフをどう使うかが、藤原さんの腕の見せどころです!
グラフをどう活用したか
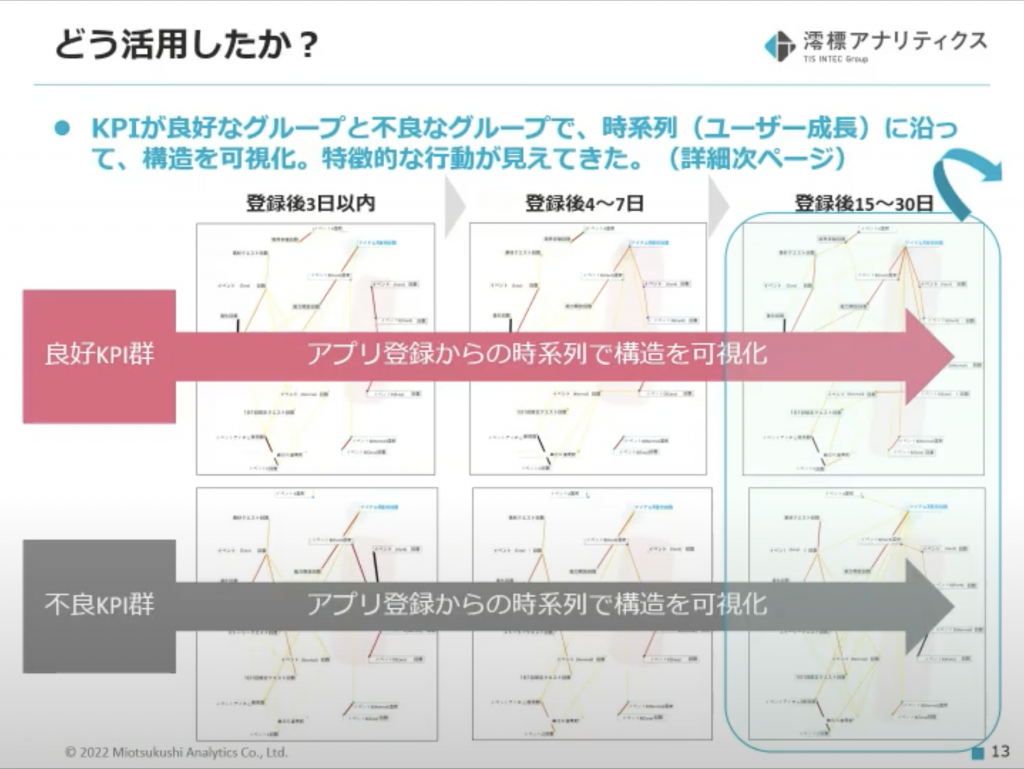
藤原さんの考えた活用方法はこちら!
<活用方法>
- データをセグメントに分けてグラフ化する(良好KPIグループ・不良KPIグループ)
- データを時系列で区切ってグラフ化する(アプリ登録後3日以内・アプリ登録後4〜7日・アプリ登録後15〜30日)
上記の方針で分析を行った結果、次のスライドで比較されている良いKPIと悪いKPIを見分ける特徴的な関係性(繋がり)を見つけることができたそうです。
比較って重要ですね!
