
活動報告: データ利活用分科会 第三回イベントレポート
みなさまこんにちは。
そして明けましておめでとうございます。
今年もデータ利活用分科会をよろしくお願いいたします!
年末スペシャルと題しまして実施した第三回イベントはなんと2時間、4演題で実施させていただきました!
どの演題も非常に素晴らしかったです…!
LIXIL 平野様
オープンハウス 中川様
GiXo 花谷様
アサヒグループ 清水様
ありがとうございました!
以下、イベントの模様をお届けいたします。
演題のご紹介
演題1. LIXIL 株式会社 平野 圭一様
「LIXILにおけるSAPデータのBigQuery適用事例紹介」
まずは前回イベントでは活動報告も書いていただいた LIXIL 平野さんが御登壇。
TOTO だけじゃない!!そんな LIXIL 様の事例は SAP と BigQuery の連携。
SAP を扱う時の難しさ
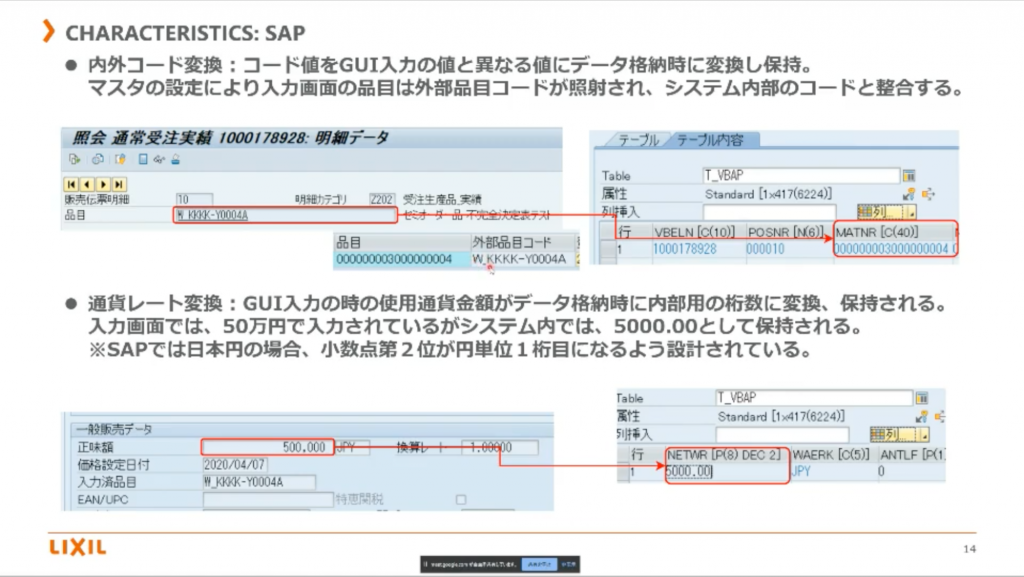
SAP を扱う上での特徴は内外コード変換。
GUI で入力している値と、内部で保持している値が異なるそう。
客先コードと自社のコードでブリッジをかけるためにあえて変換しているようです。
また、他言語対応ソフトのため、通貨レートの変換もかけてあげないといけないのだとか。
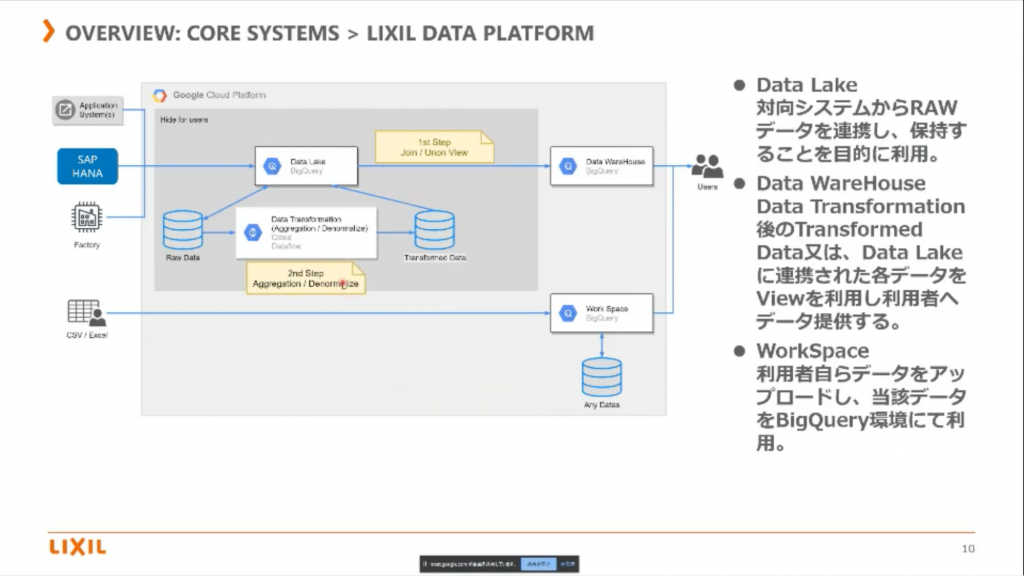
そのため、その特性を SAP Data Services で吸収してから、gutil を使用してBigQuery に展開しているそうです。
元々用意されている API を使うことで効率的に実装を進めるため、SAP Data Services を使用したところもポイント。
製造拠点からのデータも扱う必要もあるので、そこは FTP を使用しているみたいですね。
どのように構築したか
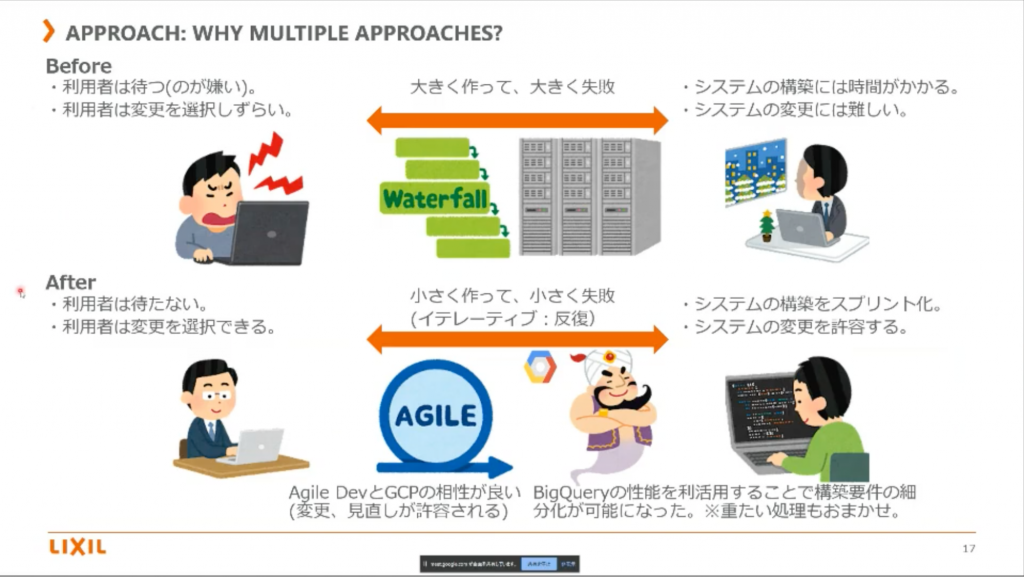
従来、Waterfall 型が根強かったみたいですが、今回は Agile 型。
