
O11y-SRE 分科会 Meetup#7 開催!「開発者に捧げる Site Reliability Engineering」

みなさん、こんにちは、O11y-SRE分科会です!
2024 年 4 月 26 日に「開発者に捧げる Site Reliability Engineering」を開催しました。
O11y-SRE 分科会としては通算第 7 回目の Meetup ではあるのですが、今年は新たな体制で本分科会を運営することから「Reboot」を大きなテーマとして盛り上げていきたいと思っています。
そんな通算第 7 回目/Reboot 第 2 回目である本 Meetup は上記のテーマで開発者であるならぜひ知っておきたい SRE の基本を基調講演・LT で学ぶ場となりました。
目次
LT1.オブザーバビリティを民主化してコア分析ループを加速したい話
スピーカー:Datadog Japan 合同会社 逆井 啓佑さんLT2. データベースにプログレッシブデリバリーを導入しよう
スピーカー:株式会社スリーシェイク 中楯 直希さんLT3.Cloud Profilerで探る!見えなかったボトルネックの解消法
スピーカー:コミューン株式会社 川岡 潤さんパネルディスカッション
スピーカー:
グーグル・クラウド・ジャパン合同会社 山口 能迪さん
Datadog Japan 合同会社 逆井 啓佑さん
株式会社スリーシェイク 中楯 直希さん
ファシリテーター:Datadog Japan 合同会社 木村 健人
Reboot から運営メンバーであり新たにオーナーとなったメンバーの紹介です!
- Datadog Japan 合同会社 木村 健人
- 株式会社スリーシェイク 横尾 杏之介
- NTTコミュニケーションズ株式会社 林 知範
- グーグル・クラウド・ジャパン合同会社 中谷 祐輔

Reboot 後の初めてのハイブリッド開催ということで運営一同気合い入れて開催にあたった Meetup でした!
ここでは各 LT の振り返りを記載していますので、ぜひご覧ください!
(NTTコミュニケーションズ株式会社 / 林 知範)
Keynote. SREとエラーバジェット
基調講演として、グーグル・クラウド・ジャパン合同会社の山口さんからご講演いただき、「SRE とエラーバジェット」というタイトルでサービスを運用する際の SLI/SLO の設計の話やエラーバジェットの捉え方・考え方についてお話しいただきました。
資料は会社ポリシーによる展開が難しいとのことでこちらの内容はオンサイト参加限定となっています。
( 株式会社スリーシェイク / 横尾 杏之介 )
LT1. オブザーバビリティを民主化してコア分析ループを加速したい話
2 人目の登壇者は当時 Datadog Japan 合同会社 にジョインしたばかりの逆井さん(@k6s4i53rx)から「オブザーバビリティを民主化してコア分析ループを加速した話」というタイトルでご登壇いただきました。
資料リンク:https://speakerdeck.com/k6s4i53rx/trace-log-correlation-on-google-cloud-observability
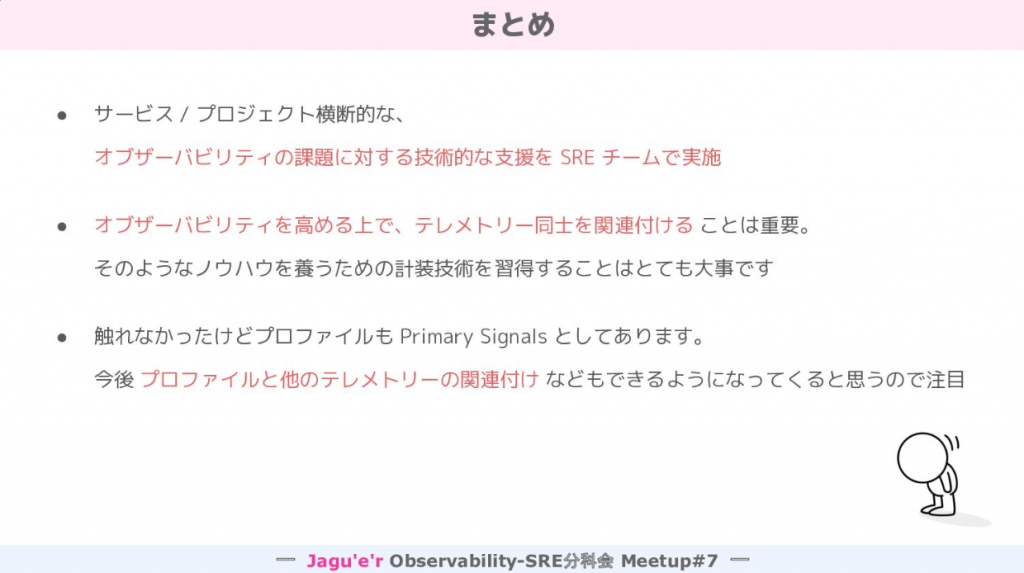
まずはイントロダクションとして、オブザーバビリティとは何者かやオブザーバビリティがあると何が嬉しいのかについて説明いただきました。その中でも障害発生時に経験豊富なベテランメンバー = 仙人のような存在がいるとありがたい一方でそういった仙人以外のメンバーでデバッグできない状況は好ましくないという点には強く共感できました。
だからこそ、事実を起点としたコア分析ループを回せる/回せる状況を作ることでオブザーバビリティを高めていくことが重要であるというお話しでした。