得られた示唆
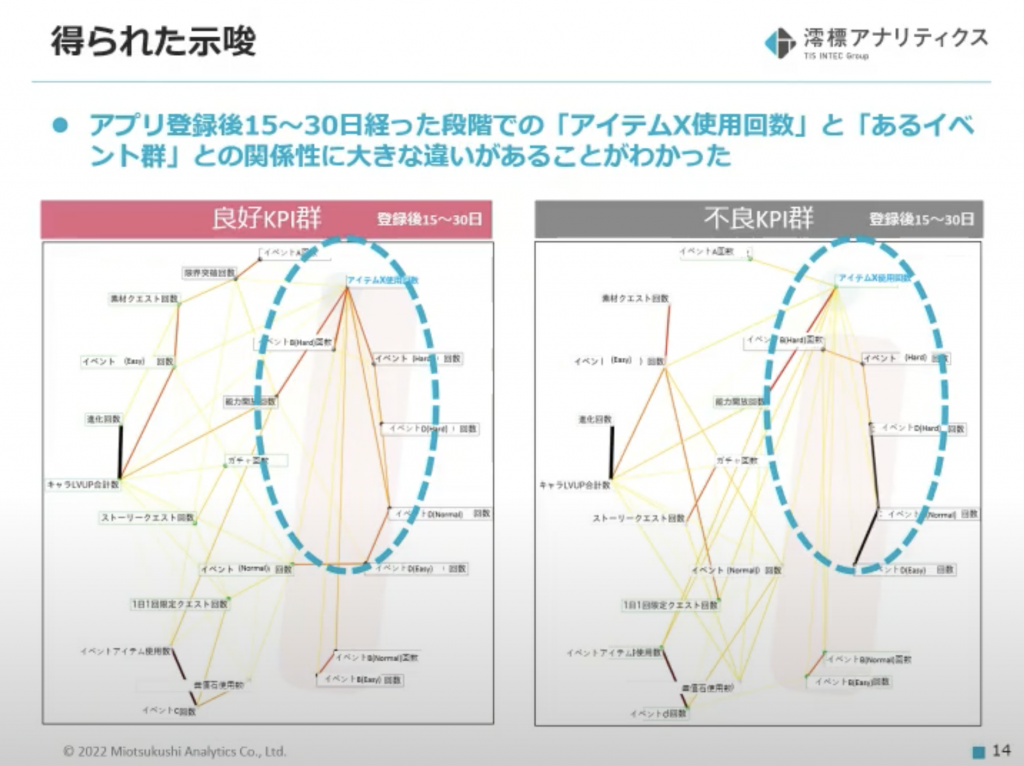
アプリ登録後15〜30日におけるグラフから、特徴的な関係性を発見!
<示唆>
- 良好KPIグループ
- 「アイテムXの使用」とあるイベント群の繋がりが強い
- 不良KPIグループ
- 「アイテムXの使用」とあるイベント群の繋がりが弱い
これがわかると打ち手がありそう!!しかし、まだまだ藤原さんは慎重に懸念点を洗い出します(以下は一部抜粋)。
<懸念点>
- アイテムXを使用することと、KPIが高くなることの関係性はまだ疑わしい
ここからさらに深掘り分析を行います!
補足分析
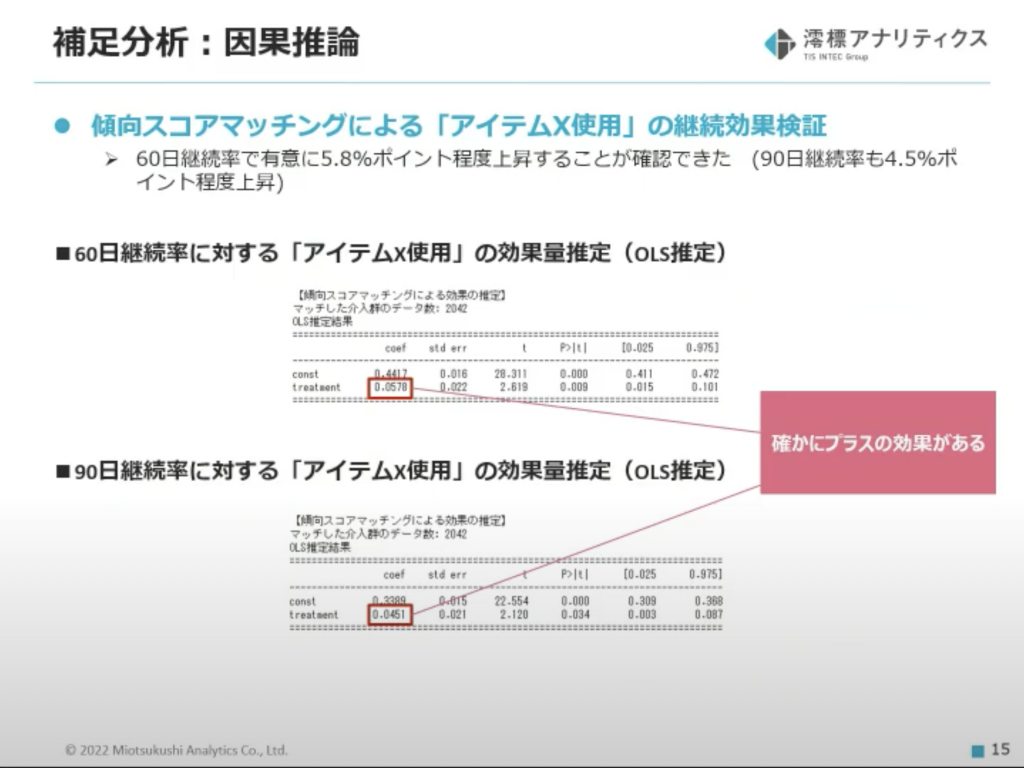
「アイテムXの使用」によってKPIが良くなるという仮説を検証するために、最後に「アイテムXの使用」が60日継続率と90日継続率に与える効果量の推定を行いました。
「アイテムXの使用」の純粋な効果を推定する必要があるため、それ以外の要因を取り除ける傾向スコアマッチングという手法を採用しています。