ただ、その場合に一番注意したのがイテレーティブの誤解を最初に解いておくことだったそう。
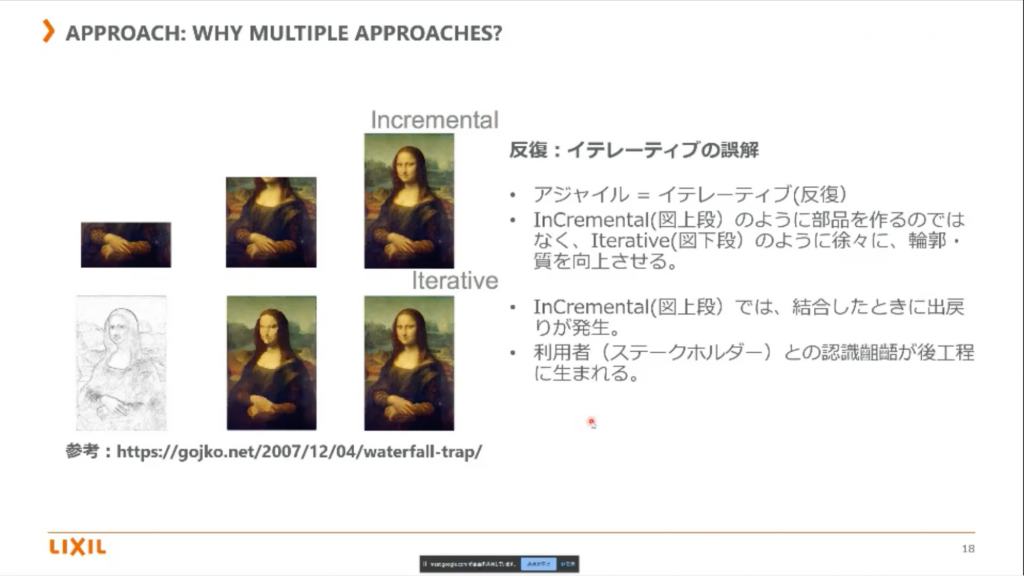
「下絵を書いて段々仕上げていくことが “反復” ですよ」と伝えておくこと。
「一度提供したものが最終版でなく、それを使ってみて不都合や要望があれば改善していきましょう」と進め方の合意をとっておくこと。
非常に重要だと思いました。平野様のおっしゃる通り、製造業では特に “反復” というと “Incremental” の意識が強い気がします。
個人的に一番共感したスライドでした。
そのため今回は 1st step と 2nd step の2段階で進めたそう。
1st step
- BQ の応答性 / パワーを活かして View でデータ提供してユーザからフィードバックを貰う
- 課金についても問題ないかここでチェック
2nd step
- 重たい、不都合がある部分に対しての改善
- 非正規化はトランザクションのみを基本とする
2nd step では、マスターデータを使用しての非正規化は最小限になるようにし、
必要なものは自分たちで作るような文化に変えて行っているようです。
おまけ: データの利活用について
Machine Learning を、spreadsheet 上で扱える kit を独自開発して、誰でも活用ができるように開発を進めているそうです!
今回は多く語られることは無かったですが、今後が非常に楽しみです。
ぜひ、また「おまけ」の件でもお話聞いてみたいですね!!
平野さん、ありがとうございました!!
演題2. 株式会社オープンハウス 中川 帝人様
「不動産業界におけるGCP・GWSによるデータ利活用 (Analytics、ML)」
オープンハウス 上席課長兼シニアデータサイエンティストの中川様からCloud On Air でもご紹介いただいたデータ利活用事例について、口頭でUpdate部分を細くいただきながらご紹介いただきました!
オープンハウス様のカルチャーは「気合と根性の営業の会社」とのこと!
