
データ利活用分科会 #25_20250130_データカタログL&L イベントレポート
冒頭挨拶
みなさまこんにちは。データ利活用分科会運営メンバの高須賀将秀(Ph.D.)です!
すでに今年も早3か月が過ぎようとしています。今年もデータ利活用分科会をよろしくお願いいたします!
2025年初回として1/30に開催された第25回イベントはランチセッションにて、データカタログをテーマに3名の方にご登壇いただきました!どの演題も非常に素晴らしかったです…!
- ウルシステムズ 松田和雄 様
- フューチャーアーキテクト株式会社 大前七奈 様
- なかむらさとる 様
ありがとうございました!
以下、イベントの模様をお届けいたします。
(西日本電信電話株式会社 / 高須賀将秀)
ウルシステムズ 松田和雄 様
必見!2つのプロジェクトで見えたデータカタログの導入と運用のアンチパターン
まずは、ウルシステムズ株式会社の松田さんが御登壇。
「必見!2つのプロジェクトで見えたデータカタログの導入と運用のアンチパターン」と題した講演が行われました。データカタログの導入が必ずしもデータ活用を促進するわけではないことを、過去の2つのプロジェクトの失敗談を交えて説明しました。
A社の事例
A社では、有名なデータカタログ製品を導入したものの、結果的に誰も利用しなくなった事例をご紹介されました。利用されなくなったのは、データカタログを導入したあと、提供している環境のコンセプトが変更になったことが主な原因でした。
環境の初回リリース時は、グループ会社間のデータ共有を想定していたのですが、途中で自社/自部門のデータしか扱わなくなったため、データカタログがなくてもデータの把握に困らなくなってしまいました。
また、利用者が自分でメタデータを登録するセルフサービス方式を採用しましたが、データカタログの利用促進に繋がるような動機付けがなかったため、メタデータが登録されませんでした。
B社の事例
B社では、テーブル定義書と実データの不一致や、データの素性を聞ける担当者が不在などの問題が発生しました。 そのため、データカタログで提供すべきビジネスメタデータ(業務観点でのデータの意味合い)を作成することができませんでした。
また、メタデータの記載ルールの整備にも多大な労力が必要となり、1人月から2人月を要しました。 記載ルールなしで個人のドキュメンテーション能力にメタデータの記載方法を委ねると、記載の粒度や精度、わかりやすさにバラつきがでてしまいます。選択形式レベルで記載内容を統一しないと、見てもわからないメタデータとなって意味がなくなってしまうのです。
データカタログ導入前にやるべきこと
これらの失敗談を踏まえ、データカタログ導入前にやるべきことを3点挙げました。
1. 導入のタイミングを見極める
データカタログは、利用者のニーズやデータの利用状況を正確に把握した上で導入する必要があります。日常的に扱うデータや、業務や分析で困っていないデータの場合は、データカタログがなくても問題ありません。
2. 導入前に必要な情報を揃える
メタデータに記載する情報は、事前に揃えておく必要があります。情報が不足している場合は、事前に収集する算段を立てておく必要があります。
3. 導入後の運用を具体化する
データカタログは、導入後の運用が重要となります。メタデータのメンテナンスを担う人と、そのメリットを明確にし、メタデータの品質を向上させていく必要があります。
また、メタデータの記載ルールを策定し、メタデータの記載内容を統一する必要があります。
まとめ
データカタログの導入は、事前の準備と計画が重要です。利用状況やニーズ、メタデータの情報などを事前に確認し、導入後の運用体制を構築することで、データカタログを有効活用することができます。
フューチャーアーキテクト株式会社 大前七奈 様
次に フューチャーアーキテクト株式会社 大前さんが御登壇。
データカタログは、自律分散組織を円滑に進める上で重要な役割を果たします。
データの所在と管理を分散化
データカタログは、データの所有権とマネジメントを分散化することに重点を置いたアーキテクチャ(データメッシュ構造)において、中心的な役割を担います。
