
活動報告: データ利活用分科会 第7回イベントレポート
みなさまこんにちは!
データ利活用分科会 #7 イベントの活動報告です。
今回はなんと初のハイブリッドイベント!!
現地では、みなさまの拍手やリアクションの声が聞こえ、オンサイトならではの良さも実感しました。
終了後の懇親会も非常に大盛り上がりだったようです!
今後はこのような体制でのイベントもどんどん開催していきたいと考えておりますので、積極的にご参加いただけると嬉しいです!
さて、そんな今回も大盛り上がりだったイベントですが今回はシステムからアプリケーションまでさまざまな素晴らしい演題が続いていました。
今回ご登壇いただいた朝日放送グループHD 伴さん、 LION 水谷さん、そして PharmaX 尾崎さん、ありがとうございました!!
それでは、それぞれのレポートをどうぞ!
朝日放送グループHD 伴 拓也様
「Looker導入体験談:ほんまのところ」

皆様ご注目!の Looker についての導入体験談です!
朝日放送グループHD の伴さんがご登壇です。情報理工学を学び、テレビ局に入社。グループ全体の技術統括として、DX の推進を担当されています。
そして衝撃の事実!!「利活用」という言葉は正式にはないそうです。経済産業省も当分科会も使っていますが、そうだったのかと、初めて知りました。早速、会社で話してみます。

データ利活用の重要性が高まっている今、「DX やデータや」。昨今の環境を受けての経営指示が来ます。世の中の一番の興味事項ですよね。
データを溜めるところからスタート。
中期経営戦略にも組み込まれているという流れになったということです。

1年ほどで着実に基盤のデータ準備を一元化、理解を促進。
利活用にあたっては、まずはデータの可視化から着手することにしたそうです。
データの可視化方法は、一般的には、SQL を活用する。これはリテラシーが必要になるので難しい。
それでは DataPortal のボトルネックである自由さは、管理を考えると厳しい。
「保守運用コスト」をさげて「少人数」で運用できる可視化基盤を目指していきます。
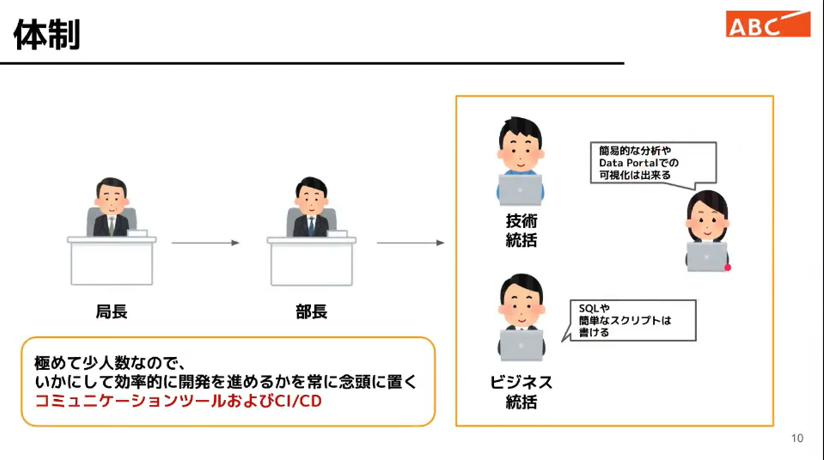
体制は部長以下実務は、技術統括、ビジネス統括、ご担当の3名のメンバーで回す。効率的な開発を目指します。
少人数で効率的に開発・運用するという進め方は大変参考になる事例と思います。

検討に際して考えたことが、少人数で運用可能であること、属人化を防げるものであること、権限管理を行えること。見えてはいけないデータは見せてはいけない。データ毎の管理はしたいですよね。
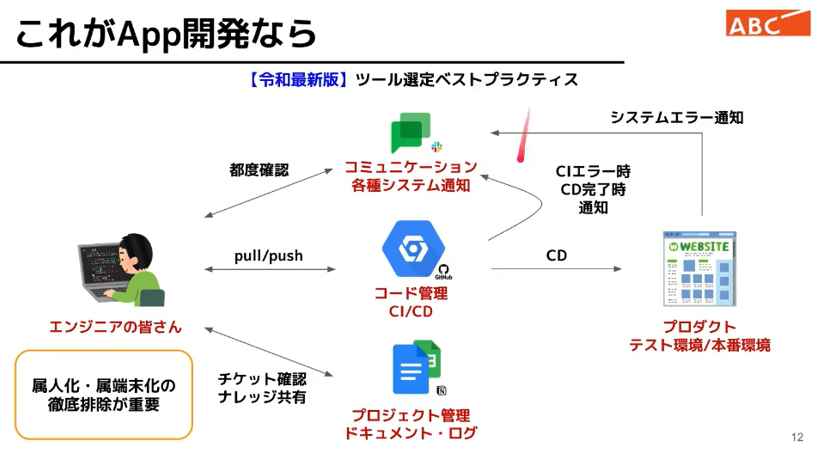
アプリ開発を想定すると、重要なのは、徹底的に属人化、端末化を排除。Githubでのコード管理。
エラー通知は、コミュニケ―ションツールを使う組み合わせで、BI ツール開発を進めました。
「【最新令和版】ツールセンタ選定ベストプラクティス!」

2021年にGoogle様に問い合わせをして、2022年2月中には PoC を実施。素晴らしいスピードです。
実施する対象は、2チーム。ふるさと納税サイトの「ふるラボ」チーム。こちらはほぼデータ分析をしたことがない。キャッチアップ(動画配信)系のチームで普段から他のBI 製品を使用して、データを閲覧しているリテラシーの高いチーム。ということで、比較をしてみたとのことです。
真剣に取り組んでもらえるように Quiz を用意して、正答率も高い正答率だったようです。