不動産業界はアナログなオペレーション要素が多いため、ITを駆使して改善できるところが多く存在するそうです。
・オープンハウス様の情報システム部門の特徴

そんなオープンハウス様のITインフラを司る情報システム部の特徴は「少数精鋭」。
内政主義で新しい技術をどんどん取り入れコスパの高い領域を改善していく動きが特徴です。
ITコストが0.2%と一般的な企業に比べて投資割合が低く、必然的にコストパフォーマンスを意識した取り組みが必要になってくるとのことです。

投資だからといって失敗して良いわけではなく、立場上から必ず成功させなければいけないというミッションをお持ちでした。ただ、データ活用はやってみないと分からないケースが多く失敗してしまうケースも考えられます。
そこで中川さん達が意識したことは「とにかく安く、早く、多く作る」ということ。
これによって仮説と現実の差分を迅速にアジャストし、成功に導いていったそうです!
AI・RPA によって40,000時間もの工数を削減したとのこと、すごい!!!!
・事例 1 :マーケティング分析
<背景・課題>
不動産は 1 戸売れれば儲かるので、集客が非常に大事。Web 経由の契約率が 65% であり主要な販路となりますが、20 を超える媒体への広告評価が難しく、分析レベルの向上とPDCAサイクルの高速化が必要だったとのこと。
それらを改善するため DWH の構築に取り組まれました。
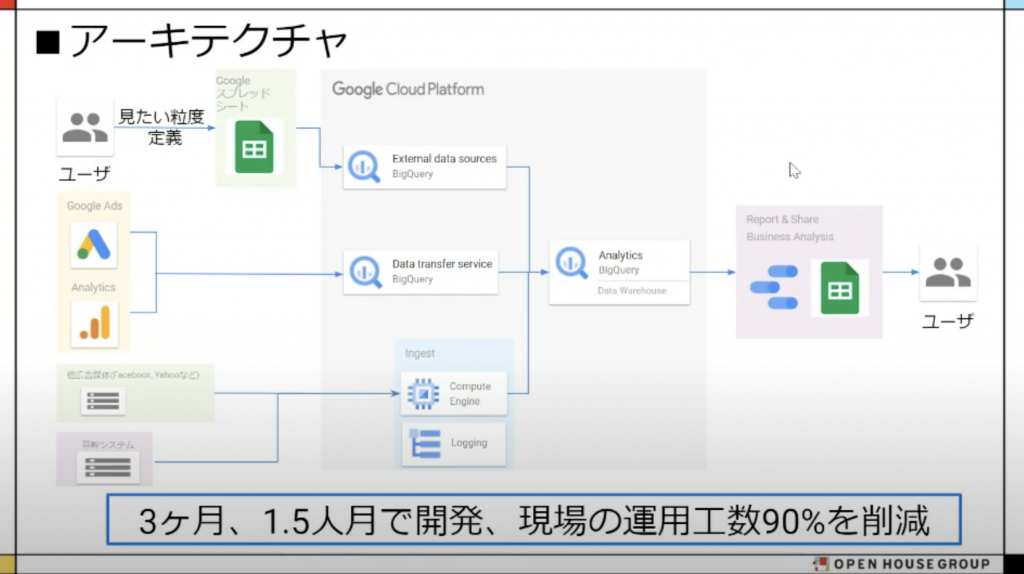
<実装>
既にスプレッドシートや Ads, GA などを使用していたとのことで BigQuery との相性はばっちしとのことで、前述通りコストを意識して作り込みが少なくなるよう意識し、1.5人月で構築されたそうです。他媒体など直接 BigQuery に取り込めないデータは Embulk を用いて収集したとのこと。
やはりスピード感の意識がすごいですね!
<実現できたこと>
BigQuery の関数が秀逸なところもあり、色々な分析が BigQuery 上で迅速に行えるようになり、広告の費用対効果が改善できたとのことです。
・事例 2 :類似物件検索