では、どうやったらコア分析のループを回せる状況を作ることができるのか?というところが気になっていると「コア分析ループを回すための情報は自動で集まってくるわけではない」「情報量の高いテレメトリーを収集するために計装をサービスに行う」「素早くループを回すためにテレメトリー同士の関連付けをして計測する」というポイントを伝えていただきました。
また、逆井さんの経験談から「大規模 PJ や複数チームにおいて、チーム間のオブザーバビリティ格差が課題になりがち」という話もありました。こういった格差をなくすために、「チーム横断的課題に対して横串で課題解決を行い格差是正を図っていくような動き」を SRE という立場で取り組まれたとのことでした。

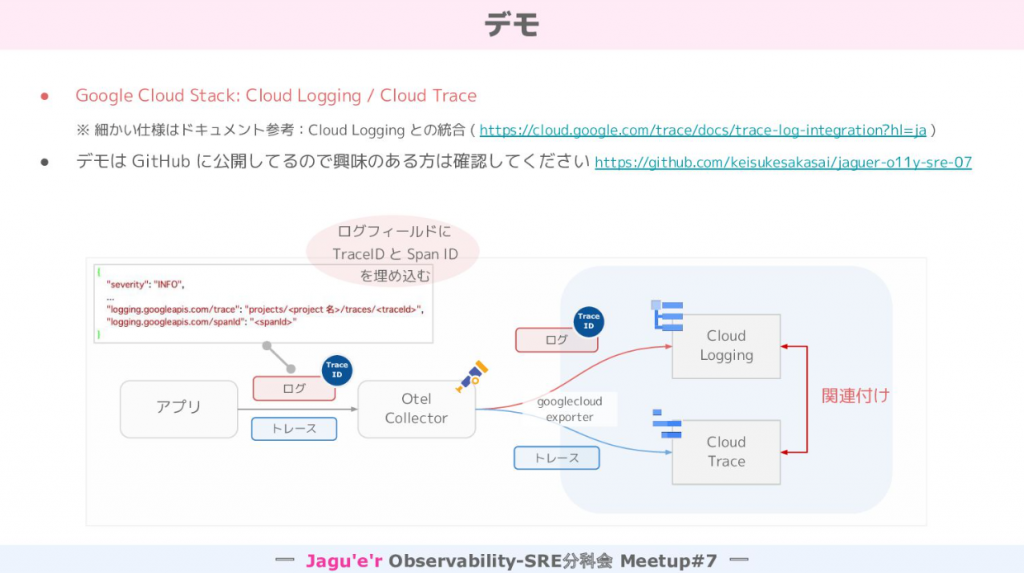
実際にどういったことに取り組まれたか非常に気になる内容でしたが、今回は「テレメトリー同士の関連づけを Google Cloud Observability で実現するには?」という点を次にお話しいただきました。
その場でお見せいただいたデモは Cloud Trace で表示されるスパンにログが紐づいているというものでした。ログのフィールドに TraceID と SpanID を埋め込むのみで Cloud Logging で見ていたログが Cloud Trace で表示されるスパンからも見れて、コア分析ループを回すのに役立つということで実際の画面が見れてイメージがついたことで私自身非常に勉強になりました。
最後に発表内容をまとめていただいた中でも「プロファイルと他のテレメトリーの関連付け」というところにも今後注目していきたいとのことで、本 Meetup のLT の最後を飾るコミューン株式会社の川岡さんのプロファイルに関連した LT が楽しみという話で締めていただきました。
私自身、OpenTelemetry に入門したての頃だったのですぐにでも試したい内容で非常にワクワクしながら聴講させていただきました。
逆井さん、ご登壇ありがとうございました!
(NTTコミュニケーションズ株式会社 / 林 知範)
LT2. データベースにプログレッシブデリバリーを導入しよう
3 人目の登壇者は、株式会社スリーシェイク(以下、3-shake)の中楯さん(@nnaka2992)から「データベースにプログレッシブデリバリーを導入しよう」というタイトルでご登壇いただきました。
中楯さんは 3-shake で私と同僚なのですが、「DB が異常に好きな人」として社内でも DBRE として大活躍しています!
ちなみに・・・3-shake 社内には、DBRE の人に気軽に DB 関連のことを質問できる「ask_dbre」という Slack チャンネルがあるのですが、DB に限らず、BQ などデータ周りのことをなんでも教えてくれる本当に素晴らしい取り組み(福利厚生と言っても良いのでは?)をしてくださっています!(いつもお世話になっています🙏)
資料リンク:https://speakerdeck.com/nnaka2992/detabesunipuroguretusibuderibariwodao-ru-siyou