例えば、特定の PV 数を当てるクイズ、アクセスピーク数などを当てて頂くことを試みたそうです。
どれだけ時間がかかったのか、またわからなかったところも記載いただきます。
アイディアが面白い。一般的な検証よりも魅力的で、取り組んでみたくなります。
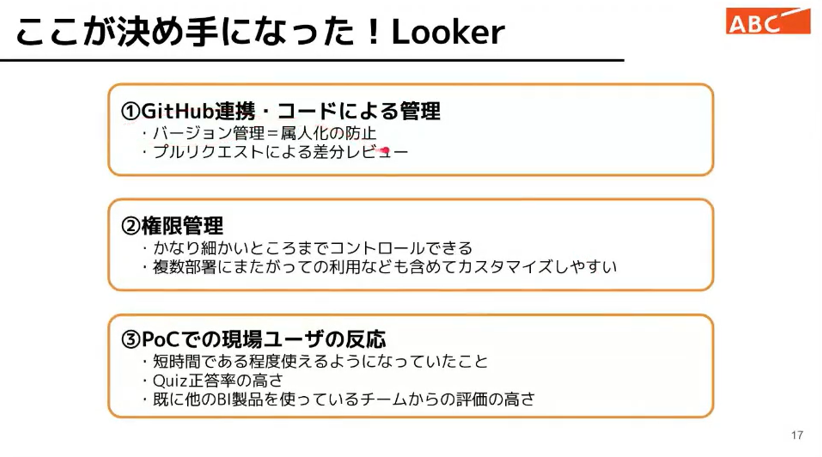
朝日放送グループHD様がLookerを選ばれたまとめです。
まず Github による共有化されたバージョン管理が可能であること。
伴さんお薦めの一番のポイント、権限管理です。ここが容易であること
最後に PoC での現場ユーザーからの反応。クイズの正答率が使っていないチームでも高かった。
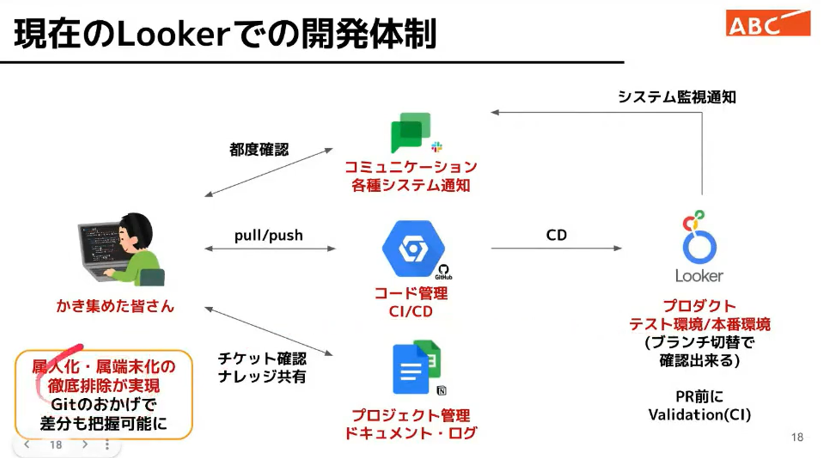
令和版ベストプラクティスに沿った開発。
開発体制についても当初設計した3本の柱に沿って進めることができたそうです。
属人化、属端末化の排除はできているということです。Github のおかげで差分も明確にわかる。
Lookerでもアプリ開発と同様のベストプラクティスを実現できました!
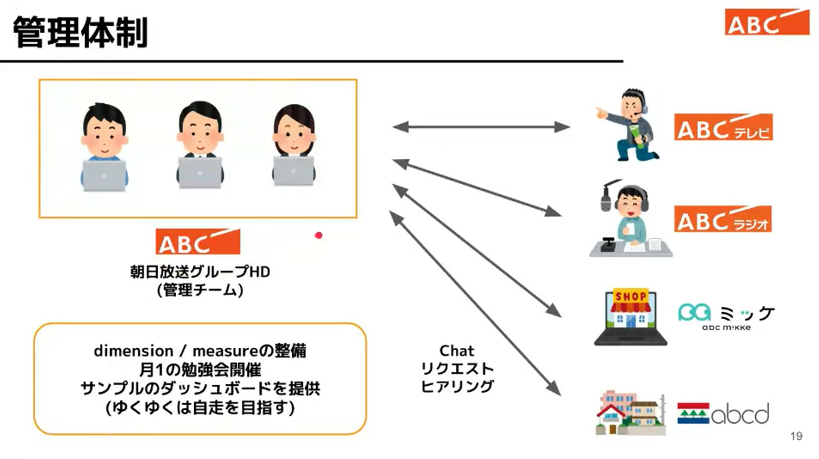
ホールディングスの管理部門として各事業会社の開発を請け負う体制。少人数の精鋭です。
Chat を使ったコミュニケ―ションによってリクエストやヒアリングを行う。
月1回の勉強会。Dimension、Measure の設定、ゆくゆくは自走を目指している。
データリテラシーの高い組織ができそうです。
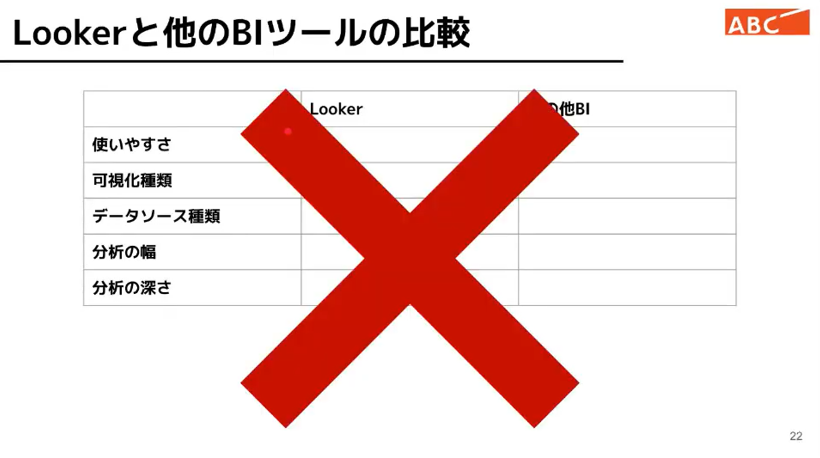
伴さん渾身の熱いスライド!
他の BI ツールと表で比較すること自体がだめなんじゃないか?。
ということが結論、それについては、以下の感想で語られます。

Looker の起点はデータを探索することから「可視化」領域が他の BI とかぶっているだけ。
何を作ろうかを調べて、知りたいという欲求から始まるところが特徴的と仰られています。
WEB 上の体験談と、現場の体験談がマッチしないこともあるのでとにかく PoC をやってみることがオススメとのことです。
是非、PoC やってみたいです。

ワークアラウンドの問題、開発環境の充実化、翻訳日本語、フォーラム等からの読込力が大切、Look ML は工夫の余地はあるものの、それほど不便性は感じないとのことです。

エンジニア寄りのスキルセットのチームだと間違いなくはまる(フィットする)とのこと。
BI ツールならではのばらばらの仕様の統一に「心臓を捧げる」人向き。まさに調査兵団、チャットで一同大変に盛り上がりました。
朝日放送グループHD 様の管理チームの志とチカラを感じます。

Looker と他の BI ツールは別物であり、とにかく PoC で試してみるのがオススメ。
少人数チームでもなんとかなるとの感触だそうです。
やはり、エンジニア寄りのスキルセットということも活かして、コードで管理されていると安心するというのが率直な感想なんですね。管理をしっかりできるということもすごく大事に思います。
リテラシがこれからの組織にこそ向いているかも。
私は、この数年、様々な BI ツールを試しました。現場まで開発者を増やそうとしたり、定型化にも挑戦しました。現場の自分でやりたい欲が強く、私自身が属人化の中心になってしまっているので、とてもLooker や朝日放送グループHD様の開発体制は参考になりました。
伴さん、ありがとうございました。
(LION / 水谷 晶史)
LION 水谷 晶史様
「文系の人事パーソンが GCP の開発リーダーになるまで」
みなさん、今日もLION使ってますかー?
お二人目は、LIONの水谷さんがご登壇です。水谷さんは元「文系人事パーソン」で、タイトルからすると今は「情シス」かと思いきや、「営業部門」でGoogle Cloud Platform開発リーダーを務められています!
LIONさんは、日本の清潔や衛生、健康づくりを担ってきた歴史のある会社で、そのパーパスは「より良い習慣づくりで、人々の毎日に貢献する」、です!このパーパスが、「営業部門」の今後のマーケティング施策にどう関係するのか、最後のスライドで明かされます。
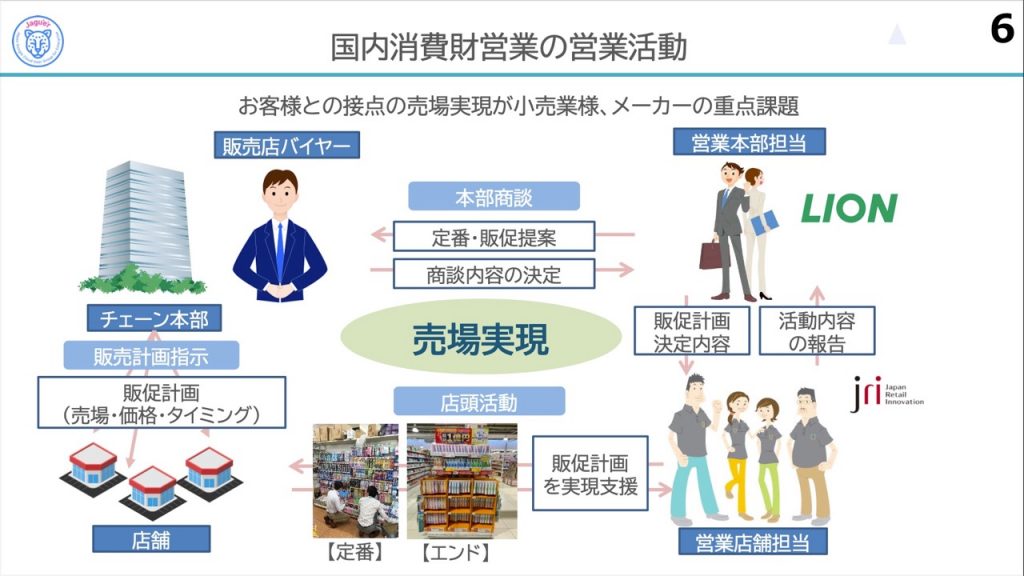
今やECが活況の時代ですが、LIONさんの消費財は約9割をリアル店舗で販売しているそうです。水谷さんのいる営業部門はどんなお仕事をされているのでしょうか?一言で言うと「売場実現」だそうです。

