
活動報告: データ利活用分科会 第8回イベントレポート
みなさんこんにちは!2022年も終わりを迎えようとしていますね。今年はどんな年になったでしょうか?
さて、今回は先日 12/2(水) に実施されたデータ利活用分科会年末スペシャルイベントの活動報告です。今回もビジネスから研究までたくさんの事例、知見を紹介いただきました。
まさに年を締めくくるに最高のイベントになりました!ご登壇いただきましたみなさま、本当にありがとうございました!!
それでは、イベントの模様をお送りいたします!
目次
基調講演: Google / 松田様「FitbitデータソリューションとGCPの連携活用」
Groovenauts / 山本様「データディスカバリワークショップからDX活動のネタ作りなど」
Google Cloud / 山中様「5 分で振り返る Looker Studio」
primeNumber / 加藤様「マーケティングデータを全社で共有」
KINTO / 粟田様「クラウドネイティブとDBRE」
Kiara / 石井様「みんなの基礎研究 with GCP」
SIMPLEX / 泉様「データ活用することへのアプローチ」
wywy合同会社 / 遠藤様「農業用水のための水質マップ作り」
フューチャー / 村田様「Jagu’e’rのすゝめ」
アクセンチュア / 中川様「一人でも小さく始められるGoogle Cloudで実現するほぼサーバレスなデータ基盤」
所感・まとめ
次回告知!!
基調講演紹介
Google / 松田様「FitbitデータソリューションとGCPの連携活用」
今回の基調講演は Google Fitbit Team の松田さんより Fitbit と Google Cloud の連携、活用事例のご紹介になります。Fitbit といえば自身の健康データをトラックできる素晴らしいウェアラブルデバイス!自分のヘルスケアデータを常に確認することは予防の観点より非常に重要です。

「世界中の全ての人をより健康にする」というミッションを掲げる Fitbit は、なんと現在アクティブユーザーが3000万人以上!!蓄積されているデータがものすごいことになっていそうです。そんなデータを使って、新しい機能の開発も進められているのだとか。

Fitbit の特徴といえば、すでに法人利用の実績があることからの、アプリ連携の強さ、そしてもちろん Google Cloud との連携です。事業スケールの拡張性が優秀ですよね。iOS と Android の両方と連携できることから、大学・研究機関のファンも多いのだとか。
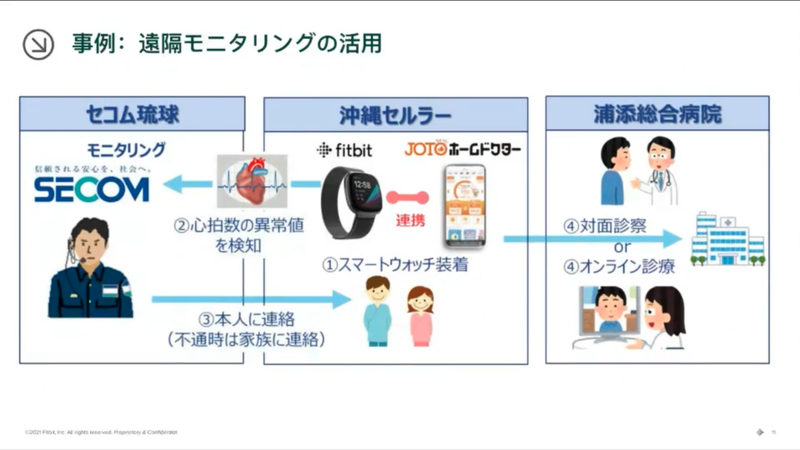
実証実験中の事例として、JOTOホームドクターの事例をご紹介いただきました。Fitbit を装着している人のバイタルに以上があった時、第三者に連絡したり、診察診療に活用をしているそうです。
地方では、一人暮らしをしている方も多いので、家族としてはこういったサービスがあると安心ですよね。
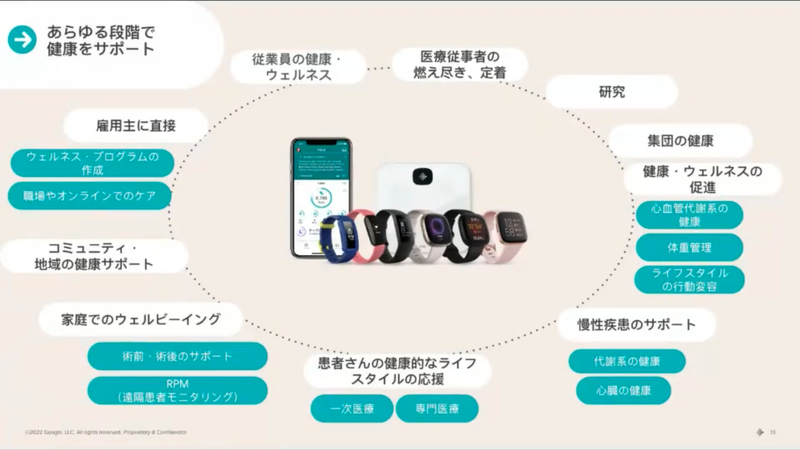
API を活用することでありとあらゆる領域で、データ利活用ができます。Fitbit だけでなく、いろんなパブリックデータや他のサービスのデータと連携して様々な価値を生み出せる。データには無限の可能性がありますね!サプライチェーン業界では、心拍数から計算式を作り、運転手の熱中症アラートシステムを作られた事例もあるのだとか。こんな無限の可能性をもつ API がフリーで解放されているのは、すごく嬉しいですね!
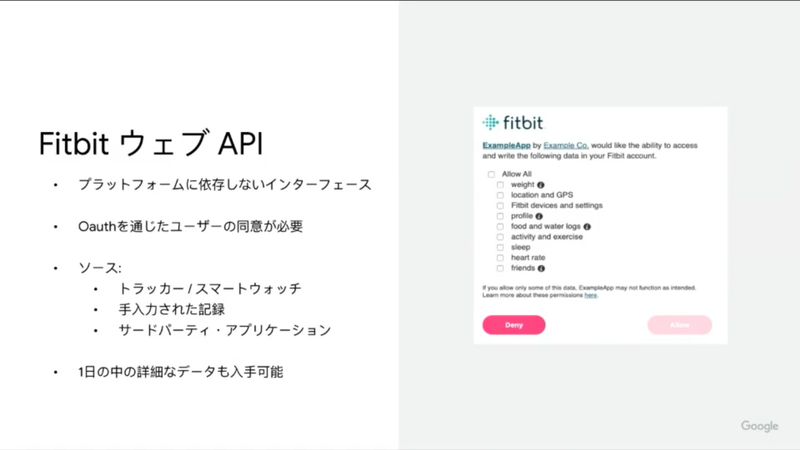
Fitbit の Open API ですが、現在以下のデータタイプをサポートしているそうです。
- 活動
- 身体
- 睡眠
- 栄養
- デバイス
- 心拍数
- 友達
- 呼吸数
- 酸素飽和度
- 心拍変動
- 睡眠プロフィール
なお、データタイプは不定期に増えているそうで、呼吸数、酸素飽和度、心拍変動、睡眠プロフィールというのは、まさに2022年に増えたデータのようです。API で取得できるデータが増えると、そのデータを使って何ができるかを考える楽しみが増えるし、そこからまた世の中に無限の価値が生まれてくるので、ワクワクしますよね!今後も注目です!

ここからは Fitbit と Google の他の技術の融合による、事業拡大について話していただきました。
健康経営はもちろん、Google Map との連携によって、災害時などの見守りサービスの構築ができたり、マーケティングインサイトとバイタルデータを繋ぐことで、その人の体調にあった情報を配信するようなこともできるのだとか。体調にあった情報を配信というのは、盲点でした。そういったユーザー満足度の向上もできるんですね。