まず、そもそも DB におけるプログレッシブデリバリーとは何かということをご説明いただきました。
大きな違いとしては、ステート持つということから壊れた場合にアプリよりも復旧までのリードタイムがかかることから、データベースこそ堅牢かつ安全なプログレッシブデリバリーをすべきでは?と提言されています。
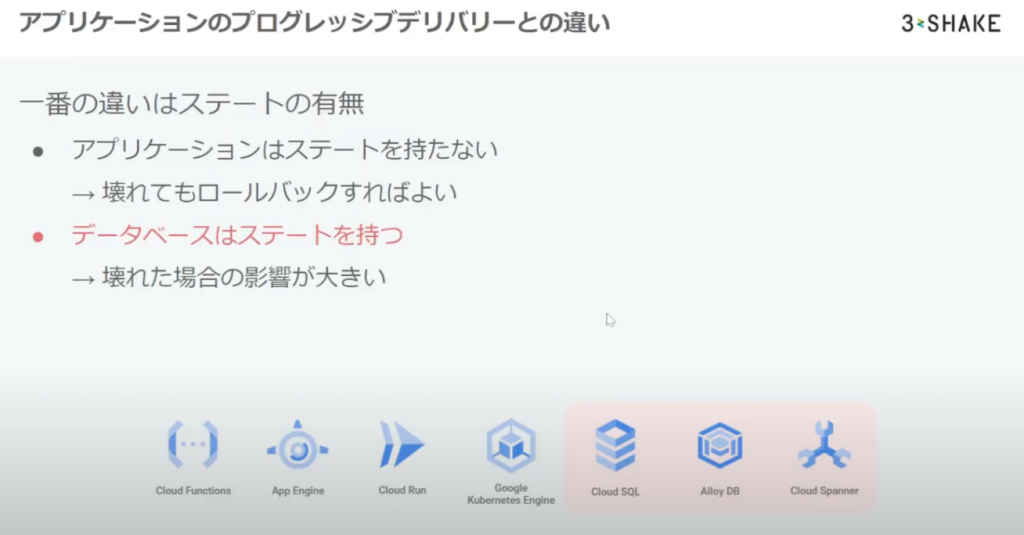

では実際に DB における変更とは?ということで大きく 2 方式あるようです。
インプレースアップデートとブルーグリーンアップデートで、このあたりのアプローチの仕方はアプリケーションインフラのプログレッシブデリバリーと変わらず、DB においても同様の考え方で実現できるようです!