小売業とメーカーが協業して「売場実現」を果たすために、カテゴリーキャプテンという制度を設けているそうです。カテゴリーキャプテン制とは、小売業が取り扱う商品のカテゴリー単位でのトップメーカーをカテゴリーキャプテンとして任命し、カテゴリーキャプテンのメーカーがカテゴリー分析から棚割り、施策の提案まで、利益責任を負って担当する制度だそうです。
各小売企業から提供されるPOSデータの商品総数は、およそ120,000SKUにのぼるそうです。これに店舗数(およそ130,000店)と日数のレコードを掛け合わせると、巨大なデータサイズになります。LIONさん単独の商品数およそ800SKUと比較すると、メーカーの社内システムが想定している営業データサイズを優に超えることがわかりますね!

2018年当初、営業のビッグデータを分析するためのシステムは、まだ社内に存在していませんでした。エンジニア不在の中、水谷さんらはデータマネジメントセンター(DMC)を発足します。

DMCは、「自分たちでなんとかしよう」の精神を持つ、4人のメンバーが立ち上げました。ミッションは「営業データプラットフォームの構築」でした。最初に、スライドに書かれている現状の「問題認識」と「対応の方向性」を定義しました。

POSデータを市販の分析ツールを使って出力してみたところ、1レポートにつき平均出力時間は「461.2分」でした。なんの数字か当てるクイズを作れそうですね(笑)朝予約して夜出力というペースでは、使い物にならない上、やり直しが発生すると大幅に時間をロスしますね…。
目標は、1レポートにつき平均出力時間「20秒」でしたが、当時のパートナーさんと協議の結果、「無理」という判断に(涙)。
しかしDMCは諦めず、自社でクラウドを作ることを経営に提案し、承認を得ます。

ところが、当時はGoogle Cloudの開発委託先が少なく、システム開発はベンダーに依頼すればok!!、という具合にはいきませんでした。社内情報システム部門に頼れるリソースも少ないため、最終的に、外部から「エンジニア1名を雇用+ベンダーから技術指導」を受けながら、営業部門が開発を進めることになりました。
プラットフォームは、営業の武器ということで「KATANA」と命名します。かっこいい…!(ス●キの名車が頭をよぎります。)水谷さんらはわずか4ヶ月でKATANAを仕上げ、2企業限定で一次リリースを果たします。おぉお!KATANA!KATANA!!!! MeetのチャットにはKATANAコールが飛び交いました(笑)