個人的には、データカタログはマッチングアプリのように「データがほしいユーザー」と「データを提供するユーザー」が自由に出会える場づくりだとも考えております。
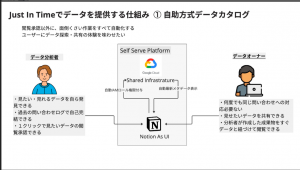
必要な時に必要なデータをすべてのユーザーに提供 (Just In Time)
データカタログの価値としては、ユーザーにリアルタイムに情報を提供できる仕組みを可能にすることにあります。さらに日本の労働人口が日々減少し、定型の運用作業に人員を割けなくなっていくなかで、データを探したいユーザーのニーズだけでなく、データを提供したいユーザーやデータを管理する統制部門、システム部門のニーズも今回のアーキテクチャで考慮されております。
ユーザーにデータ探索と共有の体験を提供
データカタログの陳腐化を防ぎたいために、定型作業のような「面倒くさい」ことを自動化させつつ、ユーザーにデータ探索・共有の体験を提供するかが今回のコンセプトとなります。
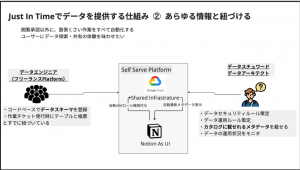
あらゆるメタ情報と結びつける
自助プラットフォームの中で、フリーランスのデータエンジニアがコードベースで書いたデータスキーマ、いわゆるデータのメタデータのみならず、データスチュワード/データアーキテクトが定めたテーブル権限定義や運用ルール、定期的に集計されるユーザー利用状況などあらゆる情報もこの自助プラットフォームによって、各データ関係者がプル型で情報を取得するようになります。
※フリーランスプラットフォームの活用について、別の記事を参考していただけるとうれしいです(リンク:https://future-architect.github.io/articles/20241029a/ by フューチャーアーキテクト 高瀬陸)
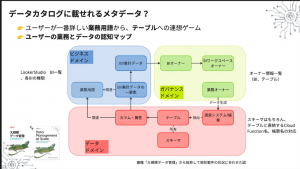
ユーザーの業務とデータの認知マップ
また、ユーザーによってどうしても職種や今のIT経験にばらつきがあるため、そういった性質を持ったユーザー群に対して、ユーザーが一番詳しい業務用語からテーブルへの連想を可能にし、ユーザーの業務とデータの認知データマップを提供します。
それに加え、ITリテラシーによってポータルサイトの入口を細分化するよう工夫しております。
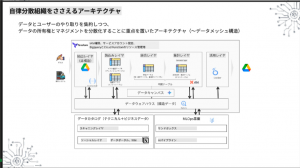
自律分散組織を支えるアーキテクチャ
データカタログの自動処理レイヤについては、スキャニングレイヤとソーシャルレイヤで構成され、GCP内の情報を取得して表示したり、UIからの変更をBigQueryに反映したりできます。今回は、ユーザー側では既存のグループウェアNotionをすでに利用されていることに加え、複数軸で情報のビューを表示できることもあり、そのままデータカタログのUIとして採用することになりました。
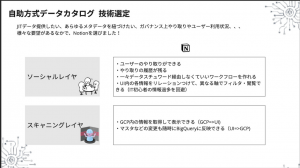
以上が今回の自律分散組織をささえるアーキテクチャとそのポイントを紹介させていただきました。なにかヒントになれたら幸いです!
全体を通した感想
今回も前回に引き続き、非常に興味深いセッションと活発な質疑があり、大成功となりました。
個人的な感想として、やはりデータカタログは「データがほしいユーザー」と「提供するユーザー」を結ぶマッチングの場として重要であり、成功には、明確な導入目的の設定、事前の情報収集、メタデータの記載ルール統一、導入後の継続的な運用体制が不可欠である、と改めて感じました。私も日々奮闘しているため、このような皆様と共有できる場をなるべくたくさん設けたいと思います!
次回開催告知!!
次回は
3/28 (金) 12:00 -13:00 Lunch & Learn
での開催を予定しております!!
是非今から予定の確保をお願いいたします!!
また、本記事を読んでいただき「参加したい!」と思っていただいた方も、このタイミングで Jagu’e’r 及び、分科会への参加、また、演題提供大歓迎でございます。分科会運営のお手伝いをいただける方も募集しています。ぜひ、お気軽にお問い合わせください。