<背景・課題>
家を建てるときに作成する間取り図は、土地の形状でほぼ似たようなものになるようで、過去の類似物件をベースに設計を行うと設計工数を削減できるよう、過去物件検索システムを構築した事例です。
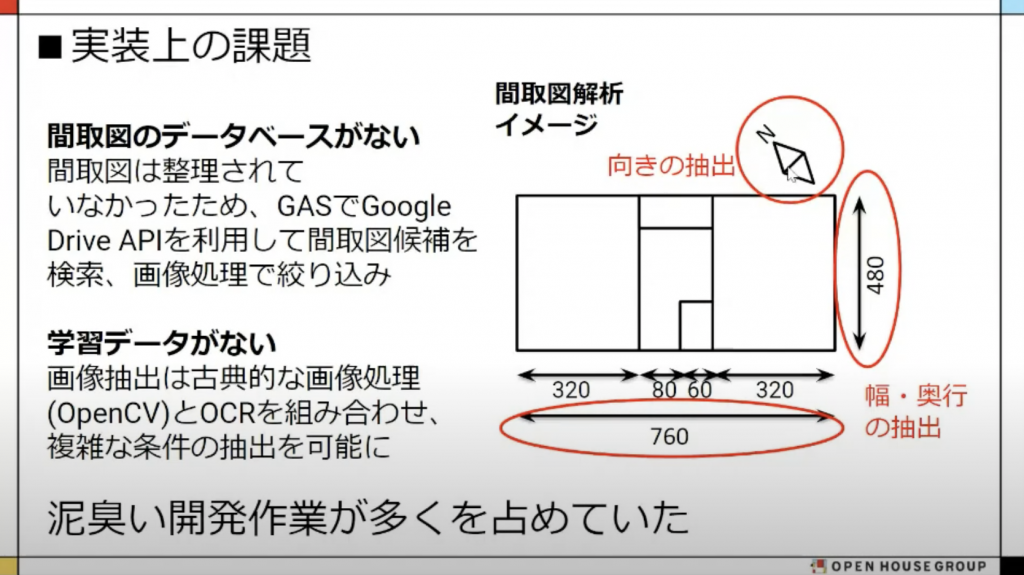
<実装>
書類をPDF化したものが Google Drive 上に格納されているのみだったので、 GAS で間取り図っぽいものを抽出する処理を作ったそうです。
間取り図一覧はスプレッドシートにすることで最小限の工数に抑え、必要なものをどれだけ正確に抜き出すか、という部分に注力したそう。
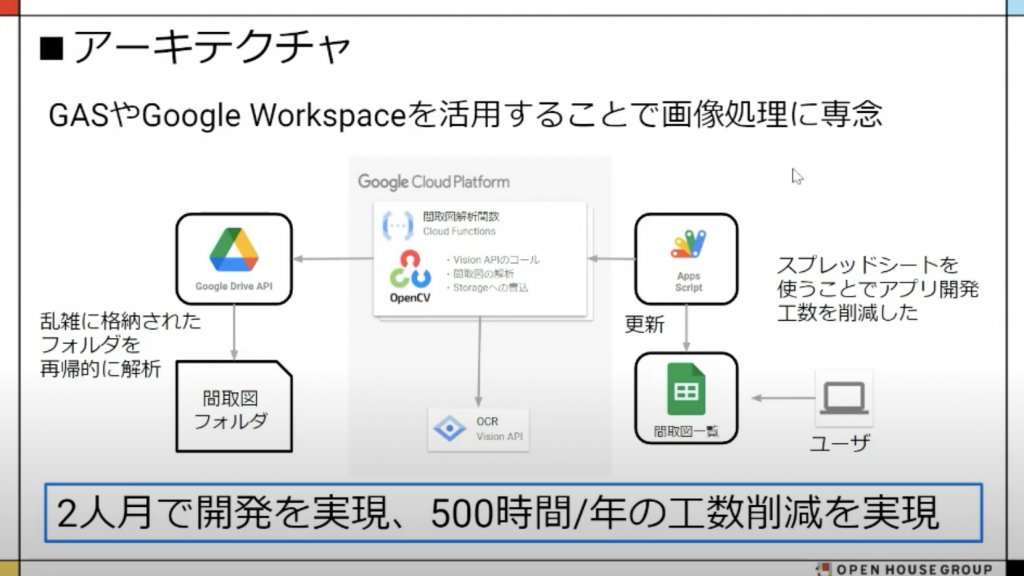
<実現できたこと>
若いエンジニアが 2 人月で開発し、500時間/年の工数を削減したとのことです。すごいコストパフォーマンスですよね!!!
この辺はデータ活用あるあるで本当に泥臭い部分です。予算上限もあるなかで本当にビジネス上の本質を抑えた、リアルで良い事例だなと感じた事例でした!
データ利活用のために
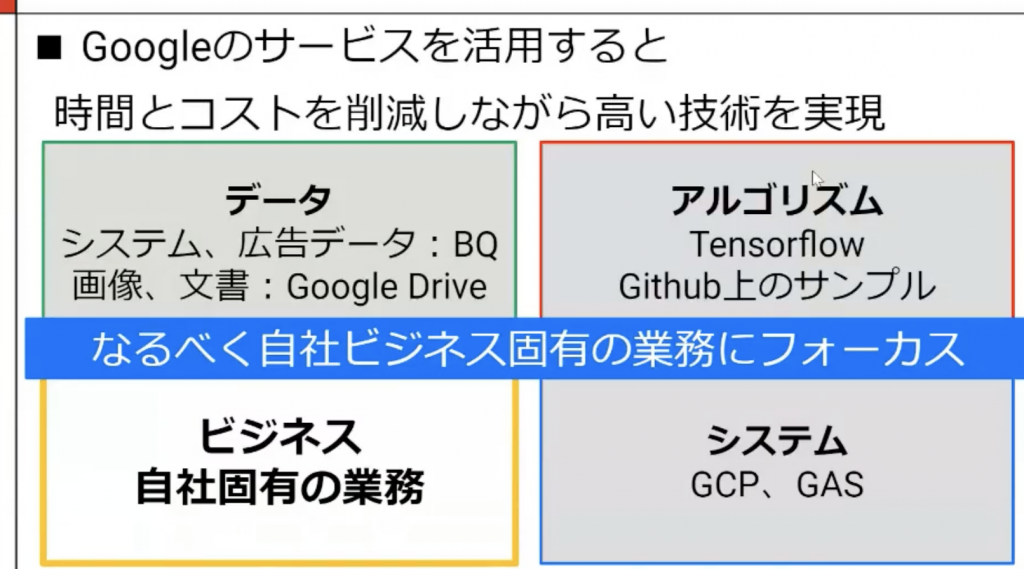
既存の使える仕組みやリソースをフル活用し、有限な時間を自社ビジネス固有の部分に注力することが、高いコストパフォーマンスを実現する条件とのこと。
まさにここは Google Cloud も打ち出しているポイントであり、なるべく必要な領域に分析者の方がフォーカスできるよう、サービス関連連携やアルゴリズムのサンプル、マネージド・サーバレスの機能拡充を進めていっています。まさにオープンハウス様は Google Cloud の良いところがバチッとハマった事例ですね!
中川さん、大変参考になる事例紹介ありがとうございました!!
演題3. 株式会社 GiXo 花谷 慎太郎様
「データ利活用支援会社からみたデータ利活用の成功企業の共通点」

創業10年目に突入、データインフォームド事業を営まれているGiXo(ギックス)の花谷様より、「データ利活用支援会社からみたデータ利活用の成功企業の共通点」という題目でご登壇頂きました!