当時、全企業分のPOSデータは社員が丸1日を溶かしてwebから取込んでいました。作業時間は月およそ155時間(涙)。これも何とかしたいと、自動化メンバーをアサインし、6ヶ月で全企業分のRPA実装を完了させました。これで日別のデータ分析も可能になり、作業時間は月10時間まで短縮されたそうです。巷のRPA導入成功事例のお手本ですね!
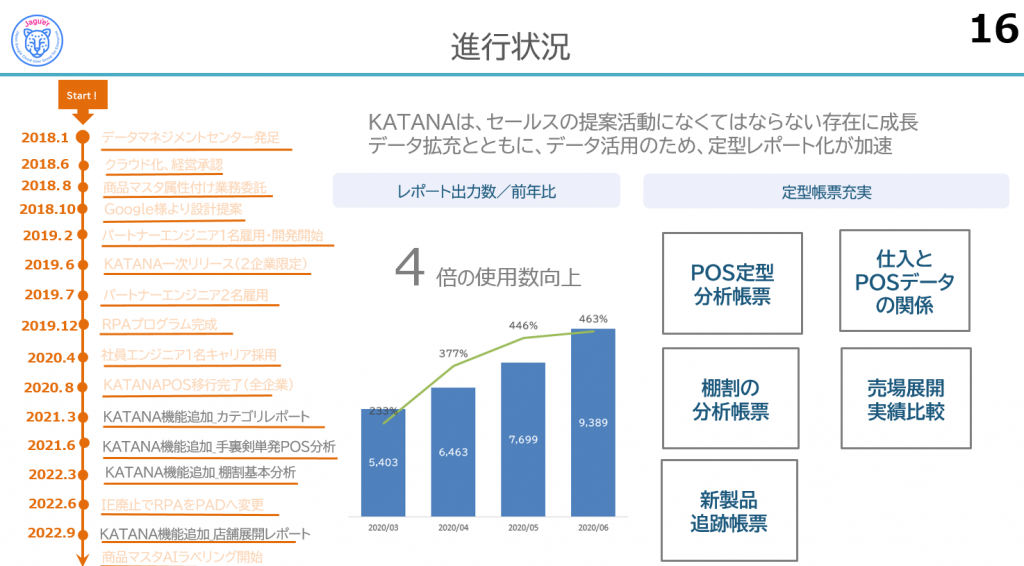
データ取込みとシステム開発が終わり、文字どおりKATANAが水谷さん達にとって欠かせない武器に成長しました。さらにデータ拡充、定型レポート化を加速させていきます。
レポートの出力数は4倍に増え、現在では月間約12,000レポートをダウンロードしているそうです。
また、分析にかかる時間を削減するため、データの出力を工夫し、そのまま提案に利用できるような定型レポートを充実させていきました。
売場の展開とPOSデータ実績の可視化や、店舗の売場展開を促すチャート、棚割りヒートマップなど、うまくデータビジュアライゼーションを活用されています。
残課題は、残り6割のCSV出力を定型化することだそうです。
ドーーン!!
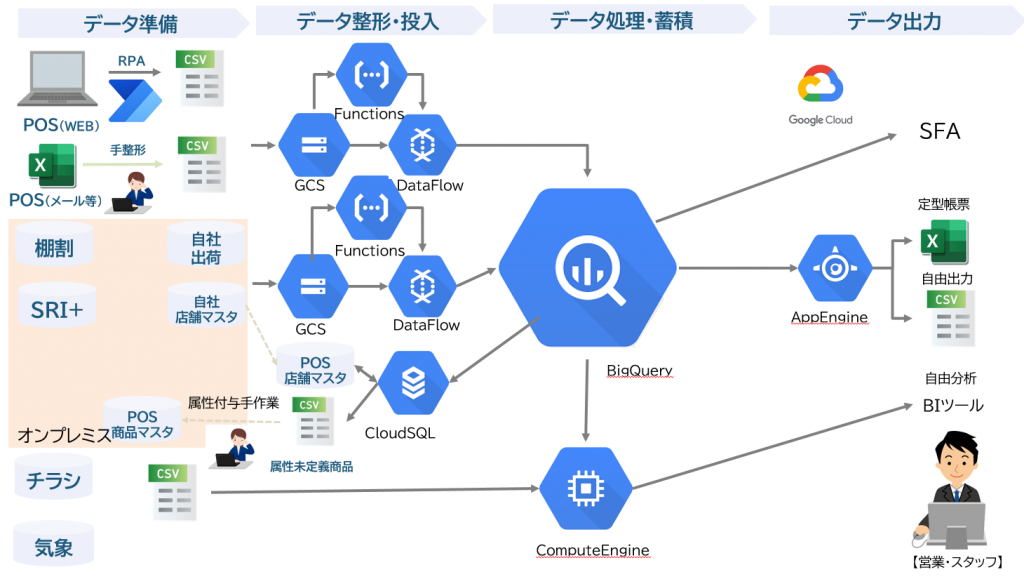
エンジニアのみなさんお待ちかねのアーキテクチャ図のご紹介です。
一番大変なところは、POSデータ準備のフェーズだったそうです。いまや毎日4台のRPA君が6時間動いてくれている、と語る水谷さん。親心でRPA君を温かく見守る姿が目に浮かびますね。
取得したPOSデータは、Google Cloud StorageからDataFlowを経由してBigQueryへ取込まれます。「棚割りデータ」や「SRI+」(市場データ)は社内オンプレミスサーバーに蓄積されるので、これも同様にBigQueryへ取込みます。
また実験的に、「チラシ」や「気象」が売上げへどう影響するかを分析するため、Compute Engineを導入しているそうです。営業部隊は、SalesforceやKATANAのアプリケーション、BIツールからの出力データを用いて分析を行います。
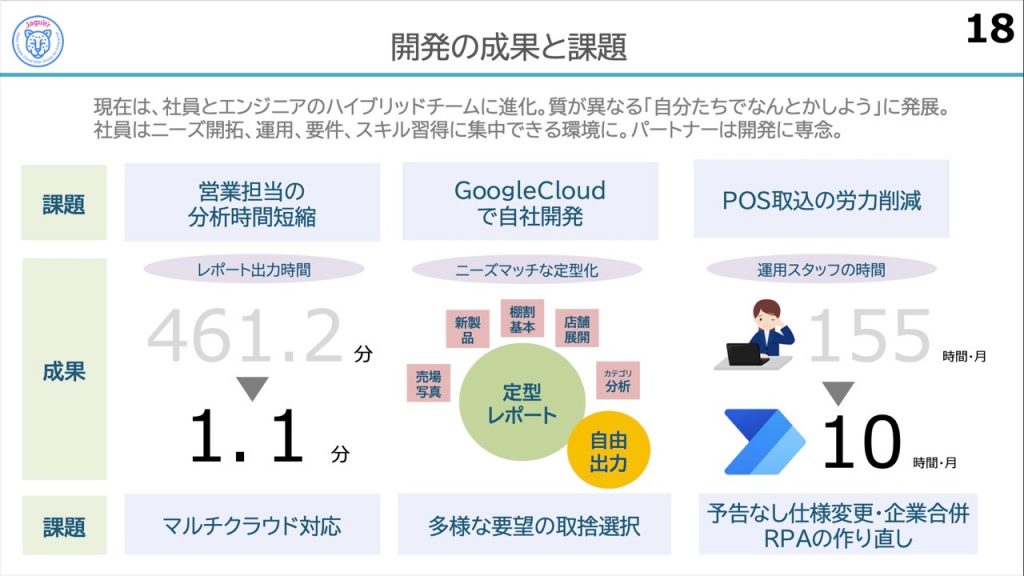
DMCメンバー構成は発足時から変化を遂げ、今では社員とエンジニアのハイブリッドチームに進化しました。DMCの精神「自分たちでなんとかしよう」は引き継がれつつ、社員が直接売上に関わる仕事に集中できるようになったことで「自分たちでなんとかしよう」の質は変わってきた、という実感があるそうです。2018年1月から2022年9月まで積み重ねてきた努力が実った証ですね!
DMC発足時に掲げていた以下3つの課題と、その成果をみなさんご覧ください。
- 営業担当の分析時間短縮
- レポート出力時間が1レポートにつき461.2分 → 1.1分に短縮!
- Google Cloudで自社開発
- ニーズにマッチした定型レポート出力や自由出力が可能に!!
- POS取込の労力削減
- POS取込の時間は155時間/月 → 10時間/月に短縮!!!
抜群の費用対効果が出ています。
一方、現状の課題は、予告なく小売企業さんのweb仕様が変更されるケースが多く、RPAの作り直しが発生していること(涙)など、だそうです。
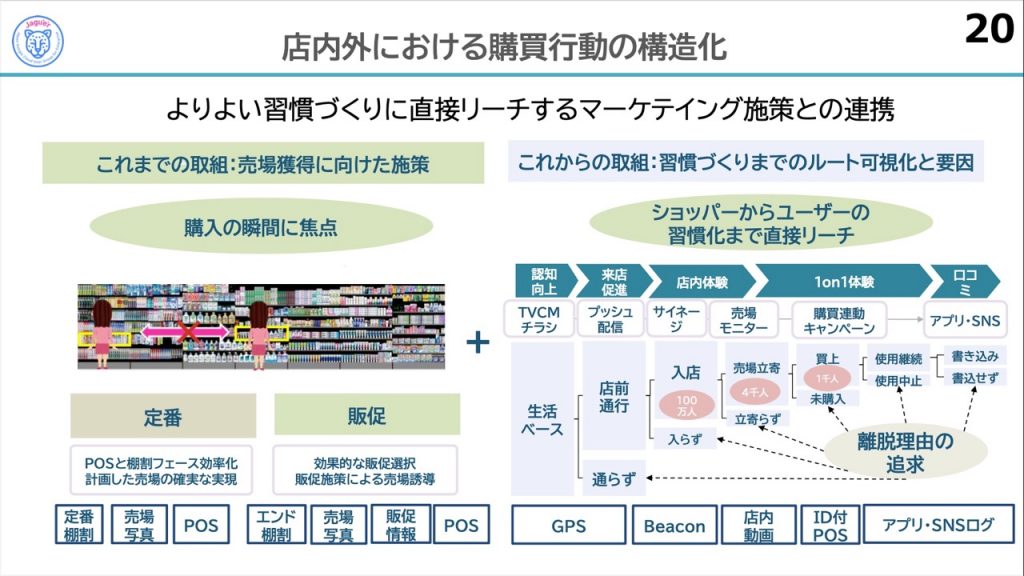
冒頭でご紹介しましたが、メーカーの究極の姿を目指すLIONさんのパーパスに「よりよい習慣づくり」という言葉がありました。究極的にはユーザーの「全てのデータ」を収集できれば「よりよい習慣づくり」にリーチできそうです。とはいえ、現実はそうもいきません。
水谷さんは、少しでも理想に近づくため、今後のあるべき姿を語ってくれました。現状は、お客様の購入の瞬間におけるデータを収集していますが、今後は、お客様のカスタマージャーニーに沿ったデータを蓄積し、よりよい習慣化に至るまでのルートにおける分析を目指しているそうです。
最後のスライドは特に素晴らしいまとめで、私の個人的お気に入りです。ルートの分析から各地点で習慣化を阻む要因を特定し、マーケティング施策を考えるという狙いが、よく伝わってきます。
水谷さん、貴重なご体験を丁寧にお話しいただき、ありがとうございました。まだまだ進化を遂げていくKATANAの活躍ぶりを、数年先、またここで語っていただきたいです。
※ちなみに、ブログではお伝えできませんが、水谷さんの声はKATANAのイメージと異なり、柔らかく、だけどしっかり芯の通った、癒しのボイスでした。
(wywy 合同会社 / 遠藤 祥子)
PharmaX 尾崎 皓一様
「自社システムをHerokuからGCPに全面リプレースした話 〜データパイプライン編〜」
PharmaX(旧YOJO Technologies)の”ざっきーさん”こと尾崎さんによるセッションです!PharmaXさんは2022年9月にYOJO TechnologiesからPharmaXへ社名変更されたそうです。データ利活用分科会のイベントへは初参加とのことで、「スタートアップぽいアーキテクチャ選定を楽しんでもらえれば」とのアツいコメントを冒頭に頂きました!