そしてもちろん、他の Google Solution とも連携が可能です。Google Cloud、Looker、Workspace まで。特に Google Workspace で行動データとの連携はできることが多そうであると感じました。
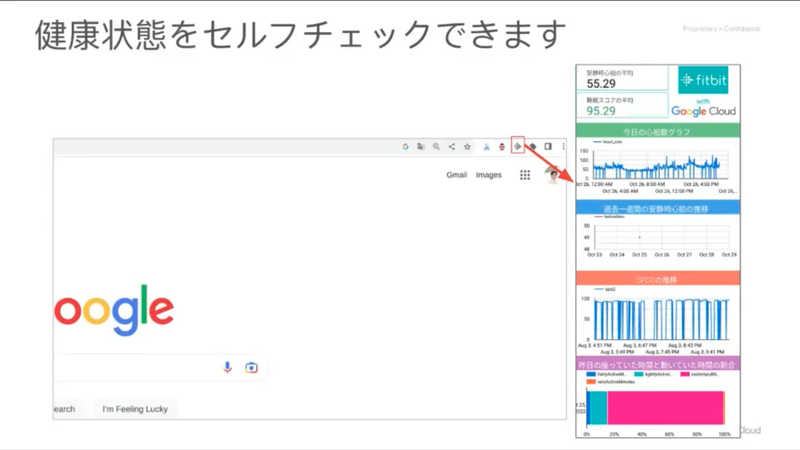
これは Fitbit の API を活用して、 Googler が作った Chrome Extension だそうです。常に自分の健康状況が見えるのだとか。一番下のカラフルなバーは座っている時間と運動している時間の割合を示しているそうです。いちいちアプリを開かず、仕事をしながら自分の健康状態をモニターできるのは素晴らしいですね!
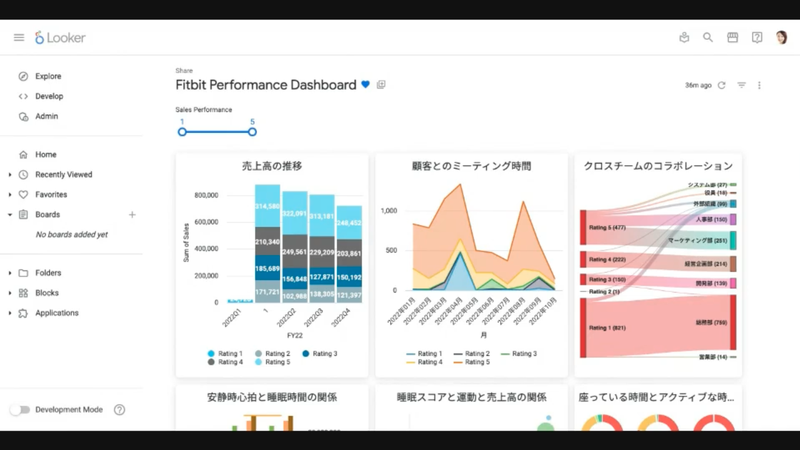
Looker を使うと綺麗なパフォーマンスボードを作ることができます。Google では Fitbit のデータと仕事の成績を組み合わせて、インタビューの質問やほかの部門とのコラボレーション、イベントの企画などに活かしているそうです。ここまで見える化、そして次のアクションに繋げられるようできるんですね。Fitbit や Workspace のデータはもちろんですが、こうして見やすいダッシュボードを作れる Looker も、ステキですね。
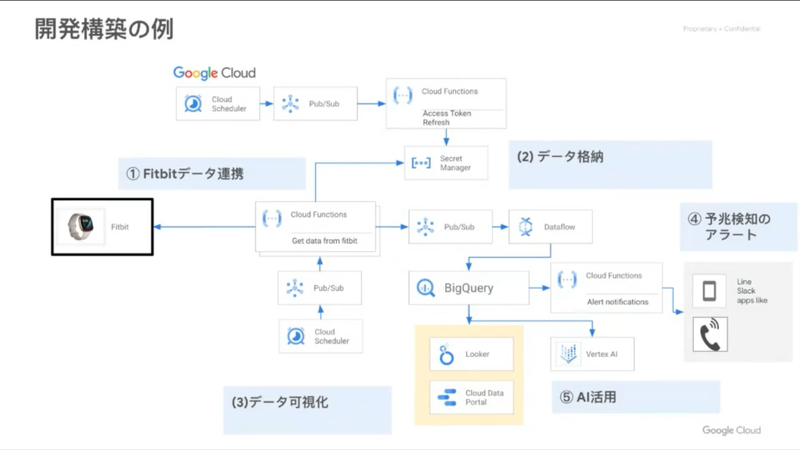
みなさん、お待たせしました。開発構築の例として、アーキテクチャ図の登場です。データ連携、格納はもちろん、 Vertex AI によって AI 活用までできる。。。Google Cloud 上でここまでできるのが素晴らしいと思いました。

最後に、Fitbit と Google Cloud をつなぐ、専用のコネクタがリリースされたそうです!Google のテクノロジーがこれでもっと使いやすくなるそうです。well-beingが大きな注目を浴びる中、そして DX が叫ばれる世の中において、こういったバイタルセンシングができるデバイスは、間違いなく今後のインフラの一つになるであろうと、私自身確信しています。
本公演を聞いて、私も早速 Fitbit をポチッとしてしまいました。年末は Fitbit API を使って遊び、休みの間に一つ、何か作ってみる予定です!
なお、Jagu’e’r では、最近立ち上がったヘルスケア分科会に、本公演のスピーカーである、松田さんが筆頭になって、Fitbit 部を作ることが確定しています。みなさんと、Fitbit の活用に関して、たくさんディスカッションがしたいです!ご興味ある方は、ぜひそちらにも参加をお願いいたします!
(ヘルスケア分科会の参加はこちら)
松田さん、ありがとうございました!
(シスメックス株式会社 / 増森 聡明)
LT 紹介
Groovenauts / 山本様
「データディスカバリワークショップからDX活動のネタ作りなど」
LT一人目はGroovenauts の山本さんの発表です。
主に、分析技術、ハードを持ち、DX推進のサポートを実施している企業様になります。

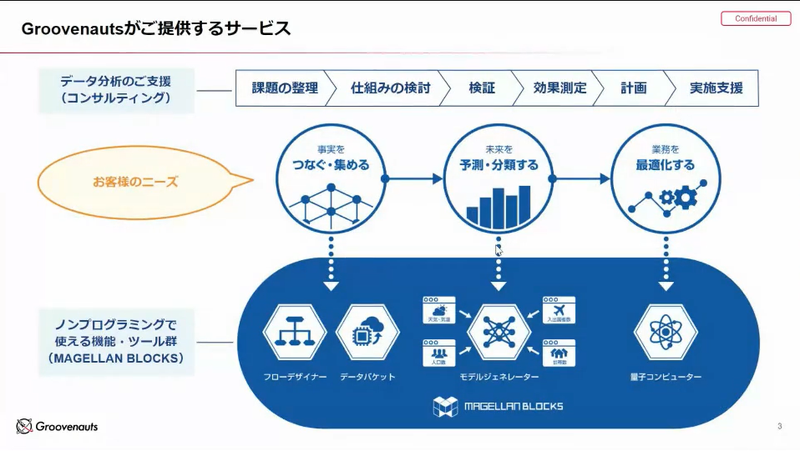
Groovenauts様は、福岡に本社があります。
GCPで動くMAGELLAN BLOCKSを提供している企業様でAIと量子コンピュータのプラットフォームになります。同時にTECHPACKという形で子供たちにAIを啓発するお仕事もされているそうです。

何を解くべきかどこから解くべきかが課題。解こうと思ってもデータがないなどいろいろな問題があります。やりたいことを実行することが最も難しい。
山本さんは、ベンダー様に丸投げすれば解決するということではなく、一緒に悩んでくれるようなプレイヤー様だと取り組みやすいと仰っています。
たしかに、自分の仕事に絡む解決策の勘所は実務担当者が深く入り込まないと本質的な解決策は生まれないですよね。
DXといっても、現場の社員側はデータ分析といっても決まったスプレッドシートを見るくらい。一方で技術者、DXチーム側は現場で起こっていることが遠くて、何を解決したらいいかわからない。よくあるあるあるですね。「連携が取れていないことが問題」と捉えます。
何をやったらいいのかというコア人材の育成は必要なんですが、現場側にもデータって意味があって、使い物になるよという啓発も同時に必要なわけです。たしかに、DXを標ぼうすると現場の課題がわからずちぐはぐするということは経験あります。
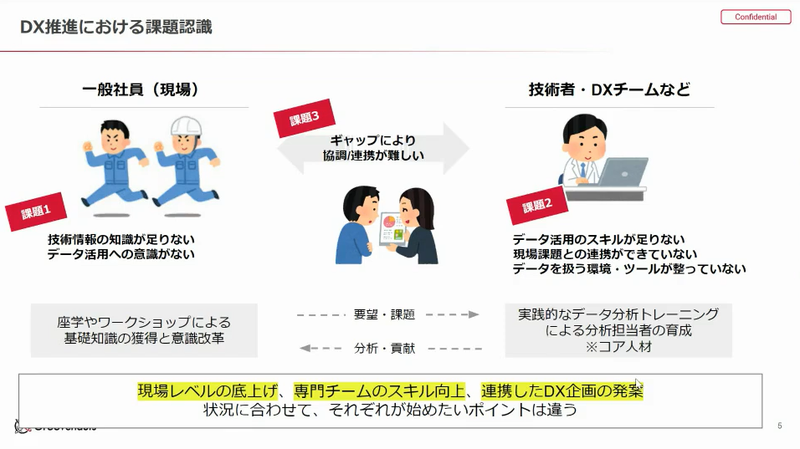
DXは、現場の人に認められないと活動が認められません。またデータを押し付けられて、協力を依頼されても何を解決したらいいかわからない。このあたりの協調性を作っていくことが大事ということになります。

Groovenauts様では、データワークショップの開催を企画しています。データを並べてみて、データがあったらどんなことをやってみたいか、議論するワークショップをやっています。
データがあったら解決できるというアイディアの卵のようなものを産み出す機会になります。
私も受けてみたい!!