今回は、ブルーグリーンアップデートを例に出して詳細な実現方法を紙芝居形式のスライドでわかりやすく紹介してくださいました!
また、今後の Google Cloud のアップデートに期待する部分として、マネージドなブルーグリーンアップデートのサポートも実現して欲しいという DBRE ならではの視点から提言も飛び出し、会場は笑いにつつまれていました😂

私自身、普段は GKE をはじめとするワークロードでのプログレッシブデリバリーしか経験がなかったので、DB こそプログレッシブデリバリーをすべきという今回の登壇内容はすごく新しい知見となりました!
中楯さん、ご登壇ありがとうございました!
( 株式会社スリーシェイク / 横尾 杏之介 )
LT3. Cloud Profilerで探る!見えなかったボトルネックの解消法
本 Meetup 最後の LT はコミューン株式会社の川岡さん(@mongamae_nioh)から「Cloud Profiler で探る!見えなかったボトルネックの解消法」というタイトルでご登壇いただきました。Cloud Native Days の実行委員や町内会のデジタル担当であったりと公私共にコミュニティ中心の生活をされているという印象的な自己紹介がありました。
資料リンク:https://speakerdeck.com/mongamaenioh/cloud-profilerdetan-rujian-enakatutabotorunetukunojie-xiao-fa

まずは、今回の LT の主役でもある Cloud Profiler の概要です。公式ドキュメントから文章を引用しつつ「継続的プロファイリング」が可能なサービスであり「本番環境で実行中のアプリケーションプロファイリングする」ということを説明いただきました。

また、「継続的プロファイリング」は Pyroscope という OSS のツールの紹介記事の中ではオブザーバビリティの 4 本目の柱として記載されているとのことです。
Cloud Profiler の説明の中にもある「本番環境アプリケーション」で「オーバーヘッドの少ないプロファイリングが可能」というところがポイントだと思っているとおっしゃっていて、「本番環境でオーバーヘッドが少なくプロファイリングできるのであれば初期から導入してパフォーマンスを改善する」というのがCloud Profiler を含めたプロファイラの共通思想なのではというお話しがありました。

私自身、Cloud Profiler の存在は知っているものの使ったことはなく、プロファイラの思想や何ができるのかを知る機会となり、非常に勉強になりました。
次に実際の事例についてお話しいただきました。Cloud Profiler から想定よりも処理に時間がかかっているものを見つけることができたものの、なぜ時間がかかっているのかは Cloud Trace を見てもわからない状況だったそうです。
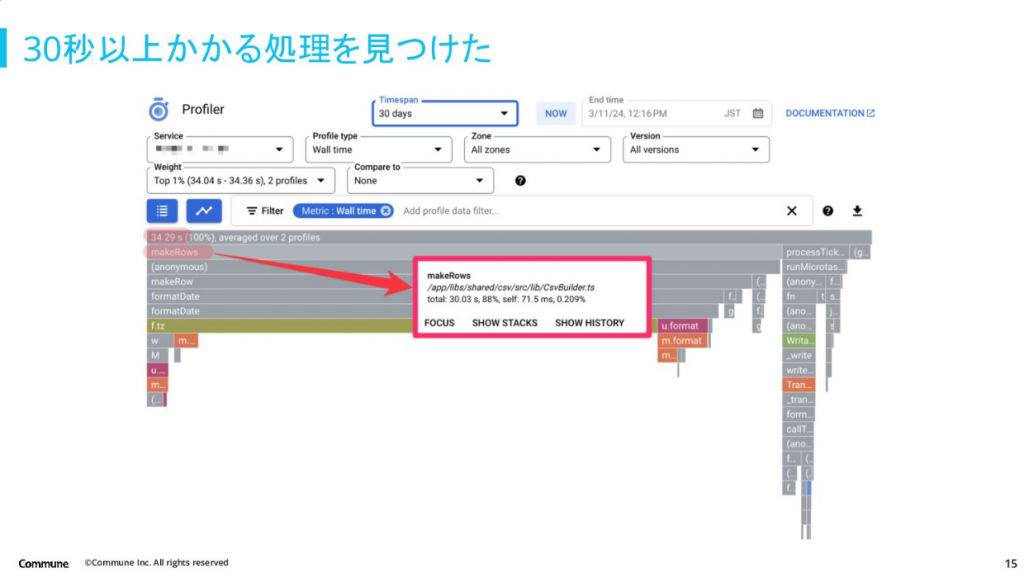
もう少し深く Cloud Profiler を見たところ、処理に時間かかっているものの中でも日時情報をフォーマッティングしている処理に時間がかかっていることがわかったため、該当の処理をスキップするような形で検証したところ処理時間が 1/3 になったそうです。このことから仮説は正しいことがわかったため、打ち手を考えることができたとのことです。
結果としては、フォーマッティングの処理をするライブラリを変更することで下図のように処理時間の短縮を実現できたようです。めでたしめでたしとなるのかと思いきや、最後に Cloud Profiler の困りごとにも言及いただきました。