見事「アイテムXの使用」が継続率に与える効果が示されました!
<検証結果>
- 「アイテムXの使用」後
- 60日間継続率は約5.8%上昇
- 90日間継続率は約4.5%上昇
藤原さんのグラフィカルモデリングと効果検証のおかげで、自信をもって「アイテムXの使用」をユーザーに促すアクションが取れますね。
まとめ
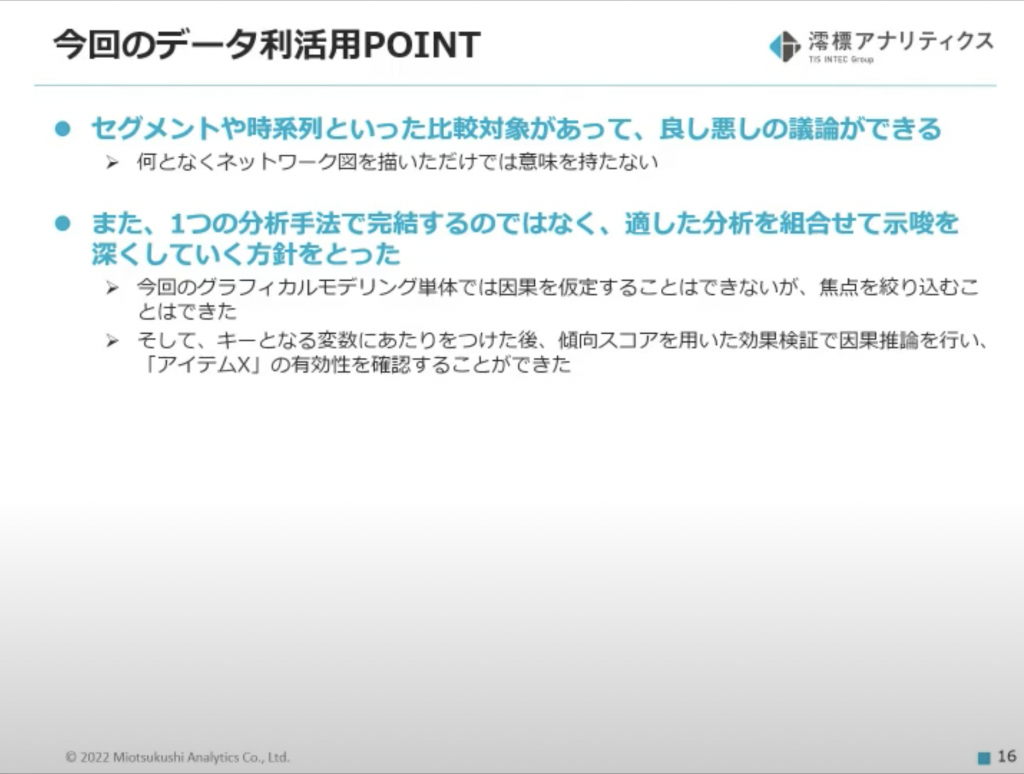
最後に今回のデータ利活用のポイントをまとめてくれました。
<ポイント>
- ネットワーク図(グラフ)は比較すること
- セグメントや時系列などで比較してはじめて評価ができる
- 適した分析手法を組み合わせること
- 変数を絞り込む手法と、その有効性を確認する手法を組み合わせると示唆が深まる
ネットワーク図を描いて、満足してしまったらそこで試合終了なんだ!と筆者の頭に刻み込まれました。
藤原さんがいろいろ複雑な分析手法を操りつつ、常に分析の目的に立ち返る姿勢にもう一度拍手を送りたいです。
藤原さん、ご登壇ありがとうございました!