実際にやっている姿です。
データを直に見ていると発想が固まる傾向になるので、データを使える課前提でどんなことができるかということを討議します。
画像は、福岡のインキュベーション施設のようですが、まさに学校でグループワークをやっているという感じですね。隣のチームからカードを奪いにいったり、スパイ制度といいます。

このワークショップでこんなことがやりたいということができたら、PoCを組んでいろいろなことをやってみる。これをやりながら、後ろの基盤を作っていくという形にしていきます。
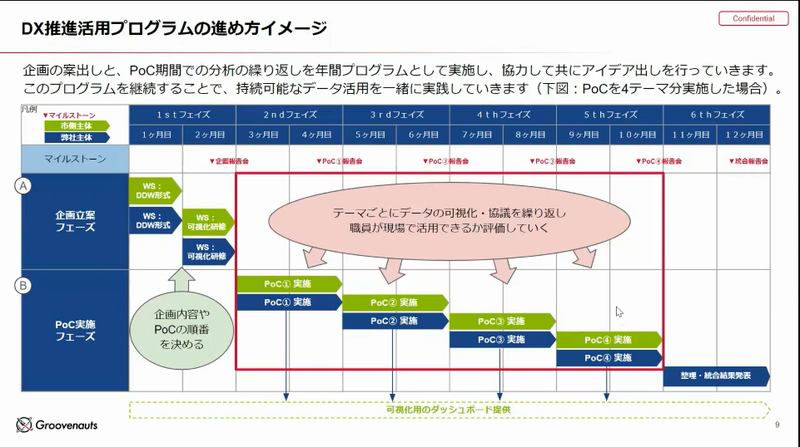
DX 推進はまずシステムを作って、データウェアハウスを作れば万事 OK という話はあります。しかし、実際には、中に入っているデータで成果を出し続ける仕組みこそが大事です。
スモールスタートでデータを区切って、成果を出し続けていく。ネタ切れになってきた時にワークショップをやって、アイディアを出してみるということをやっています。
ワークショップ形式でアイディアを出していく。
正規なシステムを作っていくことよりも、楽しみながら進めることで、PoCを回す。このような営みを継続していくことが大事と考えています。
とっても、興味が持てました。私たちもやってみたいです。
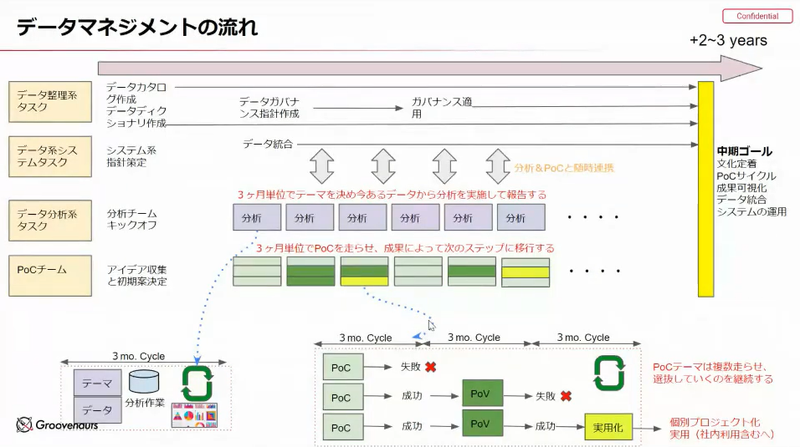
データの利活用は、本格敵なシステム構築も大切ですが、小さな解決策でもよいからやりたいこと、やれることを整理しながら、継続的に成果を出すことが大事という山本さんのお言葉が最も心に刺さりました。
以前にGroovenotes様と一緒にお仕事をしたことがありましたが、会社の垣根なく、私たちの視線に沿って親身に解決策を提案して頂けたことが最も取り組んでよかったと思った瞬間でした。
私からもGroovenauts様を強くお薦めしたいです。
(ライオン株式会社 水谷昌史)
Google Cloud / 山中様
「5 分で振り返る Looker Studio」
LT二人目は、Google Cloudの山中さんの発表です。
Google Cloudご活用の方は、Looker Studioは一度は触ったことがあるのではないでしょうか。

山中さんは、グーグル・クラウド・ジャパンでパートナーエンジニアをされています。

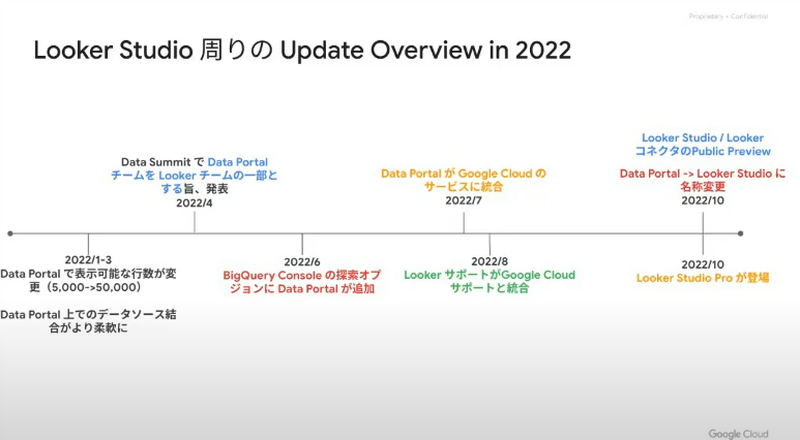
2022年のLooker Studioは、他のサービスと統合した年でした。
2022/4のデータサミットでData StudioのチームがLookerのチームと統合されることが発表されました。Data StudioはGoogleの製品であり、Google Cloudの製品ではなかったため、パートナーさんが異なったり、再販できなかったりということがありました。
2022/7にGoogle Cloudのサービスに統合されることが発表されました。2022/10にData StudioがLooker Studioに統合され、加えてLooker Studio Proができました。
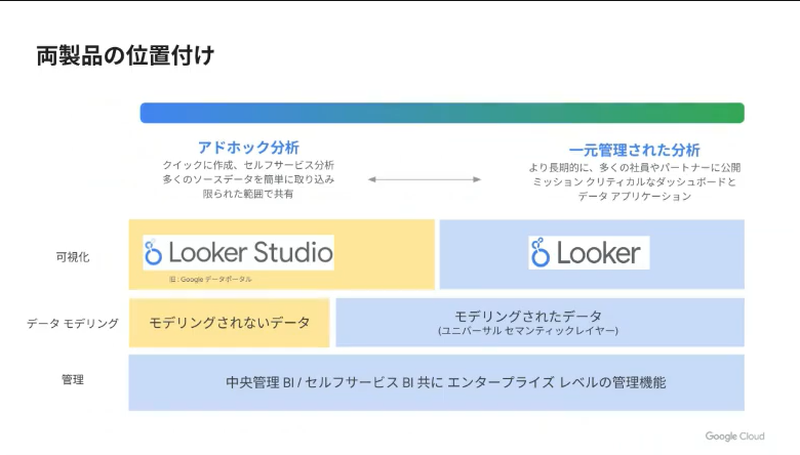
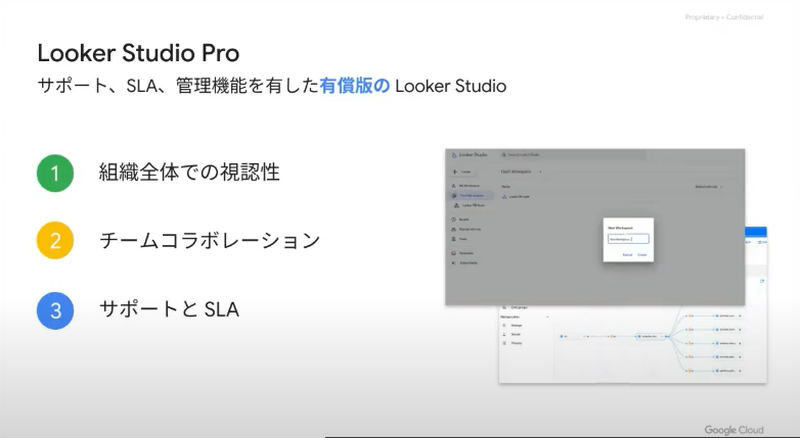
Looker Studio(日本ではデータポータル)と有償版のLooker Studio Proの2製品になります。企業で採用するためには、必要となってくる管理機能とサポートが加えられています。
LookerとLooker Studioは競合しないような構えになっています。

ガバナンスを重視する場合は、Looker、フランクに可視化したい、アドホックに分析する場合はLooker Studioを使います。弱いところを補完しあう製品ということになります。
Looker Studioは個人で使う分には問題ないんですが、Looker Studio Proでは、ガバナンスだったり、コラボレート機能、サポート管理系の機能が充実されています。データソースが何かも確認できます。
まとめは以下になります。