Cloud Profiler で表示するプロファイルが 1 つであればボトルネックを見つけやすい一方で、プロファイルが多いと情報が圧縮されたり表示上見づらかったりとボトルネックを見つけにくい点を困りどころとして挙げてました。
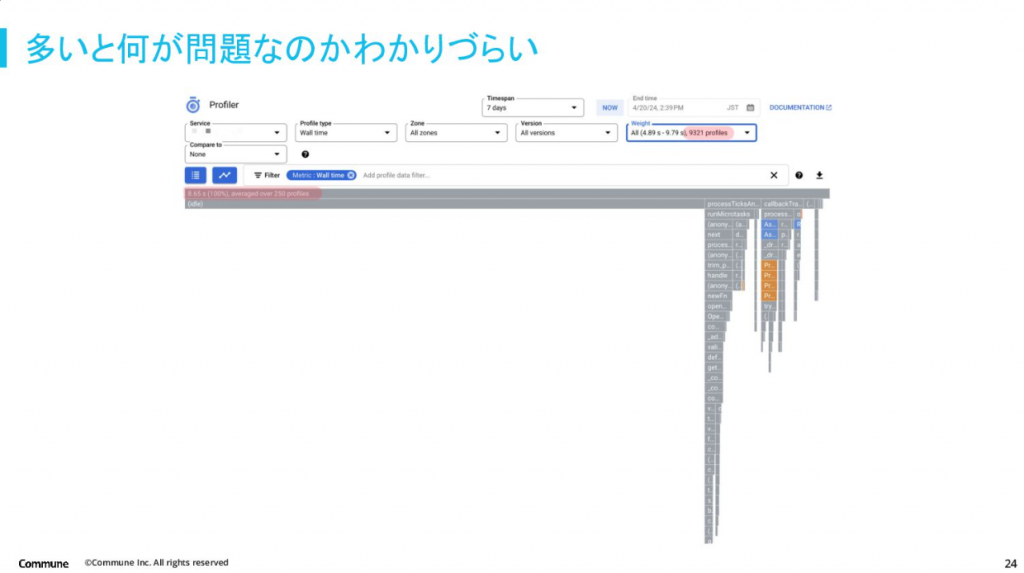
Cloud Profiler や継続的プロファイリングに関する概要から事例紹介、そして困りごとまで聴講するだけでも Cloud Profiler を身近に感じられる素敵な LT だったと感じました。
川岡さん、ご登壇ありがとうございました!
(NTTコミュニケーションズ株式会社 / 林 知範)
パネルディスカッション
本 Meetup の最後にはご登壇いただいた以下の方々から、まだまだ SRE の活動を始められていない開発者に向けて SRE について自由にお話いただくパネルディスカッションをお送りしました!
- グーグル・クラウド・ジャパン合同会社 山口 能迪さん
- Datadog Japan 合同会社 逆井 啓佑さん
- 株式会社スリーシェイク 中楯 直希さん

背景もご経験も様々なお三方ですが、それぞれのテーマについてお話しいただき、Google でオブザーバビリティ周りを中心に Developer Relations をされている山口さんにまとめていただくという形で進行しました。
ここではその一部を抜粋・再編集して、お話しした内容をご紹介します。