自己紹介スライドに突如として現れた「りょーちゃんもお仕事する!」の愛くるしさにMeetのチャットが凄まじい盛り上がりを見せていました笑
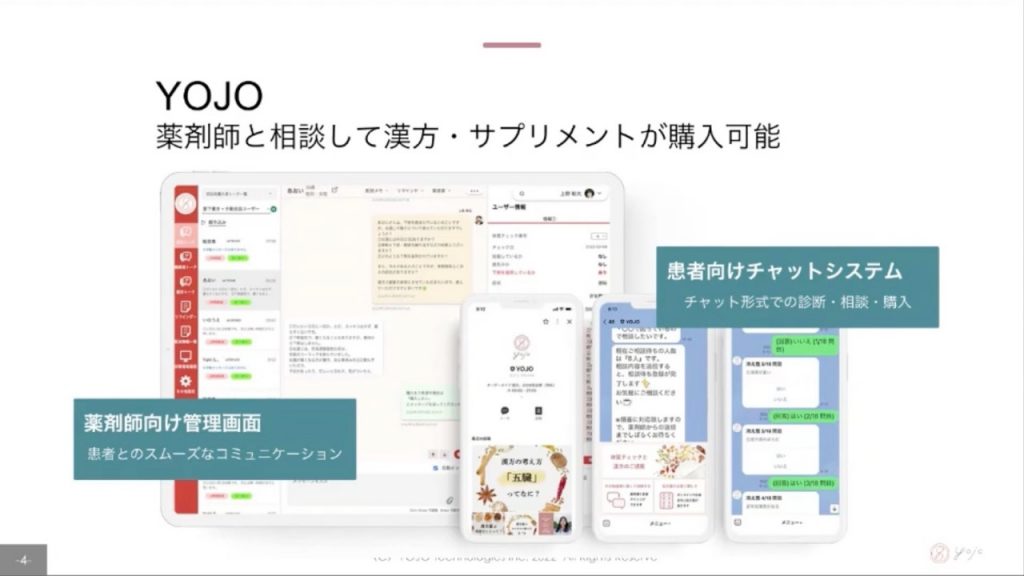
PharmaXさんはオンライン薬局のYOJO薬局を運営されています。処方箋を扱う薬局と、一般用の医薬品(漢方・サプリなど)を扱う薬局の2事業を展開されているようで、本日は後者の一般用医薬品領域のお話をしてくださります。
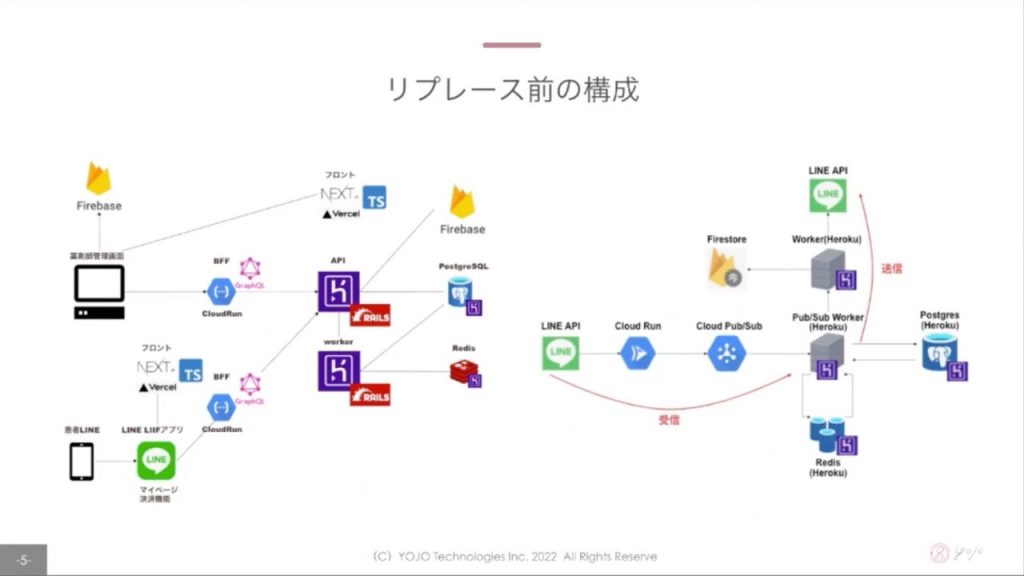
さて、エンジニアの大好物、”かっこいいアーキテクチャ図”が出てきました!!
フロントエンドはVercel、バックエンドはHerokuを使うなど、インフラエンジニアがいない中で運用負荷の低いサービスを利用するといった考え方でアーキテクチャ選定をされたそうです。一部Cloud RunやPub/Subを使うなど、Google Cloudのマネージドサービスもうまく活用されていました!
右側の図は、患者さんとのLINEのやりとりに関わるシステムアーキテクチャですが、大事なやりとりの情報をロストしてはいけないという背景からPub/Subを利用したキューイングを行うなどメッセージロストに対して堅牢な設計を心がけたそうです。
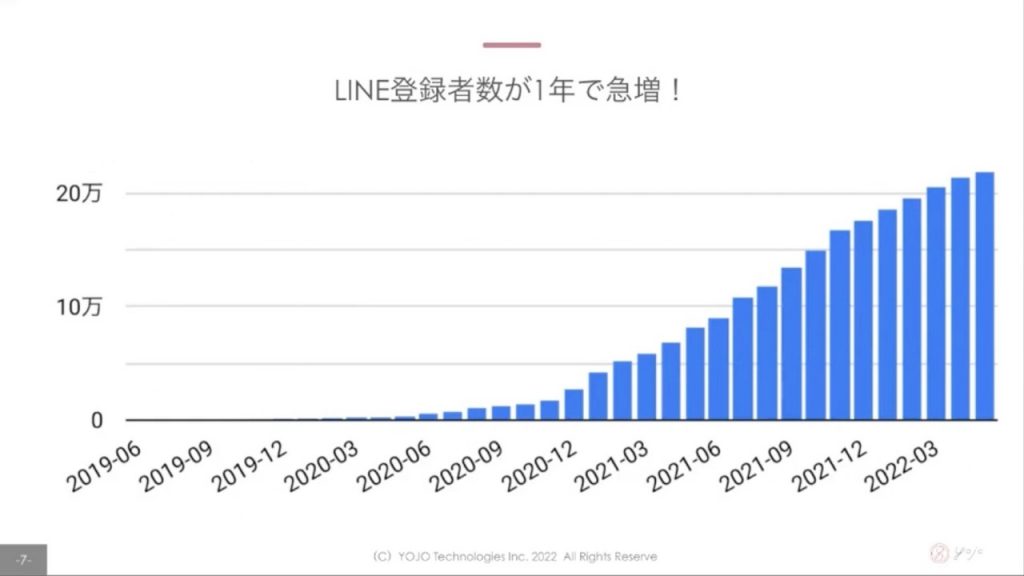
運用を続ける中でLINE登録者数が1年で急増!!20万人…すごいですね。
サービスが浸透していくのは非常に喜ばしいのですが、悩ましいポイントもちょこちょこ出てきてしまいました。