結論の使い分けに関して、
手軽に始めてみるのはLooker Studio、ガバナンスの問題に直面するので、その場合は、徐々にLookerのほうに発展させていくという流れになります。
Google CloudのBigQueryを活用できるということで、Lookerの強靭さ、手軽に使えるLooker Studioに加えて、Looker Studio Proで企業向け対応もしてくれるということでどんどん期待感が増します。
Looker Studioの手軽さは強みと思いますので、どんどん使っていくきっかけになります。
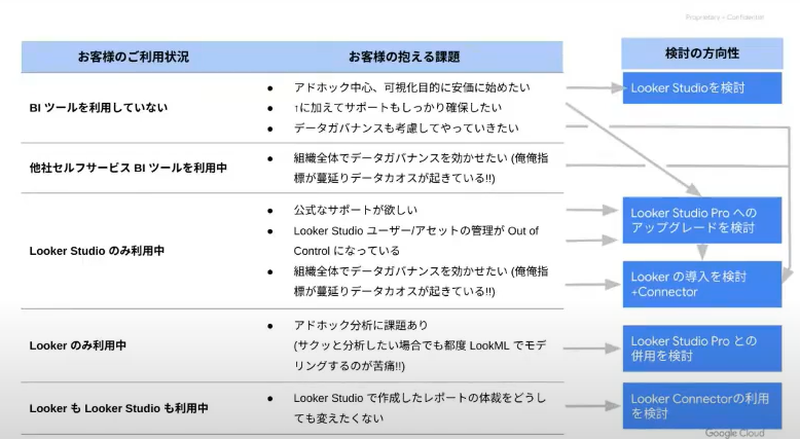
なお今後は、「基本な検討方針としては、データ活用においてデータガバナンスが重要になるケースが多いので、Lookerをご提案することが主軸となりますが、お客様の制約(コスト・利用範囲)などを踏まえ、Looker StudioやLooker Studio Proを必要に応じて検討する。」そうです。
ありがとうございました。
(ライオン株式会社 水谷昌史)
primeNumber / 加藤様
「マーケティングデータを全社で共有」
LT三人目はprimeNumberの加藤さんの発表です。


primeNumberさんといえば、SaaS型ETL/ELTのtrocco®でご存じの方もいらっしゃると思います。
ETL/ELTとは、さまざまなデータソースからデータを抽出(Extract)、変換(Transform)、ロード(Load)するデータフローをあらわします。その処理の順番によって、ETLだったりELTと表現するので、決してEve*y Lit*le Thi*gのことではないです。
そんなサービスを展開しているprimeNumberさんですから、もちろん社内のデータ利活用をされているということでお話いただきました。
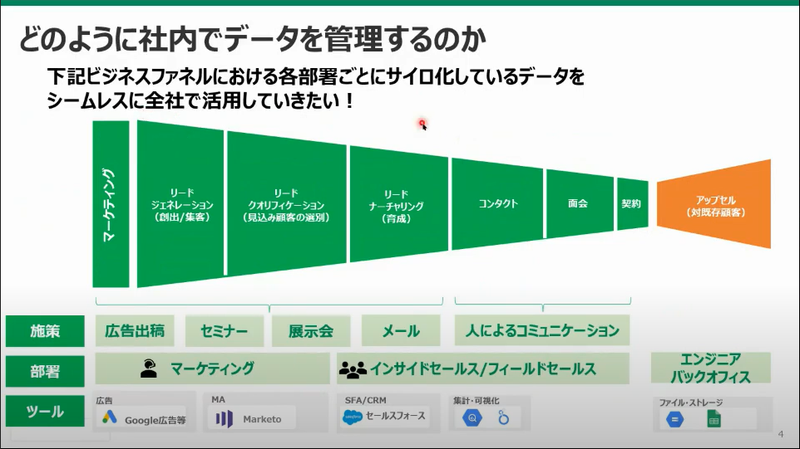
加藤さんの会社の場合、マーケティングデータが様々な部署やツールが収集しているそうで、それらの各部署が集めてサイロ化しているデータを全社で活用したいというニーズがあるそうです。
「あるある、ウチの会社もそうだよ」という声が聞こえてきそうですね。

また、データを利用するにあたってもいくつか課題があるそうで、欲しいデータが一部欠落しているとか、データの取得元が分散しているので、意味のある形で見える化するには、いろいろな加工が必要、かつどのような形で見せるのがいいのか?というような課題です。
これまた「あるある」な感じですね。
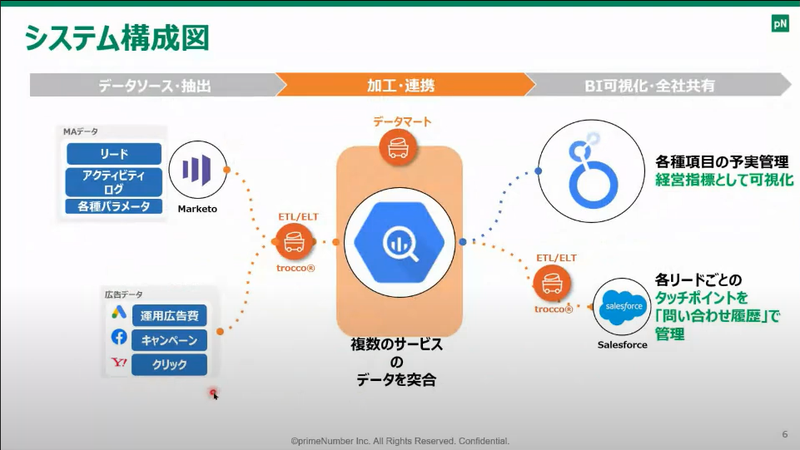
もちろん、そういった課題を解決しやすくするのが、ETL/ELTツールの得意とするところとなので、加藤さん達はtrocco®で様々なマーケティングデータを集めて加工して、trocco®からBigQueryにデータマートを自動作成しているそうです。
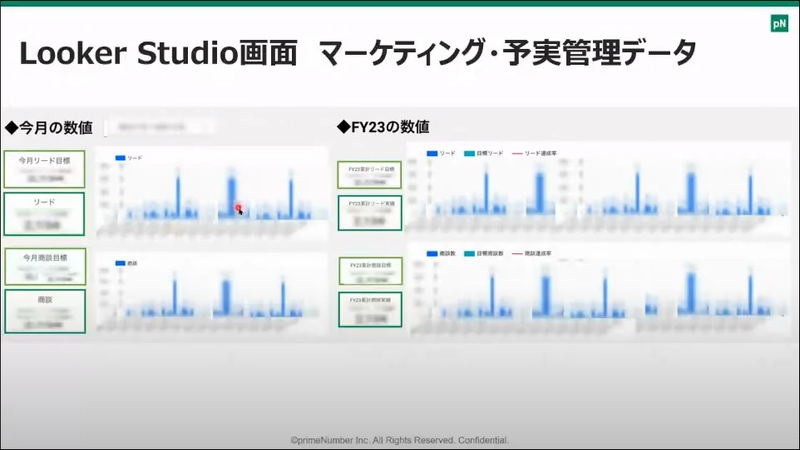
そのデータマートの内容を経営指標としてリアルタイムで更新してLooker Studioで可視化したり・・・
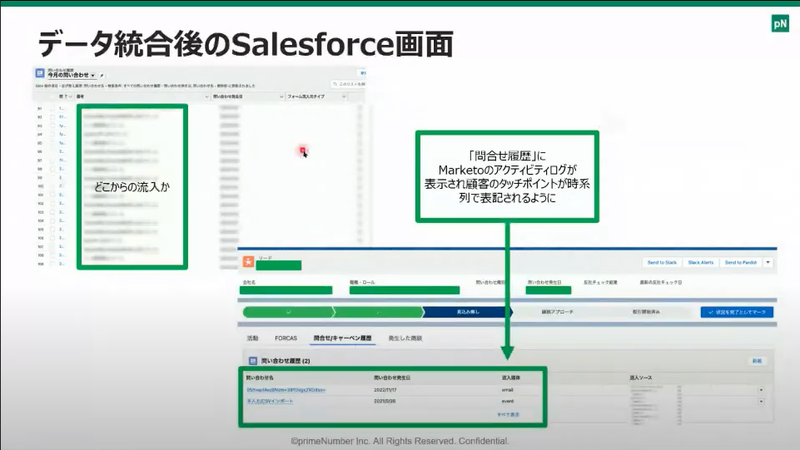
さらにtrocco®で加工したデータをSalesforceのオブジェクトとして転送して、お客様からのリードごとに問い合わせ履歴が参照できるようして、全社でマーケティングデータを利活用できるようになっているそうです。
分散したデータを集約して全社利用出来るように、自社サービスをうまく使いこなしているのは「さすが」という内容のお話でした。
(株式会社エヌデーデー 関口貴生)
KINTO テクノロジーズ / 粟田様
「クラウドネイティブとDBRE」