まず初めのテーマは「何したら「SRE やってる」ってなる?」です。
かなりざっくりしたテーマですが、正解のない個々人の主観に委ねられる面白いテーマです。
中楯:DBA(データベース管理者)寄りなので、他の方とは違うかもしれませんが、開発者をブロックする役割からブロックしない活動が SRE / DBRE の肝になってくると思います。具体的には、従来は DB のアップデートは停止時間を取るなどリスクを取らない手法が一般的だったが、昨今はオンライン DDL や B/G をはじめとする機能が利用できるようになりこれらの知見などを広めています。SRE / DBRE 本にも、DBRE は開発者向けの DB 情報のハブ・キュレーターになるという内容があり、それを参考にしています。
山口さんにはこの中楯さんの活動を、SRE のプラクティスの1つである「文化の共有」という観点でまとめていただきました。
山口:これから導入するとなるとインフラチームを SRE としても文化が共有される訳ではないんです。SRE の考え方は開発・ビジネスに携わる方々も理解していないと価値が生まれないため、それぞれのチームがやり方や考え方をリードしていく活動が必要となっていくのではないでしょうか。
逆井:綺麗なプラクティスの実践ではなく、サービスチームが取りにくい全体的な課題を潰していく活動をしていて、現場特有の課題を特殊な事情に即して解決するための動きが SRE の動き方の一つだと個人的には考えています。過去に関わっていた決済系のサービスは性能が求められるため、性能改善のためオブザーバビリティを啓蒙していました。オブザーバビリティは直接的に顧客に届く価値ではないため、現場を説得して開発スケジュールに組み込むことが難しかったですが、長期的には性能改善につながる/開発生産を高めるため推進をしていました。可用性の面でも、カオスエンジニアリングなどの新しいプラクティスを浸透させていくことに力を入れていました。
逆井さんの SRE 活動はオブザーバビリティの推進が中心でしたが、初心者が SRE を始める上でどのプラクティスを重要視すれば伝わりやすいのでしょうか。
山口:オブザーバビリティソリューションは導入すれば何かしらのわかりやすい効果が出るため、とりあえず計測して改善するということを体現するという面ではわかりやすいと思います。ただ、導入するにもお金がかかるためできない場合はできるプラクティスをやってみるのも良いと思います。「非難のないポストモーテム」の例では、障害がなくても他サービスの公開されているポストモーテムの輪読や過去の障害の振り返りをしてみるなど、考え方を取り入れてみるなどできることはたくさんあります。

中楯:DB のリリースフローが煩雑だった際に再現性が低い運用だったところ、Git を利用した運用の自動化を行い再現性の高い運用へ改善しました。NoSQL や Spanner の登場前は、アプリケーションと比較して DB はボトルネックとなりやすいため、様々なプラクティスが積み重なってきていました。そういったプラクティス自体に目新しさはなかったのですが、DBA の動きとは異なり自動化は開発者の方々が DB に触れて生まれたため、こうした活動を例に出しました。
ここで山口さんに DBRE という役割の背景について伺いました。
山口:Google 内では Sppaner の様に DB サービス自体を担当する SRE がいるため、 SRE / DBRE のように分かれてはいません。一方で、DB については歴史が長く専門の知識・プラクティスが必要となるため DBA かつ SRE な方々が DBRE という言葉を定義していったのかなと思います。SRE / DBRE は本質的には同じですが、DB は既存のリリースされている製品を利用するため知見や実践する内容に違いが生まれます。
逆井:一例として、Kubernetes の API で利用されている機能が非推奨になることがあるため、初めはこうした機能を利用していないかを泥臭く手作業で確認していました。こうした活動を Pluto などの OSS を利用して、自動化・オーナーシップの開発チームへの移行を行いました。
「Toil の撲滅」や「自動化の推進」など複数のプラクティスが相互に関連している良い例をお伺いできました!
実は3つ目のテーマもありましたが、時間の都合上今回は割愛となりました…
ただ、2つのテーマからも十分に具体的なお話とそれをプラクティスに落とし込んだまとめをお伺いできました!
(Datadog Japan 合同会社 / 木村 健人)
クロージング
以上で、Meetup#7 終了となります!
グーグル・クラウド・ジャパン合同会社の渋谷オフィスをお借りしたハイブリッド開催の「Reboot」から 2 回目のイベントでしたが、現地に 20 名・オンライン 20 名と非常に盛り上がったイベントなりました。
今後のイベント情報はこちらの Connpass からも発信していきますので、ぜひメンバーになっていただけたら嬉しいです。
では、次回の Meetup#8 でお会いしましょう!!
(NTTコミュニケーションズ / 林 知範)