大きな問題点が2つあったようです。
1つめはHerokuに関して。海外リージョン利用によるレイテンシ問題やDBがパブリックに公開されてしまうことに起因するセキュリティ問題が顕在化してくる中、Heroku Enterpriseへのアップグレードによる問題点の解消はコスト的に許容できなかったとのこと。
2つめはインフラ基盤の構成に関して。複数のクラウドやAPIを組み合わせて利用しているためネットワークレイテンシが大きく、また下のスクショのようにログデータがサービスごと各所に分散しており、開発者が運用に疲弊してしまっていたようです。
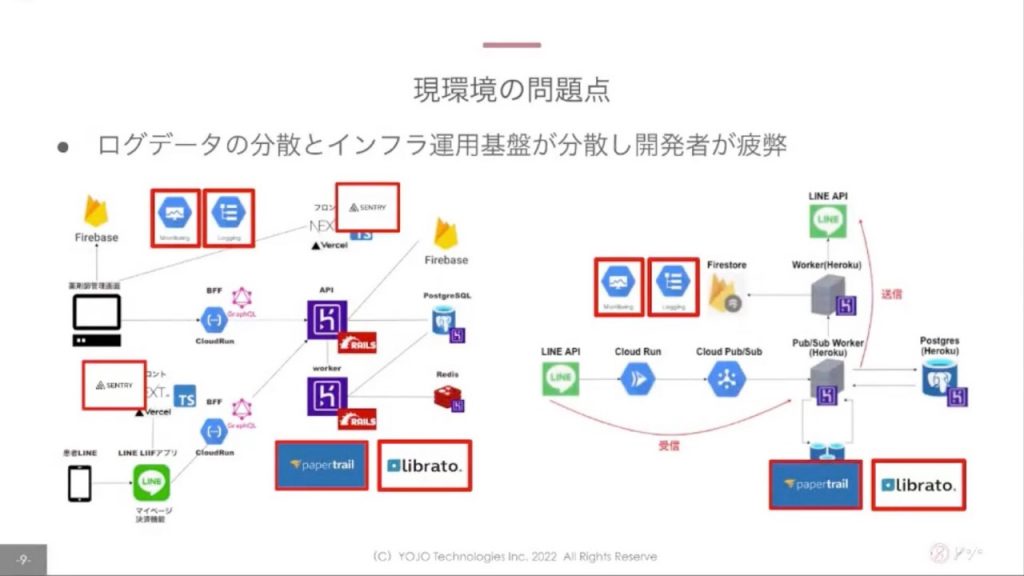 Herokuはpapertrail・librato、フロントエンドはSENTRY、Google Cloud上はCloud LoggingとCloud Monitoringにそれぞれログデータが分散しており、尾崎さん曰く「しんどかった…」とのこと。
Herokuはpapertrail・librato、フロントエンドはSENTRY、Google Cloud上はCloud LoggingとCloud Monitoringにそれぞれログデータが分散しており、尾崎さん曰く「しんどかった…」とのこと。
「疲弊しすぎで、モニタ3枚買おうかと思いました!」という尾崎さんのエピソードが秀逸すぎました。リアリティ溢れすぎてますね…!!!

プロジ○クトX感のあるスライド。なんか脳内でかっこいいBGMが流れ始めました笑

リプレースは発案からリリースまで2ヶ月、しかも2名体制…小規模体制ながら凄まじいスピードでリプレースPJを完走したようで、当日もセッションを聞きながら「すごい!!!」と心の中で拍手喝采でした。
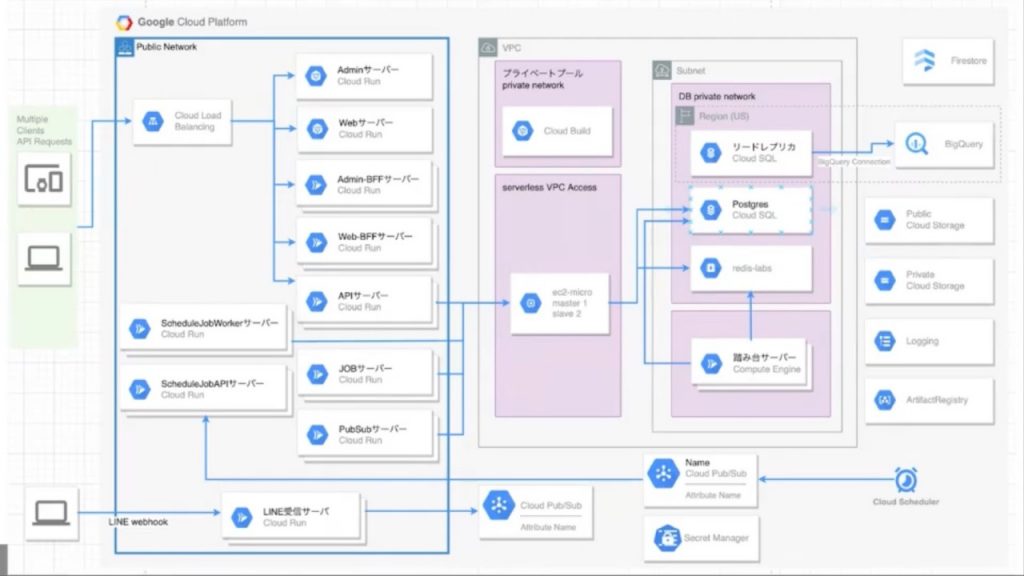
そして来ました!我らの大好物、”かっこいいアーキテクチャ図”!しかも箱が多い…!!!
尾崎さん自身も「誇れる実績」とおっしゃってましたが、これを2人でやりきったのは本当にすごいです。まさに自画自賛に値する素晴らしいチャレンジだったのではと思います!
「もっと褒めてください」とのことなので、Jagu’e’rで尾崎さんと会う際にはぜひ敬意と称賛を送りましょう!笑
Terraformを活用してIaC(Infrastructure as Code)を実現していたり、フルマネージドサービスであるCloud Runを引き続きがっつり利用して運用負荷を下げたり、こだわりポイントも多かった様子。