続いては「Jagu’e’rリーダー」を任命されているKINTO テクノロジーズの粟田さんです。粟田さんはCCoE研究分科会では、SG(Secretary General)をされていたり、Jagu’e’rメンバーが参加しているSlackでも積極的に発言や、情報提供してくださる人です。所属されている会社ではDBRE(Database Reliability Engineering)の部署を担当されているとのこと。
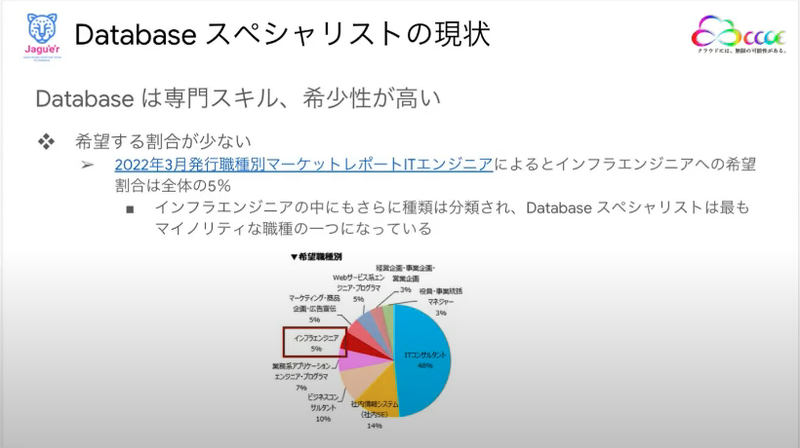
粟田さんがはじめにお話してくれたのはDatabaseスペシャリストは専門性や希少性が高いということでした。
それというのも「ITエンジニア」の中で「インフラエンジニア」を希望する人が全体の5%、その中でもDBAやデータベースエンジニアを希望するというような人はさらに少ないということだからだそうです。
確かに「インフラエンジニア」と聞くとネットワークスペシャリストとか、サーバーOSの分野のイメージが強いので、データベースに関わるというイメージは少ないかも知れません。
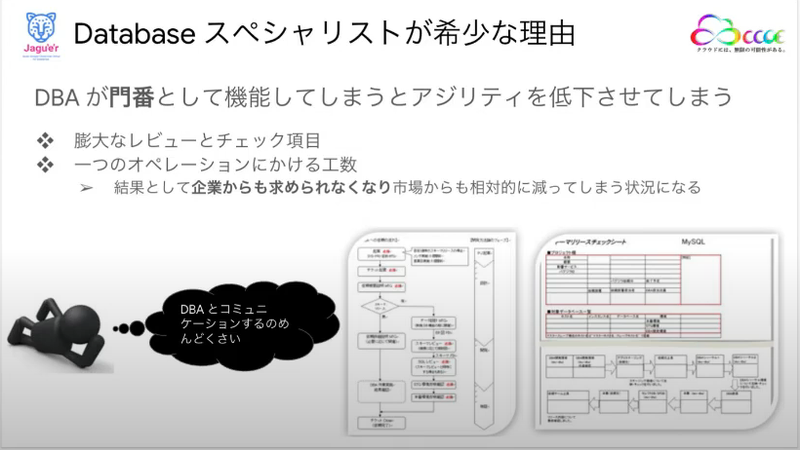
そして、もう一つDatabaseスペシャリストが希少になる要因として挙げていたのが、クラウド時代になったことにより、単なる門番としてのDBAはビジネスのアジリティを下げてしまうために、求められなくなるからだという事でした。
みなさんも、アプリケーションの開発や更新をしていく時に、DBAにテーブルの項目追加や変更をお願いすると、レビューやチェックに多くの時間を割いたという経験があるのではないでしょうか?
私もアプリ側、DBA側両方の経験があるのですが、アプリ側にいるときには「じれったい、めんどくさい、早くして」と思いましたし、DBAの立場だと「他のアプリとかパフォーマンスに影響ない?この列の追加ってほんとに必要?」という感じでしっかり見なきゃいけないという責任感を感じていたので、じっくり調べなければと思った経験があります。

さらにもう一つ、このクラウドというキーワードに関連していきますが、マネージドサービスを利用することで今まで管理・運用していかなければならなかった事から解放されて「DBAっているんだっけ?」という考え方も出てきていることも希少性を高める要因になっているのだろうと考えているそうです。

とはいえ、事業を継続的に成長させるためには、やはりDatabaseスペシャリストは重要であり、これまでデータベースという単なる「ハコ」を管理するという役割を超えて、今の時代は事業を守るためのより大きな4つの視点を持つべきだろうと粟田さんは考えているそうで、そのうち2つについて話していただきました。
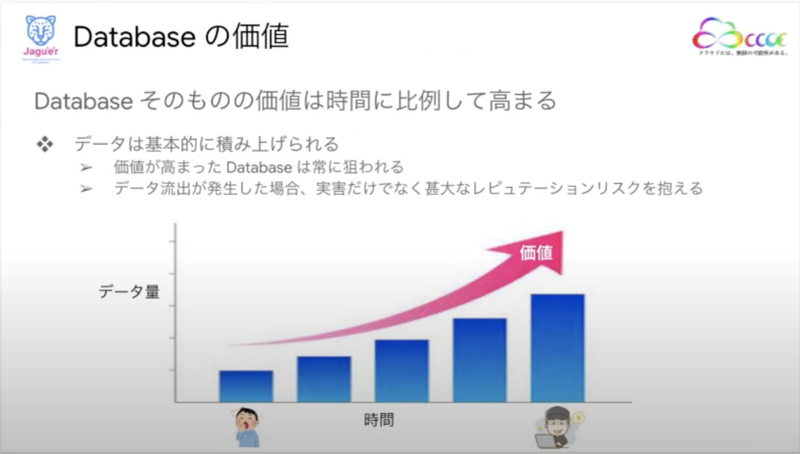
1つ目は「データを正しく守る」
データベースに蓄積されていくデータは、ほぼ消されることがないため、時間が経過とともにその価値が上がっていきます。そうして、価値の高くなったデータは攻撃者から狙われる可能性が高くなるため、流出などしてしまうと事業に大きく影響してしまいます。
そのような事態を招かないようにデータを正しく守ることがDatabaseスペシャリストの大きな役割だと考えているそうです。

2つ目は「外的要因の変化に追従する」
外的要因とは、例えば3年おきに改正される個人情報保護法の罰則規定や、GDPR、今年に入ってからは戦争に伴うセキュリティリスクの増大など、企業自身ではコントロールできないものです。
外的要因は時代に伴い変化するため、それらに応じて事業とデータを守るという対応がDatabaseスペシャリストのもう一つの重要な役割だと考えているそうです。
こういうことはセキュリティエンジニアの仕事というイメージだったのですが、DBREにとっても重要な役割だったのですね。
そのように考える中で粟田さんが目指すDBREの姿とは?

サービスの持続可能性を上げることや、アプリケーションエンジニアの生産性を上げることに寄与するような活動を続け、その結果として、ビジネスにいい影響を与えることできてこそDBRE組織の価値が提供されると考えているそうです。
「そこにあるだけでは何に使われるか分からない税金と同じ」というフレーズは、同じく横断組織に所属する私も襟を正さなければと思うものでした。

ここまで粟田さんが説明してくださったように、事業のスピードを落とさないように、さまざまな課題に現場のエンジニアとともに対応しなければならないと考えたときに、DBREという選択が重要になってくるのですが、それに伴ってDatabaseスペシャリストに求められるスキルの幅も大きくなってきているそうです。
しかしながら、個人でできることにも限界はあり、事業に対して価値の提供ができないケースも出てきてしまうそうです。
それにはどうしていけば良いのか?
粟田さんの解としては「周りの全ての力を借りる」ということでした。

自分の得意な分野を伸ばしていきつつ周りに還元しながら、同時に周りの力を借りながら周辺知識も少しずつ蓄えていき、その結果価値を提供し続けることを考え続けるということだそうです。
「周り」というのが、社内の協力者に止まらず、Jagu’e’rなどのコミュニティにも拡がっているのがポイントですね。
また、このスライドでは「自ら周りに還元し」「価値を提供する」という粟田さんの Give first の精神が現れている内容だなと感じました。
今回の発表では、DBREという立場でのお話でしたが、それに限らず同じような組織に所属している者として、大変参考になるお話でした。
(株式会社エヌデーデー 関口貴生)
Kiara / 石井様
「みんなの基礎研究 with GCP」
さて、お次は Kiara Inc. の代表取締役!石井さんからのご発表です。石井さんは自称数学オタクで、たくさんの AI 関係の本を共著として執筆されている方です。今回のテーマは「安い、速い、儲かる」な基礎研究で発表をいただきました。
基礎研究といえば「高くて、遅くて、儲からない」を想像する方が多いと思いますが、「安い、速い、儲かる」な基礎研究とはどう言ったものなのでしょうか?

現在は、データパイプライン作り、数理モデルを加えて、自社で、ヘッジファンドに活用されているそうです。9兆円…なんかすごそう。

「何をやってきたか」について話していただけました。なんと 26種類の手法比較、ABZ テストを実施してきたそう。何が最適手法かわからない時、トライアンドエラーを繰り返す際、いくつかの手法を比較することはありますが、26種類はすごいですね。そして、それを MVP をさらに小さくしたもの。ミニミニミニ MVP 最終的には数式の種類のレベルまで落とし込んで実施検証を回されたそう。これも面白い考え方だと思います。比較に足るレベルの粒度感でたくさんの手法を比較するのは非常に効率が良く、試行回数を稼げるという点で合理的だからです。私も参考にしよう…!!