(wywy 合同会社 / 遠藤 祥子)
LT4. 株式会社 G-gen 杉村 勇馬 様
「BigQueryのScheduled Queryでジョブ失敗を通知する3つの方法」
最後の LT は G-gen 杉村さんより、Scheduled Query の Tips です!
杉村さんは過去に AWS の資格を 12個全て取得。
そして今年中に Google Cloud の資格も全て取得しようと取り組んでらっしゃるそうです。。。
ストイックさに脱帽です!凄すぎます!
今回紹介していただいたのは Scheduled Query を使用する際の問題点と解決法。
Scheduled Query というのは BigQuery の SQL を定期実行する機能で、コンソール上から実装できます。
簡単な ELT 処理の実装ができる、非常に便利な機能です。
みなさんもかなり使われているのではないでしょうか?
そして、Scheduled Query には、Job に失敗した際にメールに通知を送る、 Email Notification 機能がついています。
…が、この Email Notification 機能は Job 作成者の Google Account にしかメールが来ないという仕様です。
しかし、現場的には作った人だけじゃなくてチーム全体に共有したいところ。。。
今回は、Cloud logging を使った、杉村さん流手法を紹介してくれました。

Cloud logging では、特定の文字列の出現回数からアラートを通知することができます。
そのため、Scheduled Query のエラーを抽出するためのフィルタと、「ログベースの指標」を設定しておき、任意の通知先にアラートを出すように設定すると、ノーコードでお手軽に作ることができるようになるそう!
気になる手順は、杉村さんの執筆されている、G-gen Tech Blog に丁寧に記載されているのでみなさんぜひ見に行ってください!
https://blog.g-gen.co.jp/entry/scheduled-query-error-notification
今回ご紹介いただいた手法は、既存のサービスをノーコードでうまく組み合わせていて、杉村さんの工夫が垣間見えて素晴らしいと思いました!
杉村さんありがとうございました!
(Sysmex / 増森 聡明)
全体を通した感想
今回はデータ利活用について、アプローチ、法改正、分析事例、実運用まで幅広い知見をお聞きすることができました。
振り返ってみると1時間の分量とは思えないほどのナレッジ共有がありました。
データマネジメントから、法律、行動分析にみんなが使う BigQuery の便利な Tips。
幅広い内容で事例を交えながらお話しいただけました!
前回の Lunch & Learn もそうでしたが、今回もお腹いっぱいです!
登壇者のみなさん、ごちそうさまでした。
(Sysmex / 増森 聡明)
次回開催告知!!
次回は 5/11 (水) 17:00 -19:00 での開催を予定しております。
次は「お悩み相談会」と題しまして、みなさまのデータ利活用のお悩みに対して、みんなで解決策をディスカッションしよう!という会にする予定です。
また、メンバーのみなさまの、非常に幅広い知見が飛び交いそうな予感がするので、私も今から楽しみです!
是非、予定の確保をお願いいたします!!
また、本記事を読んでいただき「参加したい!」と思っていただいた方も、このタイミングで Jagu’e’r 及び、分科会への参加、また、ご登壇大歓迎でございます。
分科会運営のお手伝いをいただける方も募集しています。
ぜひ、お気軽にお問い合わせください!