今回は、「データインフォームド≒データ利活用」という位置づけでお話頂き、まさにデータ利活用分科会の皆様も興味津々な、プロジェクトの成否に関わるポイントをお聞かせ頂き、非常に納得感もあり参考にもなるご発表内容でした。
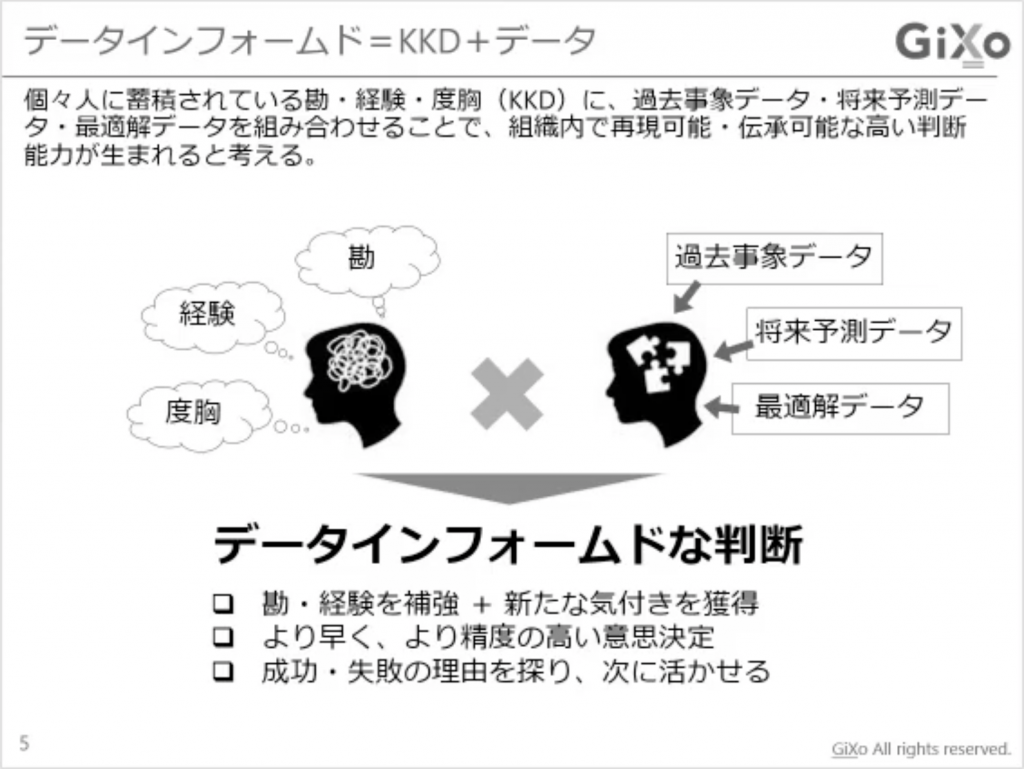
意思決定者が持っている勘・経験・度胸(KKD)とデータ分析を組み合わせることでより組織をドライブさせていくという、データインフォームドな判断・考え方が重要とのこと。
勘と経験だけでもなく、データだけを見るわけでもなく、「勘・経験を補強」というお話は非常に共感できました。
<成功企業の共通点>
データ利活用に成功する企業には共通点があり、何をやるかより誰とやるのかが、そのポイントを分けるとのこと。
花谷様いわく、推進力のある「破天荒リーダー」とご一緒できるかが成功の秘訣と感じてらっしゃるということでした。
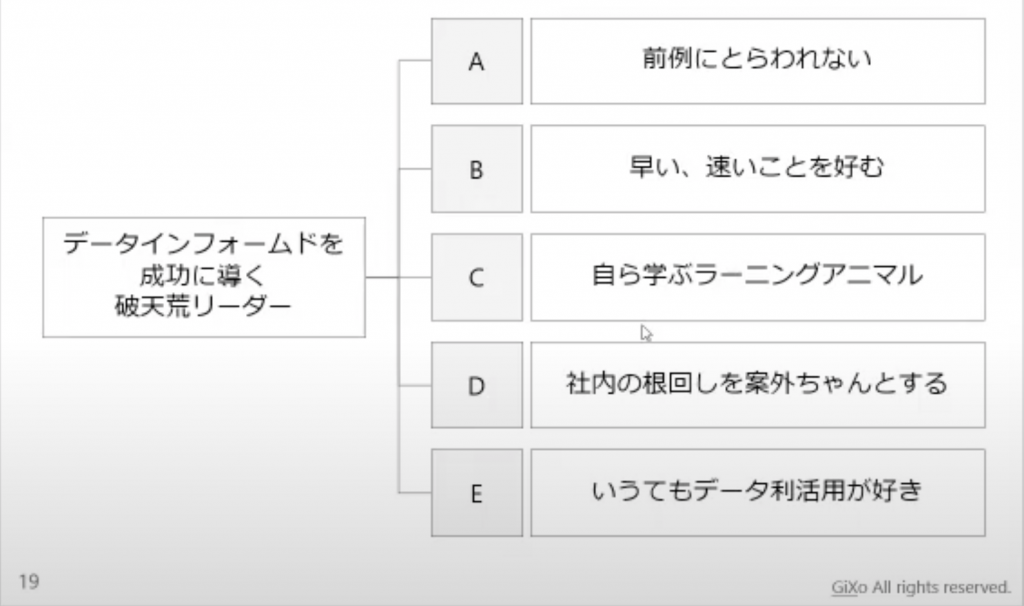
<成功に導く破天荒リーダーの特徴>
(A)前例にとらわれない
(B)早い、速いことを好む
(C)自ら学ぶラーニングアニマル
(D)社内の根回しを案外ちゃんとする
(E)いうてもデータ利活用が好き
破天荒リーダーの特徴として上記の5つをご紹介頂きました。
また、それぞれの特徴についてご経験を元にさらに詳しくお話頂きました。
(A)前例にとらわれない
「前例がないとできない」という大企業カルチャーではなく、むしろ「前例主義を嫌い新しい取り組みを好んで進めて頂ける方」という共通点があるそうです。
(B)早い、速いことを好む
「スタートが早く早期にアウトプットを欲しがる傾向がある。なのでアジャイル開発の進め方が合っている」
意思決定のスピードも早く、その時点でのアウトプットを見て都度判断されるので、そもそもアジャイルじゃないと難しいとのこと(笑)
一方でそういった判断力がある点は分析視点で見てもやりやすいというお話もあり、一方通行にならないようなリアクションとそれを引き出すコミュニケーションの大切さも改めて感じました。