技術スタックとして、BigQuery, Looker、アプリ化にノーコードが使用されているところから見ても、やはり、PoC のアジリティを大事にされていることがわかります。今後はみんなのアイドル、Looker を推していこうとしているそうです。
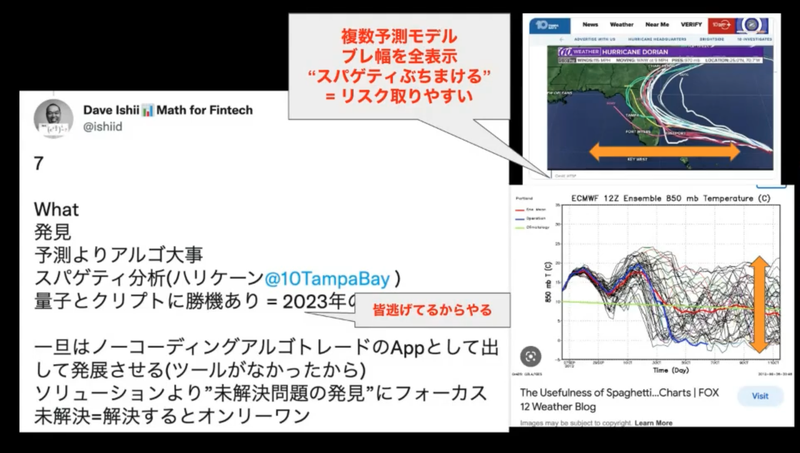
たくさんの実施検証から、金融は予測できないものであり、アルゴリズムが重要であるという知見を得たそう。天気の予測にスパゲティ分析というものがあるそうですが、それが意外と使えるのではないかと考えているそうです。

石井さんが日々とられている手法についてです。
一日にアウトプットを出すため、低い山を選択する戦略を取られているそうです。良かったものは10倍にし、悪かったものは真逆の戦略をとるのだとか。低い山を選択するという戦略をとり、毎日アウトプットを評価するという点はもちろんですが、悪かった場合は真逆の選択を取ってみるという点が、仕事術的にも面白い発想だと感じました。

「基礎研は楽しいし、新規性を出すのが簡単に/なった」と石井さんはいいます。また、「数学は証明すれば良い。他人に認められる必要がないからメンタル的にも安定する」とおっしゃっていて、本当に数学が好きなんだなと思いました。
来年は数学がまだまだ浸透していない分野もたくさんあるらしいので、そちらも実施してきたいと考えられているそうです。石井さんからは今後も、楽しそうに数学と戯れる話をお聞きできそうで、ワクワクしますね!ご発表、ありがとうございました!
(シスメックス株式会社 / 増森 聡明)
SIMPLEX / 泉様
「データ活用することへのアプローチ」

SIMPLEX の泉さんよりデータ利活用のアプローチについて LT いただきました。SIMPLEX さんは SI, AI, コンサルの会社を持っており、まさにビジネスそのものがデータ利活用ですね!泉さんはプライベートでは毎年全豪オープンに応援に行くほどのテニス好きだそうで、審判ライセンスまで取得し、近々審判デビューされるそうです。
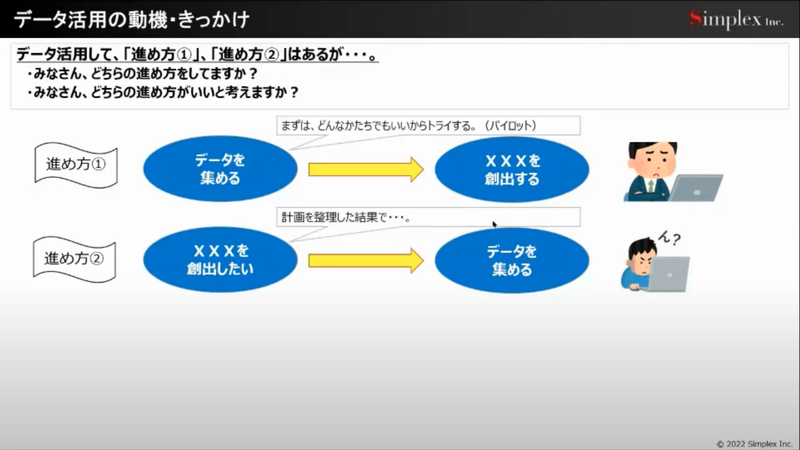
さて、今回はデータ利活用についてのアプローチ、ソリューションと成功事例の上手い使い方についてお話いただきました。まずはデータ活用に向けては2つの進め方があります。それはデータを先行して集めるか、それともビジネス主導で必要なものを集めるかです。みなさまも、片方、あるいはこの両方を経験したことがあるのではないでしょうか?
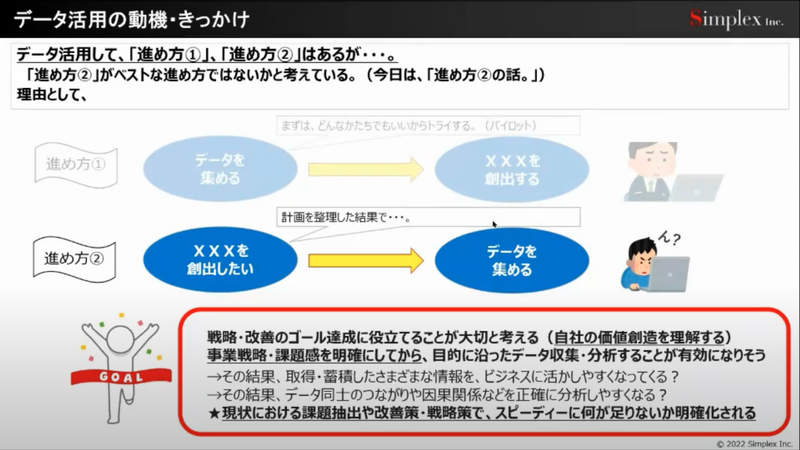
もちろんどちらが正解ということもなく、ただ、進め方②の場合においては事業のビジョンを明確にした上で、目的を達成する上でデータを収集分析する方が、もちろん成功確率は高いようです。
しかしながらよくありがちなのが、アジリティに欠けるという点だと思います。そのため、課題抽出や改善策、戦略策をスピーディに行い、何が足りないかを明確化しながら行う必要があります。

明確化においては5W1H を定義し具現化し、見える化していくことが重要だそうです。当たり前のことですが、ちゃんと機能しているところも実は少ないように思います。意外としっかり考えると、当たり前の話でも深いですね。
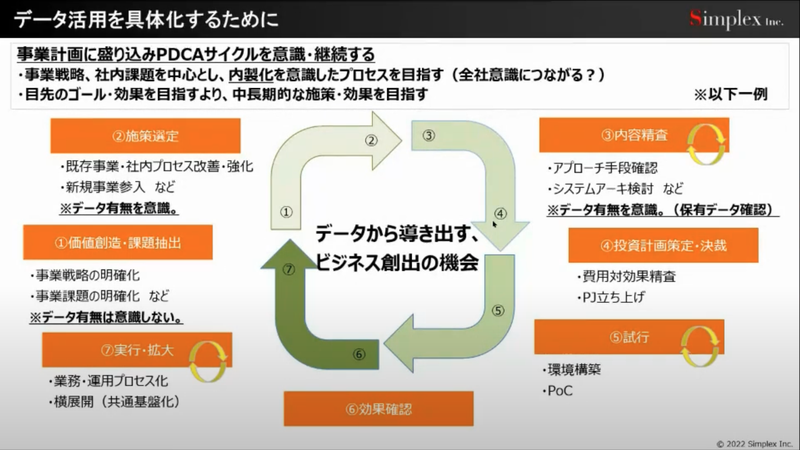
そしてデータ利活用においてももちろん PDCA に立ち返ることが重要だとお話いただきました。特に、目指す姿、理想に対してどのくらいギャップがあるのか、何が足りないか、アプローチの手段は何かについて分析し、合意形成を実施していくことが重要です。ゴールに対して、あと何が必要なのか、何にチャレンジする必要があるのかを明確にし、日々のアクションに落とし込んでまたフィードバックするというサイクルを、可能な限り早く実施していくことが重要ですよね。

もちろん、環境や案件によっても異なりますが、ゴール設定から足りないものを分析しデータ収集、活用を実施することが成功の鍵であるとお話いただきました。
計算リソースや記憶リソースが膨大かつ安価な現代、「データを先に収集して、新たなビジネス創出に繋げる」という考え方が、時代にあっていると思っていました。しかし、ビジネス創出のためにデータを集めるというアプローチの効率の良さ、無駄のなさは、仕事の進め方の上で、原点に立ち返ったような感じがして、なんだか考えさせられました。泉さん、ありがとうございました!!
(シスメックス株式会社 / 増森 聡明)
wywy合同会社 / 遠藤様
「農業用水のための水質マップ作り」