リプレースの結果として以下3つが印象的・良かったポイントとして語られました。
1つめはCloud Run中心のコンテナベース環境へ移行できたこと。セッションの中ではGKEとCloud Runの比較について言及されていました。界隈でもよく登場する比較ポイントですが、今回は「学習コスト」と「運用コスト」の観点からCloud Runを採択されたようです。
2つめはDBのPrivate化が達成できたこと。Cloud SQLを利用していたようですが、Private VPCの活用でデータをプライベート領域に格納することができました。またリードレプリカを活用できたことも良かったポイントだったようです。
3つめはログ基盤が集約されたこと。一時はモニタ3枚買ってしまおうかと思うほどに尾崎さんを悩ませていたログ分散問題ですが、今回のリプレースにより晴れて基盤全体のログ・アラートを集約させることに成功しました。これによりモニタは1枚のまま快適にお仕事ができているようです!これで一安心ですね。
さて、ここからトピックはデータパイプラインに移っていきます。
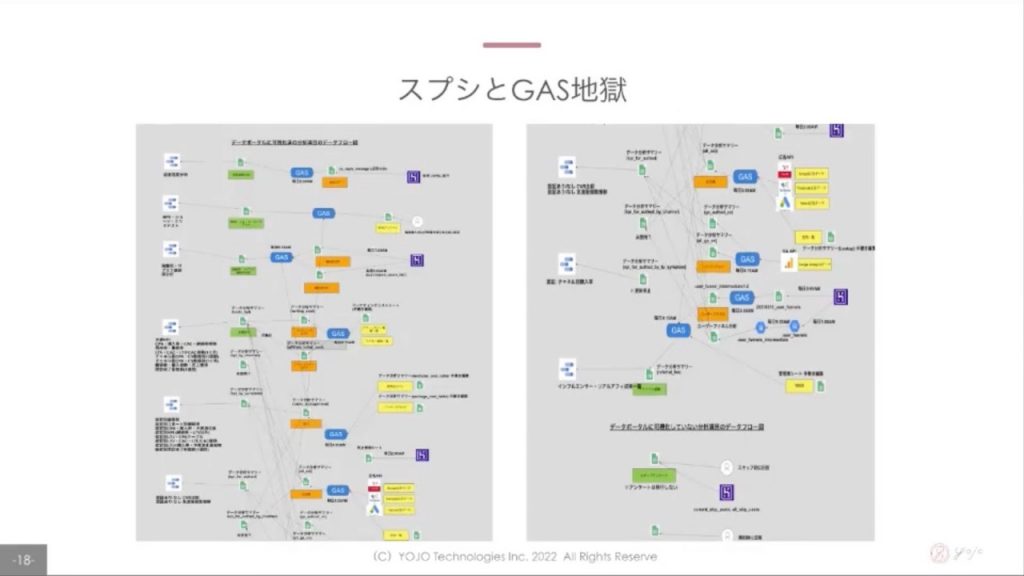
これはリプレース前の状態なのですが、「データ分析サマリ」という名前のスプレッドシートが存在するなど尾崎さん曰く「カオス」な状況だったようです。スプレッドシートの行数制限に引っかかり時系列でシートを分割、それをデータポータルで無理くりJOINしてクエリするなど力技もちょこちょこ駆使されていたとのこと。
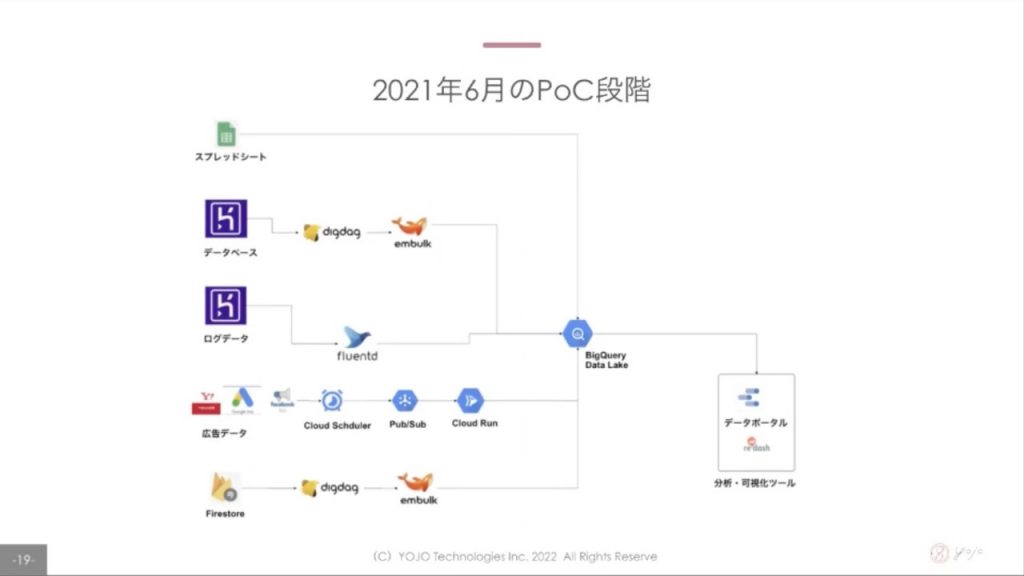
データエンジニア不在の中、↑のスクショのようなアーキテクチャをデザインし、改善に向けて歩み始めました。
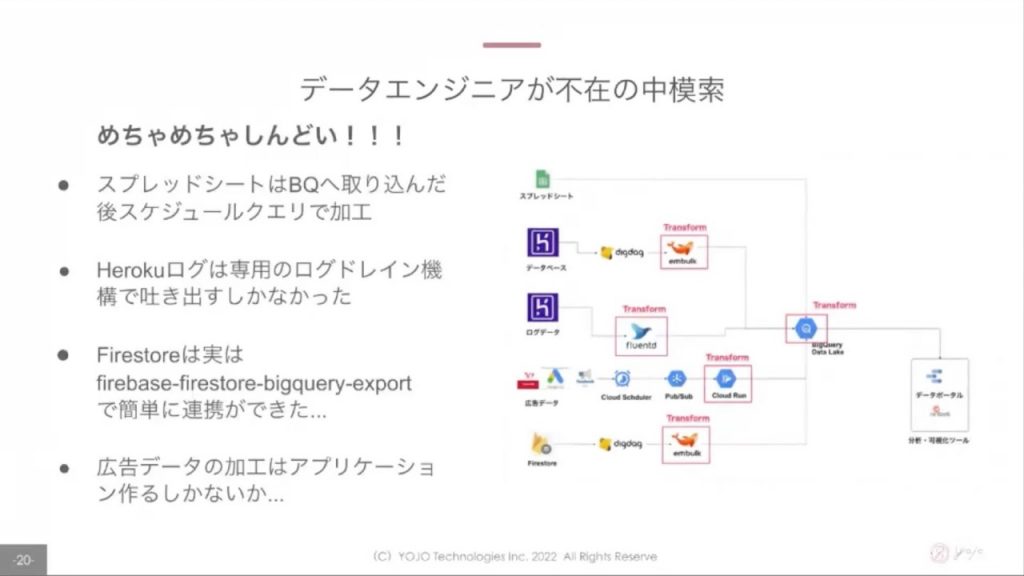
色々と模索しながら進めていたようですが、しんどい部分も多かった様子…