(C)自ら学ぶラーニングアニマル>
40過ぎても「自分でも理解できるようになりたい」と、Pythonの学習を始めたりBigQueryでSQLを書いてデータパイプラインを自力で作り上げてみたり、と新しいものに対し貪欲な方が多いとのこと。
(D)社内の根回しを案外ちゃんとする
キーパーソンを適切に把握されていて事前に根回しを進めていたり、予算獲得能力が異常に高いことも1つの特徴とのこと。これには参加者の皆様からも納得の声が聞こえてきました。
また、社内のキーパーソンに可愛がられるような魅力の持ち主だったり、組織の動かし方に精通されていることが多いそうです。
(E)いうてもデータ利活用が好き
障壁に対しても手を尽くして乗り越えようとされたり、周囲をうまく巻き込んでデータインフォームドを推進する集団を形成するのに長けている方が多いとのこと。
そういったエネルギーの源は、「データ利活用が好き」というものが根底にあると感じられているとのこと。
あくまで、ギックス様でご支援されているお客様に上記のような共通点が感じられるとおっしゃられていましたが、非常に共感できる内容でしたし、分析を活用する企業側でも、どんな人財に旗振り役を任せるか、といった観点でも参考になる点は多かったのではないでしょうか。
花谷様、ありがとうございました!
さて次のセッションは、花谷様が「破天荒リーダーの代表格」とおっしゃるアサヒグループホールディングス清水様のセッションです。
演題4. アサヒグループホールディングス株式会社 清水 博様
「なぜアサヒグループは変革できたのか」
アサヒグループ全体のシステム統括のIT推進・戦略立案をされている清水様のご発表です。
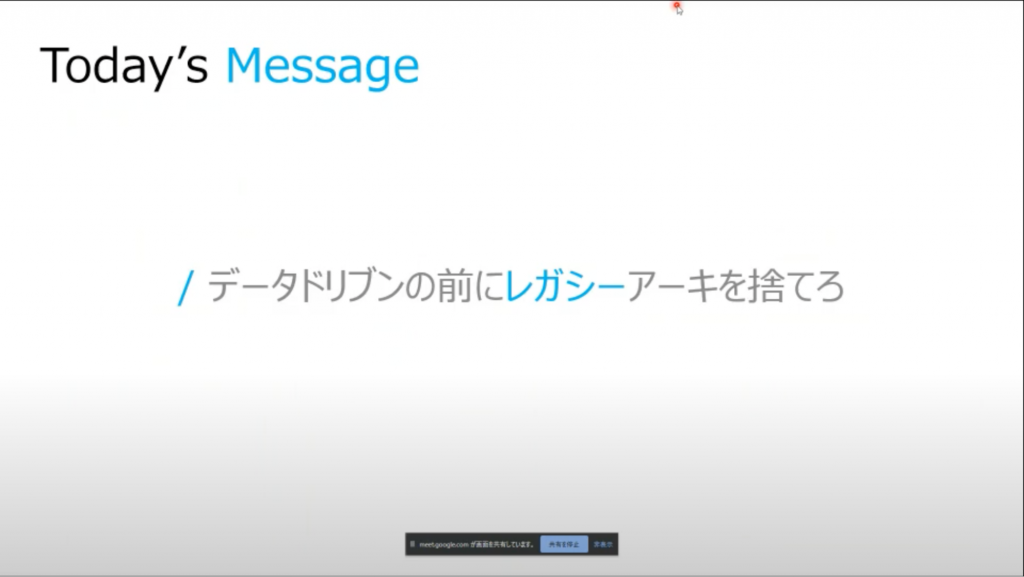
最初に本日のメッセージからご紹介頂きました。
「データドリブンの前にレガシーアーキを捨てろ」
「データドリブンという言葉に振り回されるのではなく、その前にやることはいっぱいある」というところに拘りを持たれているとのこと。実に重みのある、地に足のついた改革をなされてきたことが伺えるメッセージですね!