徳島県の農業でデータの利活用ができないかというLTで、wywy合同会社の遠藤さんの発表です。
実はこの日登壇されていたKiara Inc. の石井さんが執筆された本の中に、前職のプログラミングスクールのお話が掲載されていたとのことで、出版された後に生徒さんが増えたというエピソードがあるそうです。意外なところで人のつながりがあるものですね。
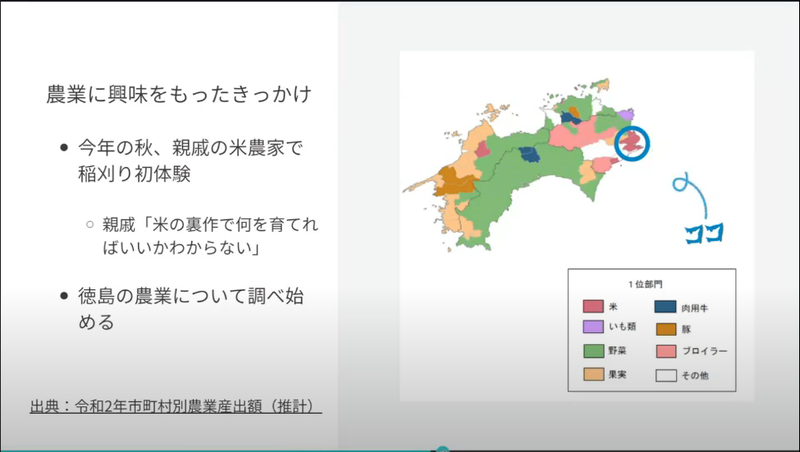
遠藤さんが農業に興味を持ったのは、親戚の米農家での稲刈りがきっかけだったそうです。
こういった体験はデスクワークばかりしていると見逃しているような気づきを得られるので貴重ですね。
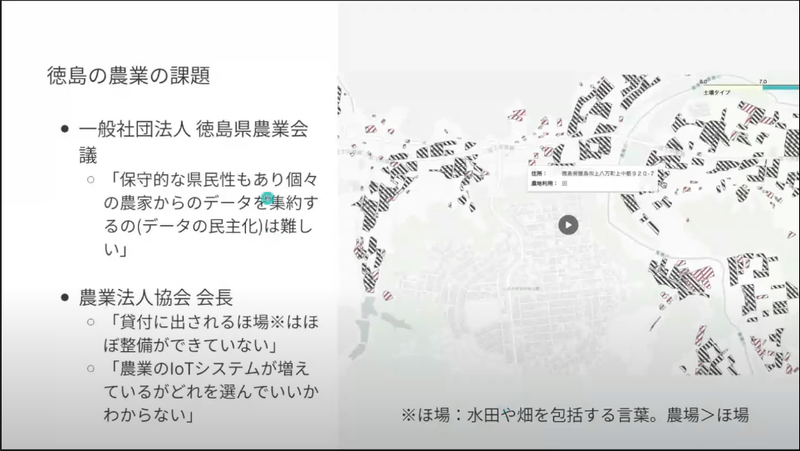
この体験をきっかけに徳島の農業従事者にインタビューをはじめたそうで、その特徴は大型の農場がなく小さな農家・農地が点在しているとのこと。遠藤さんは点在している農家さんからデータを集約するということを目指すのですが、徳島の「保守的な県民性」からデータの民主化は難しいのではないか?という意見もあったそうです。
なるほど、このような農業に関わるようなデータ収集などでは、特にその土地の文化的背景にも考慮が必要なんですね。
一方、隣の高知ではうまくいっているらしく、遠藤さんは「徳島でもデータ利活用やりたい」と思うようになったそうです。
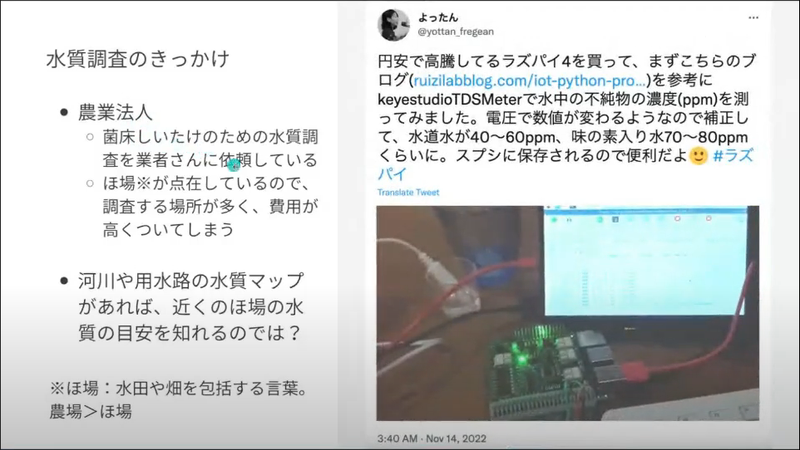
そんな中、菌床しいたけを栽培しているある農業法人から、しいたけを栽培している場所(ほ場)の水質調査の費用が高いというお悩みを相談されたそうです。
費用が高くなるのは、点在して場所も多い”ほ場”と調査を外部業者に依頼しているからとのこと。
そこで、遠藤さんは”ほ場”の近辺の水質マップを作れば役立てられるのでは?と考え、Raspberry Piで水質調査ができる装置を作ったそうです。
遠藤さんはさらっとお話されていましたが、そもそも現場に赴かれないとこのような発想は出てこなかったのは?と推測します。フィールドワークって大切だなあ。

Raspberry Piでは、TDSメーターと小学生の理科の実験でも利用する水質調査セットで7箇所の河川/用水路を調査したそうです。
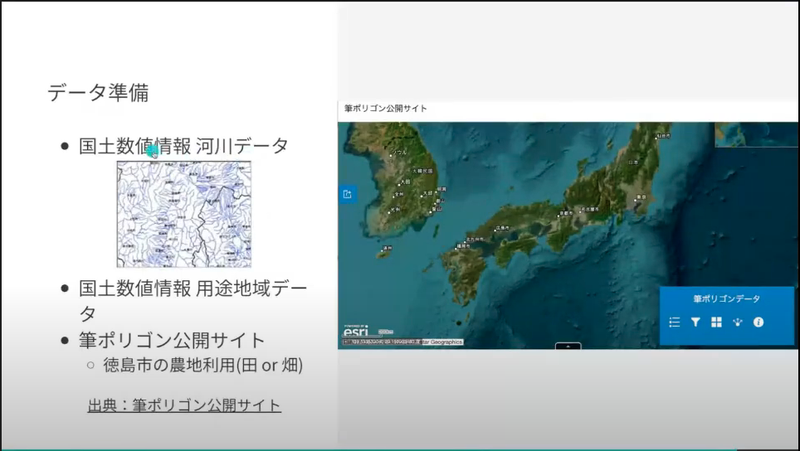
それから、各種オープンデータも用いたそうです。
筆ポリゴン・・・気になる名称なので調べてみました。
農地に限らず土地を数える単位を「筆(ひつ)」と呼ぶらしく、「1筆(いっぴつ)」「2筆(にひつ)」と数えるようです。はじめて知りました!なお、筆ポリゴンの場合は「ひつぽりごん」ではなく「ふでぽりごん」と呼ぶようです。(URLから筆者推測)
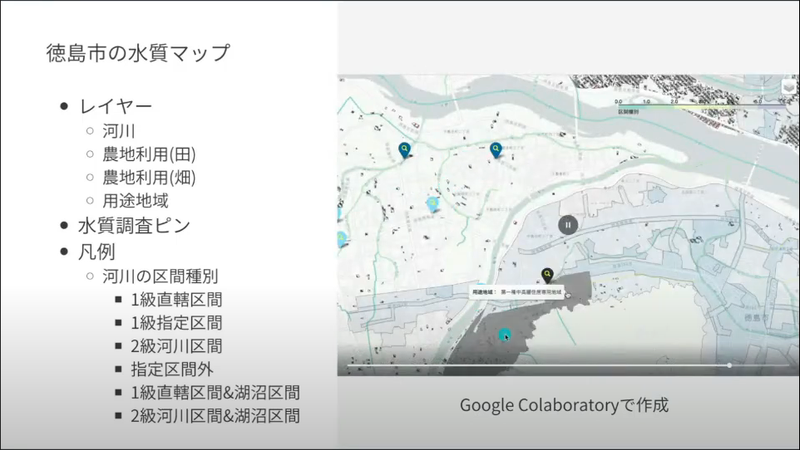
それらを組み合わせて図のような地図をGoogle Colaboratoryで作成したそうです。
地図上のピンをクリックするとその場の水質の数値がわかり、ピンの色でも水質汚染の濃度を示しているそうです。
その他、用途地域のマップを重ね合わせたりすることで、その地域が商業地域なのか住居地域なのかなどがわかるようにしており、商業地域が近いところの水質は良くないというのが地図上からわかります。
素晴らしい。
遠藤さんはこれからも調査箇所を増やしていき、水質マップを充実させていきたいそうです。
発表の最初に遠藤さんは「個人的でごく小規模な取り組み」とお話していたのですが、これまでデータを活用するという考えがなかった場所での取り組みは、決して小規模ではなく大きな活動の一歩なのではないでしょうか。これからも頑張って欲しいです。
(株式会社エヌデーデー 関口貴生)
フューチャー / 村田様
「Jagu’e’rのすゝめ」
続いては、Jagu’e’rの新星、やっさんこと、村田さんの登場です!
冒頭で「気楽なセッションです」と断りつつ、圧倒的な熱量のセッションでした。

まずはやっさんの自己紹介です!
ポッドキャストのパーソナリティ、すごいですね! 気になります。
そこからの一発目のパンチ!
「すゝめと書いていたのだけど、愛を伝えたいと思いまして、、、」

どストレートすぎて、筆者(秋元)は笑いを堪えることができませんでした。やっさんの人柄を知っているからこそ、なおのこと、愛に溢れているなーと感じました。
そして、そこからのパンチ2発目!
「愛が伝わりづらいので、題名変えます!」
ええww