ここでメッセージ性の強いスライドが”ドン!!!!”。詳細が続けて語られていきます…
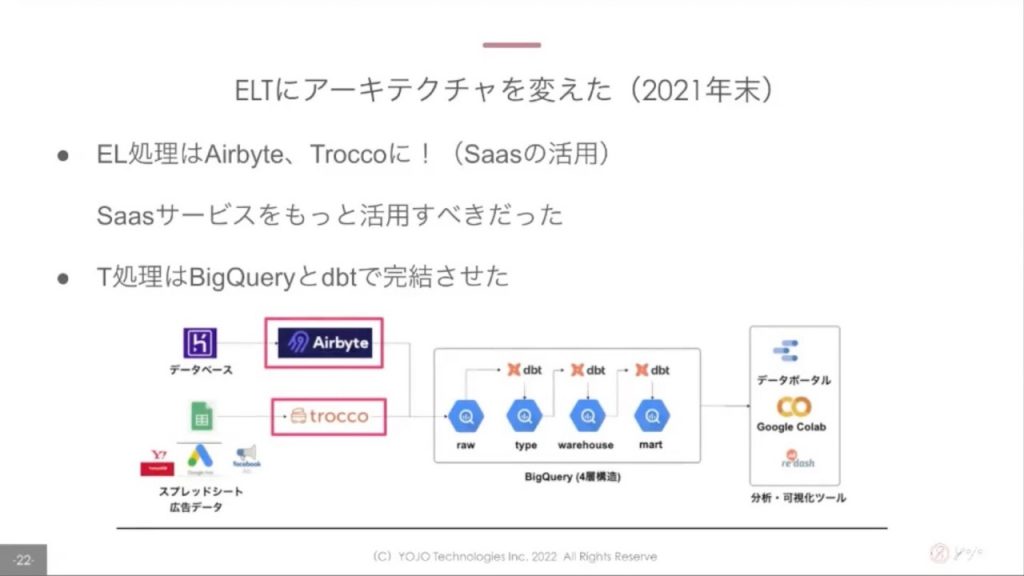
データエンジニアの方がアドバイザリー的に参画してくださり、EL処理はAirbyte・Troccoを活用、T処理はBigQuery・dbtを活用する構成へと変更していきました。
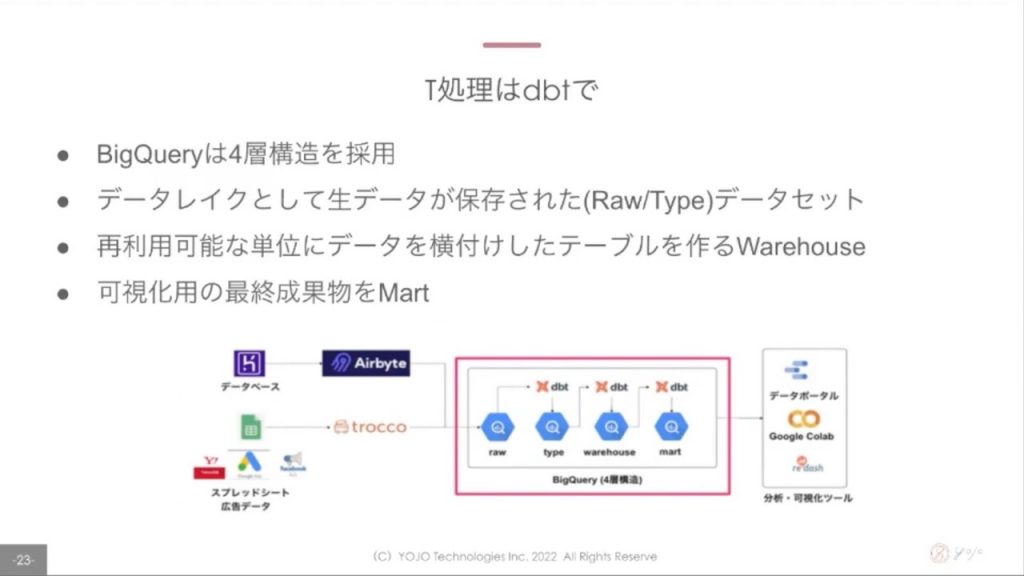
尾崎さん的にも「いいな」と思っているのがT処理部。dbtを使うことで「生データをいれる『raw』」「型変換を行う『type』」「活用しやすい形に整えた『warehouse』」「利用シーンごとに最適化した『mart』」の4層構造を実現できたようです。
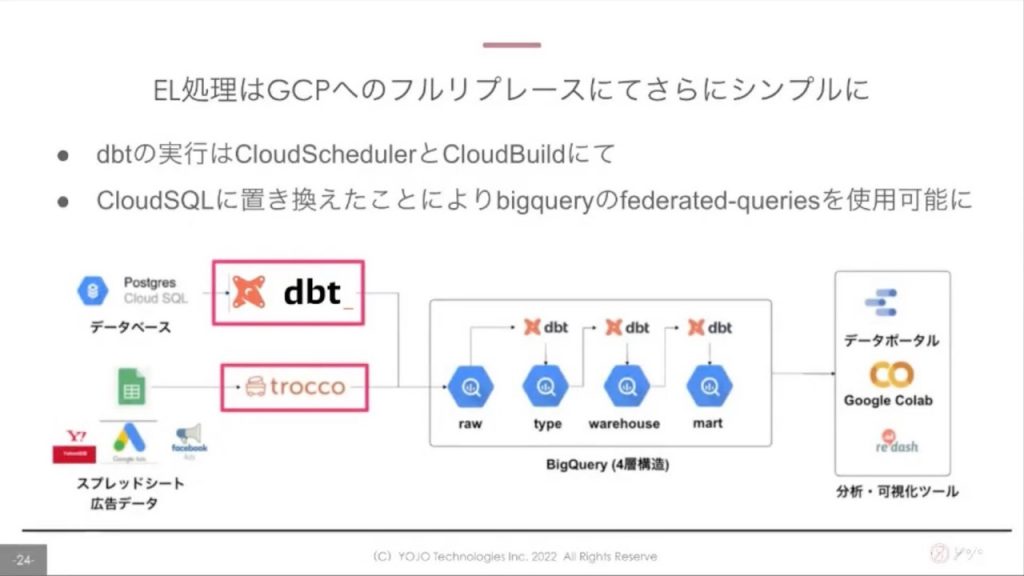
いままでHerokuだったインプットDBがCloud SQLへ変わることでdbtへ直接連携することができ、更にシンプルにすることができました。
大量のスプシ・GASと戦っていた頃と比べると凄まじい進化を遂げていますね。「だいぶ良くなったなあ」と尾崎さん自身もおっしゃられてましたが、本当に素晴らしいなと感じました!

リプレースにより更にうれしいポイントもいくつかありました。
1つめはEL処理をAirbyteからdbtへ切り替えたことに関するポイント。Airbyte時代はカラム変更時のアプリケーション連携が面倒だったようですが、dbtはそのへんをうまく吸収してくれていてとても運用が楽になったようです。
2つめはDBをHerokuからCloud SQLへ切り替えたことに関するポイント。これは先ほども言及されてましたが、Cloud SQLへ切り替えることでプライベート領域内にデータを保存する形を実現できたとのこと。
さて、ここまでリプレースにまつわる波乱万丈なストーリーを語っていただきましたが、最後にまとめと今後の展望を語ってくださいました。
「運用コストを下げたい」「最適なアーキテクチャを模索したい」というアツい思いで走り続けた結果、良い基盤が完成し、運用もスムーズに回っているようです。
今後は基盤に溜まったデータの活用にもどんどん取り組んでいきたいとのことで、尾崎さんはじめPharmaXさんのメンバーが生み出したこの基盤が益々活躍していく未来が見えますね。とても楽しみです!
魂を込めて作り出した基盤が形になり、そしてサービス利用者と運用者に幸せをもたらしてくれるって本当に素敵なことだなと思います!
尾崎さんの発表は以上です。アーキテクチャの変遷とそれに伴う様々なストーリーが盛り込まれた濃密なセッションでした!
(フューチャー / 村田 靖拓)
所感・まとめ
今回も幅広い業界の、データ利活用に向けた取り組みがたくさん聞けて、多くの学びを得られました!
伴さんのお話では、Looker の良さ、魅力に心を打たれ、ぜひ使ってみたくなりました。
水谷さんのお話では、内製化と BigQuery の強力さを改めて目の当たりにしました。
尾崎さんのお話では、アプリケーションの裏事情的な部分や、かなりの実装速度に、ただただ驚愕し、何より今後の最適化につきましても、またどこかでお話いただきたいなと思いました!
当日の懇親会では 2, 3 次会まで行かれた方もいたようで、オンサイトイベントならではのネットワーキング、交流もあったようです!
今後も引き続き、企画していきたいと思いますので、一度会場に足を運んでみてはいかがでしょうか?

(シスメックス / 増森 聡明)
次回予告

さて、今回の meet up も激アツだったデータ利活用分科会!なんと次のイベントが差し迫っております!!
10/7 (金) 18:00 – 20:00 にて、なんと Jagu’e’r 初となるコラボイベントの開催が決定いたしました!!!
Google HR による基調講演のほか、データ利活用人材の育成に関する LT 及びパネルディスカッションの開催が予定されております!!
みなさまこの機会をぜひお見逃しなく!!

また、データ利活用分科会としては、#8 イベントを、 12/2(木) 17:00 より企画中です!
こちらは、年末スペシャル Event と題しましてもはや恒例 ??! 年末大サービス NDA 無しのフルオープンイベントの開催にて企画中でございます。
2022年を締めくくる LT 祭りです。Jagu’e’r 会員様はもちろん、オンサイトでのご参加もいただけます。
是非是非こちらも、よろしくお願いいたします。
それではまた次の meet up でお会いしましょう!
(シスメックス / 増森 聡明)