清水様より、
「データはビジネスから生まれるもの」であってそれを「ビジネスで利用する」というシンプルなサイクルだが、
その間に非常に複雑なITのレイヤーが入っており、「使いたい人がシンプルにすぐ使えない」という課題がある。
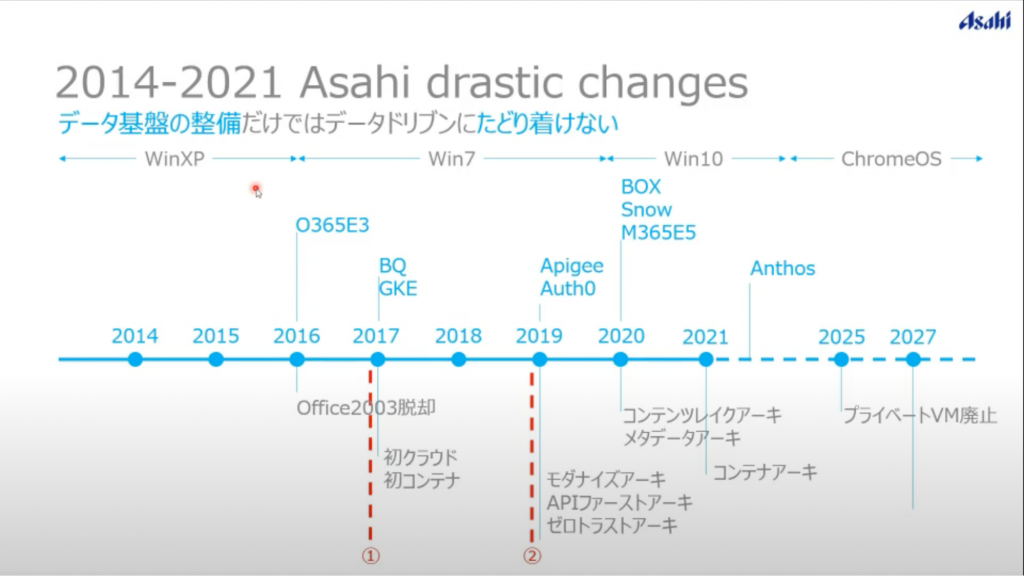
データ活用はBigQueryのようなDWHだけではできなくて、端末環境など含め総合的にデータを使える状態にしてあげる必要があった。
そのような流れで2016年のOffice2003脱却からはじまり、2017年には初のクラウドということで、BigQueryを中心としたGKEアーキテクチャを取り入れたとのこと。
それ以前はほとんどクラウドは利用されておらず、様々なレガシーアーキテクチャの上で何とか凌がれてきたとのこと、ご苦労が伺えます。
また、BigQueryからGCPに入るお話はよく聞きますが、いきなりコンテナ化も含めてというところに並々ならぬ勢いを感じますね!
この2017年がキャズムを超えてきたPOINTで、そこからBigQueryだけでなく、全体のアーキテクチャを1つ1つモダナイズ・充実されてきたとのこと。
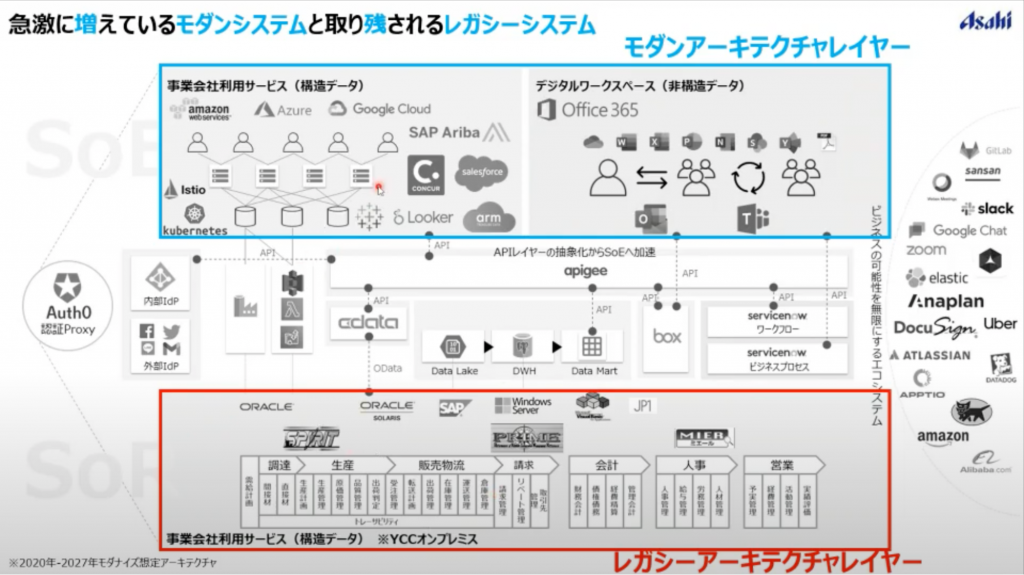
<アサヒモダナイズアーキ>
「レガシーレイヤーを捨てない限り真のデータ活用はできない」という考えのもと、アサヒでは2027年までに社内環境を徹底的にモダナイズしていく構想。
ただし、データセンター運用をしているため、オンプレミスの運用は切っても切り離せない。なので、段階的にモダン化は進めているものの、レガシーアーキテクチャレイヤーとモダンアーキテクチャレイヤーは常に並行稼動することは逃れられない事実とのこと。
そんな中で、間に抽象化レイヤーを持ち、APIを中心とした疎結合な関係を保つ構造を取られています。
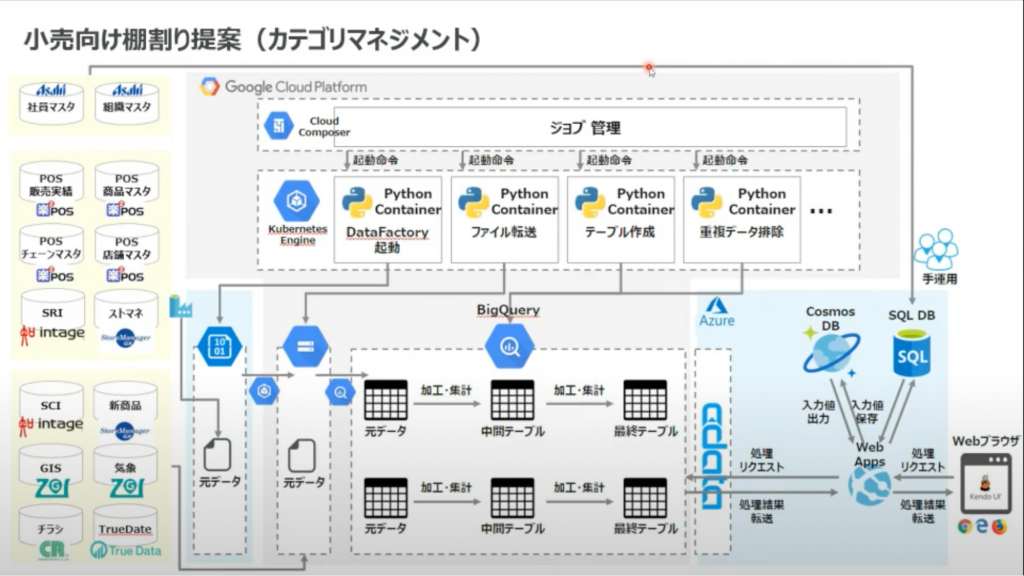
2017年キャズムを超えたきっかけについてお話頂きました。
「小売の棚割りの提案を行って、各店舗の限界利益を引き上げる」というところも行っていて、その中で、データを使って説明をする必要があり、競合商品込みでの棚割り提案をされているとのこと。
POSデータを中心に量販データを全てGKE上のBigQueryで処理されているんですね。