この当日の熱量を一人でも多くの人に届けたい、、、と筆者も必死ですw
やっさんも、Jagu’e’rへ参加した当初は Read Only でした。いまはJagu’e’r Evangelist でとして大活躍いただいていますが、その転機はデータ利活用分科会への運営メンバー参加でした。デジタル・クラウド人材育成分科会が開催していた Study Jam #1 でJagu’e’rの熱量に惹かれたやっさんは、2022年6月に晴れてデータ利活用分科会の運営メンバーとなります。
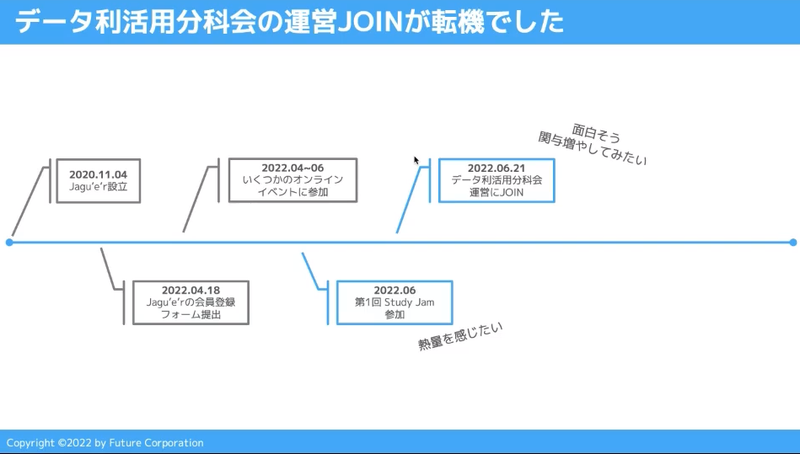
筆者(秋元)は、やっさんとの接点が多く、まだ分科会運営への参加から半年(2022年12月現在)とは想像していませんでした。データ利活用分科会や Jagu’e’r エバンジェリスト会議など、今では毎日のように会話しています。新しく参加された方でも、Jagu’e’r ではすぐにヒーローになれます!
また、いろいろな方から Study Jam が人生の転機となった、というお話を伺います。これは運営している立場(※デジタル・クラウド人材育成分科会運営も兼務)としては、嬉しい限りですよね! これからも、Jagu’e’r を通して、新しい熱量に溢れた出会いの場を作っていきます!
その後、ハイブリッド開催のイベントで、楽しい現場へのめり込んでいきます。CCoE 研究分科会やサステイナビリティ分科会のハイブリッドイベントで、渋谷オフィスへ集まり、他の Jagu’e’r 会員と交流する日々を楽しんでいたら、Jagu’e’r エバンジェリストにもなりました、とのこと!

ちなみに、筆者(※ Jagu’e’r エバンジェリストも兼務)から、やっさんを Jagu’e’r エバンジェリストに推薦した背景としては、デジタル・クラウド人材育成分科会運営にて、Jagu’e’r エバンジェリスト制度のもととなるアイデアを議論していたときに、人一倍熱心に議論に参加されていました。やっさんの興味関心がフィットしていることが分かっており、またその類まれな熱量に魅了されました。相変わらずの熱量がこのLTで発散されています!!
愛の妄想シリーズが続きます。ww
「むらたの愛だけ語っていても、Jagu’e’r さんに『ねえ、わたしのどこが好きなの?』と聞かれてしまう」

このワードチョイスはやっさんの経験、、、と感じたことはさておき、やっさんの答えは以下の3点!

- 称賛とポジティブに溢れているから、もっと貢献しようという気持ちになる!
- 頑張っている人が身近にいるから、自分も頑張ろうと思える
- テーマがたくさんあるので、飽き性の人でも飽きない!!
やっさんの発表で、Jagu’e’rが気になった方はぜひ、Jagu’e’rへの会員登録ください!
Japan Google Cloud Usergroup for Enterprise
(アクセンチュア株式会社 秋元良太)
アクセンチュア / 中川様
「一人でも小さく始められるGoogle Cloudで実現するほぼサーバレスなデータ基盤」
 まずは、アクセンチュアの中川さんの自己紹介です。
まずは、アクセンチュアの中川さんの自己紹介です。
個人ブログにてご自身で構築されたデータ活用周りの事例を投稿されているそうです。

今回の発表内容は、その中でも「野球の試合データ分析」になります。
個人でオープンソースのメジャーリーグ試合データを分析・解析をされたお話をいただきました。
野球だけに留まらず幅広いデータ分析に応用できる。まさに年末イベントの大トリを飾るに相応しい内容でした。
ワールドカップ真っ只中ですが、野球が大好き! 世間の風潮に流されない強い想いを感じました。
以前に野球試合のデータ分析会社のCTOをされていた経緯もあり、非常に実用的な内容でした。

野球の試合データ(投球・球速・打席)を全て収集している「Statcast」というシステムのデータを活用されたそうです。どなたでも閲覧・ダウンロードができます!
https://baseballsavant.mlb.com/
そもそもプロ野球の試合データがここまで細かく収集されていたことに驚きですよね。
となると他のスポーツも同様に計測されたデータが集計されるサービスがあるのか気になりました。

このデータを活用して中川さんは、大谷選手の成績を分析しました。

2022年に大谷選手が好調だった要因として、スライダーを多く投げていたのだとか。
ホームランを打った際には、球速の速いボールの割合が多かったなど。
選手の「何となく調子がよかった」状態を定量的に観測できるようにすることで、高いパフォーマンスの再現性を高めることできると感じました。
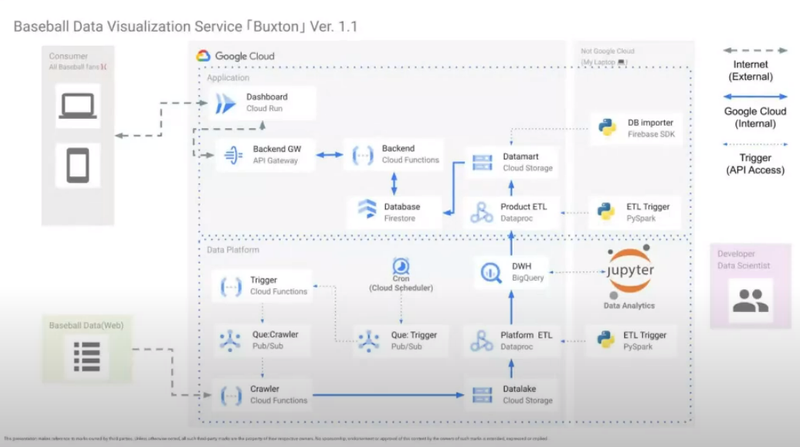
構成図はこちら。構成図をご紹介すると下記の通りです。
・上半分がアプリケーション:前述の大谷翔平選手のデータを可視化。
・下半分がETL部分:「Statcast」からデータを抽出・集計・BigQueryに流す。
綺麗でわかりやすい構成図で有償提供できるクオリティでした。

今回中川さんが伝えたかったことは大きく2つありました。
1.基本的にDWHはBigQueryを使いたい!を前提にETLとアプリケーション本体を設計。
2.1つ1つコンポーネントは小さなアプリなのでCloud Run構築・運用可能。
改めてデータ分析においてBigQueryにデータを集約すれば、何でもできる(諸説あり)に気づかされた内容でした。
各コンポーネントごとにフォーカスして、ご紹介いただきました。
こんなにリッチな内容を無償で聞けるなんて・・・有難うございます中川さん、データ利活用分科会。

野球のデータだけでなく、松田さんから講演頂いた「Fitbit」はもちろん他スポーツのデータ分析・活用にも応用できそうな素晴らしい講演でした。
「好きこそものの上手なれ」と言いますが、実際に試合のデータ分析を自分でしてみよう!となる実行力に刺激を受けますし、その仕組みをオープンな場で公開してくださる思想にも共感しました。
今回初LTでしたが、以降もデータ利活用分科会で中川さんのその後を共有してもらいたいですね!
本日は有難うございました!中川さんの次回作に乞うご期待ください。
(株式会社primeNumber 加藤大輝)
所感・まとめ
今回は、素敵な Fitbit の基調講演から始まり、ビジネスな話から個人用データ基盤開発の話、そして、基礎研究まで幅広い演題があり非常に聞き応え十分でした。イベントに参加していると 2時間という時間があっという間でした。「データドリブン」が、かなり浸透してきたのを感じました。
どんな業界、業種であれ、データというものは、常に私たちの周りをついてまわりますし、何よりそのデータを生み出しているのも、自分たちでもあるということを最近強く思います。そして蓄積されたそれを分析することで、何かの証明ができたり、新たな知見が生まれたりするところに、私は魅力を感じます。
データ利活用分科会では今年も、データを支える基盤構築から、分析、活用事例まで幅広く発表いただきました。今年も本当に、ありがとうございました。
2023 年も、たくさんの事例で溢れることを確信しており、今から非常に楽しみです!みなさま、これからもよろしくお願いいたします!
(シスメックス株式会社 / 増森 聡明)
次回予告

さて、次のイベントは年始になります。
年始は Lunch & Learn !! みなさま、お昼ご飯をご準備の上、茶話会感覚でお越しください。
お申し込みはこちらから。
2023年も、データ利活用分科会を、よろしくお願いいたします。