ここがはじめてクラウドにアプリケーションを乗せたポイントで、GKEが公開された年でもあり「やるからにはやったことないことを!」という意気込みで実装されたそうです。
このエピソードからも、「破天荒リーダー」を感じられますね!
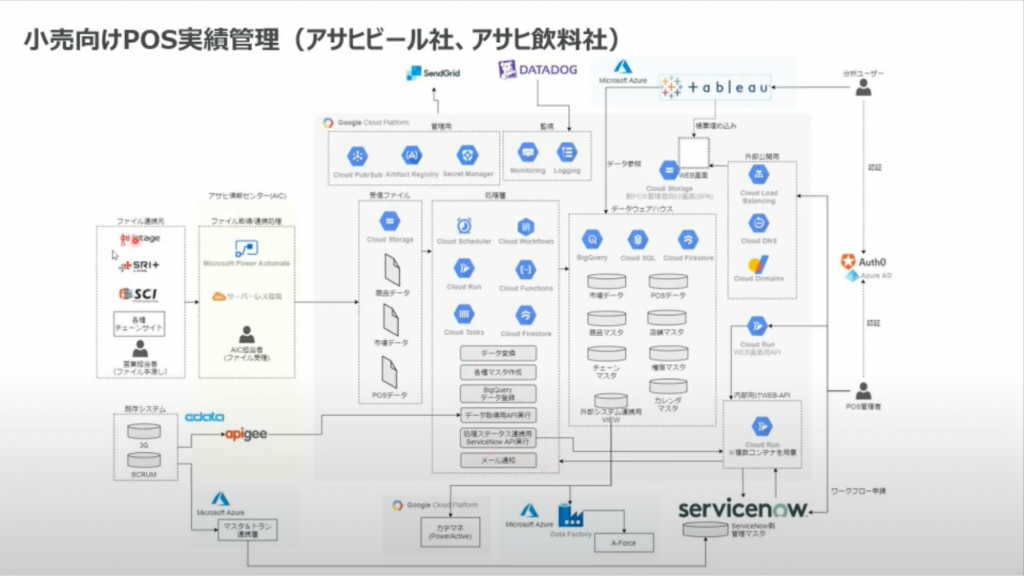
その約3年後、BigQuery中心の1つのアプリケーションから、より全体的なGCPアーキテクチャへ移行。
小売とのデータのやりとりだったり、AWSとのサーバレスな環境で社内のマスタデータをapigeeによりAPI経由でもらったりデータカタログでメタデータを管理したりと、ようやくアーキテクチャ全体が繋がってきたとのこと。
その心は「気持ちよくデータ分析をしてもらいたい」という思いだそう。
分析官の立場からすると感涙もののお言葉ですね。
といった形でレガシーアーキテクチャからモダンアーキテクチャへと変革されてきたアサヒ様。
最後に付け加えられていたのは、テクノロジーは変わっていくことを前提に、1つのテックに依存せず、疎結合な関係でアーキテクチャを構築していきたいとのこと。
清水様、ありがとうございました!
全体を通した感想
今回も前回に引き続き、非常に興味深いセッションと活発な質疑があり、大成功となりました。
個人的な感想として、やはりデータ活用は「ビジネスに基づいた仮説検証の繰り返し」であり、データやリソース、コストといった多くの制約がある中でどれだけビジネスに繋がる仮説を設定し、PDCAを回していけるか、というポイントが改めて重要だなと感じました。
このデータ分科会を通じて、より仮説立案のレベルが上がっていくといいなと思っています!!
次回開催告知!!
次回は
2/17 (木) 12:00 -13:00 Lunch & Learn
での開催を予定しております!!
是非今から予定の確保をお願いいたします!!
また、本記事を読んでいただき「参加したい!」と思っていただいた方も、このタイミングで Jagu’e’r 及び、分科会への参加、また、演題提供大歓迎でございます。
分科会運営のお手伝いをいただける方も募集しています。
イベント登壇者の方には Jagu’e’r ノベルティグッズをプレゼント!
ぜひ、お気軽にお問い合わせください。