
活動報告: データ利活用分科会 第19回イベントレポート
みなさまこんにちは!
冬がとても長く感じましたが4月に入り春らしい気温になってきましたね。
本稿は、冬真っただ中の2月15日に開催されたデータ利活用分科会 #19 Data Journey の模様をお届けします。今回は「データ収集」にフォーカスしました。データ利活用のまさに基本の「き」であり、最重要と言っても過言ではないデータ収集について、wywy 遠藤様、Red Frasco 杉山様、メビウス 高橋様 、矢野様、Google Cloud 梅川様にLTで事例を発表していただきました。貴重なお話もたくさん語られましたので是非みなさん参考にしてください。それでは、今回のご発表を紹介したいと思います。
(TD SYNNEX株式会社 / 吉川洋太郎)
目次
「製造業のデータ分析支援での体験」wywy 遠藤様
「不動産情報サイトにおけるデータ収集で頑張ったこと」Red Frasco 杉山様
「データの鮮度の重要性」株式会社メビウス 高橋様 / 矢野様
「データ利活用分科会#19 データ収集編」 GoogleCloud 梅川様
所感・まとめ
演題紹介
「製造業のデータ分析支援での体験」
wywy 遠藤様
最初の発表者は、wywy 遠藤さんです。
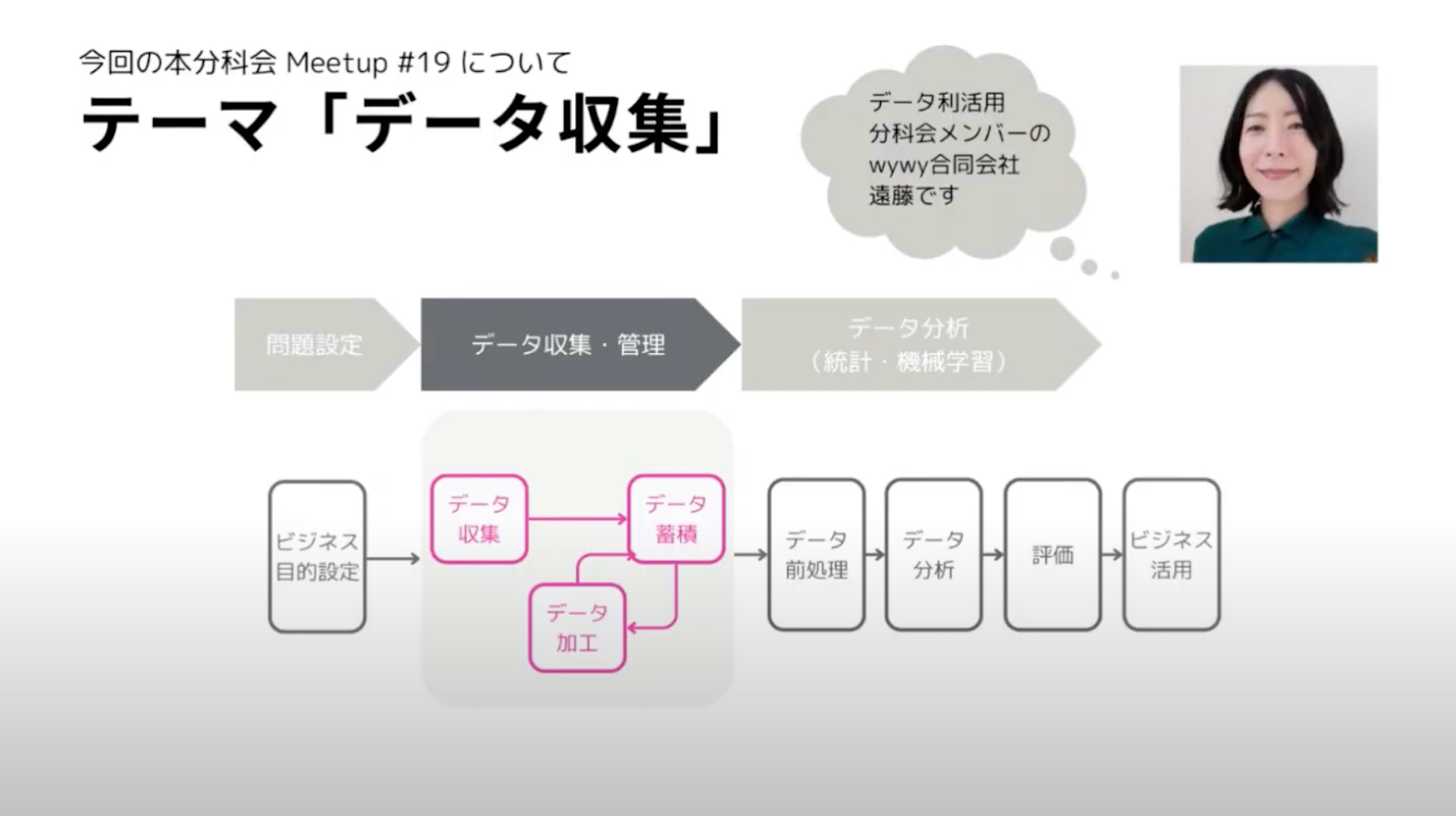
遠藤さんはこのデータ利活用分科会のメンバーでもあり、どうして今回「データ収集」をテーマにしたミートアップが開かれたのか、というところからお話してくださいました。

2024年のデータ利活用分科会は、「Data Journey」シリーズを実施することで、上の図にもあるようなデータ利活用の様々なフェーズに焦点を当て、それぞれの場面におけるナレッジを分科会に蓄積していきたいとのことです。
今後のデータ利活用分科会のイベントも楽しみですね!
さて、遠藤さんが実際に体験した、データ収集についてのお話に入ります。遠藤さんがデータ収集に関わったのは、製造業のお客様に対してデータ分析支援を行った際のことでした。例えばデータ分析によって解決したい課題の設定、課題への仮説立案、トレーニングの実施などなどを実施する中で、当然データ収集を行う場面があります。
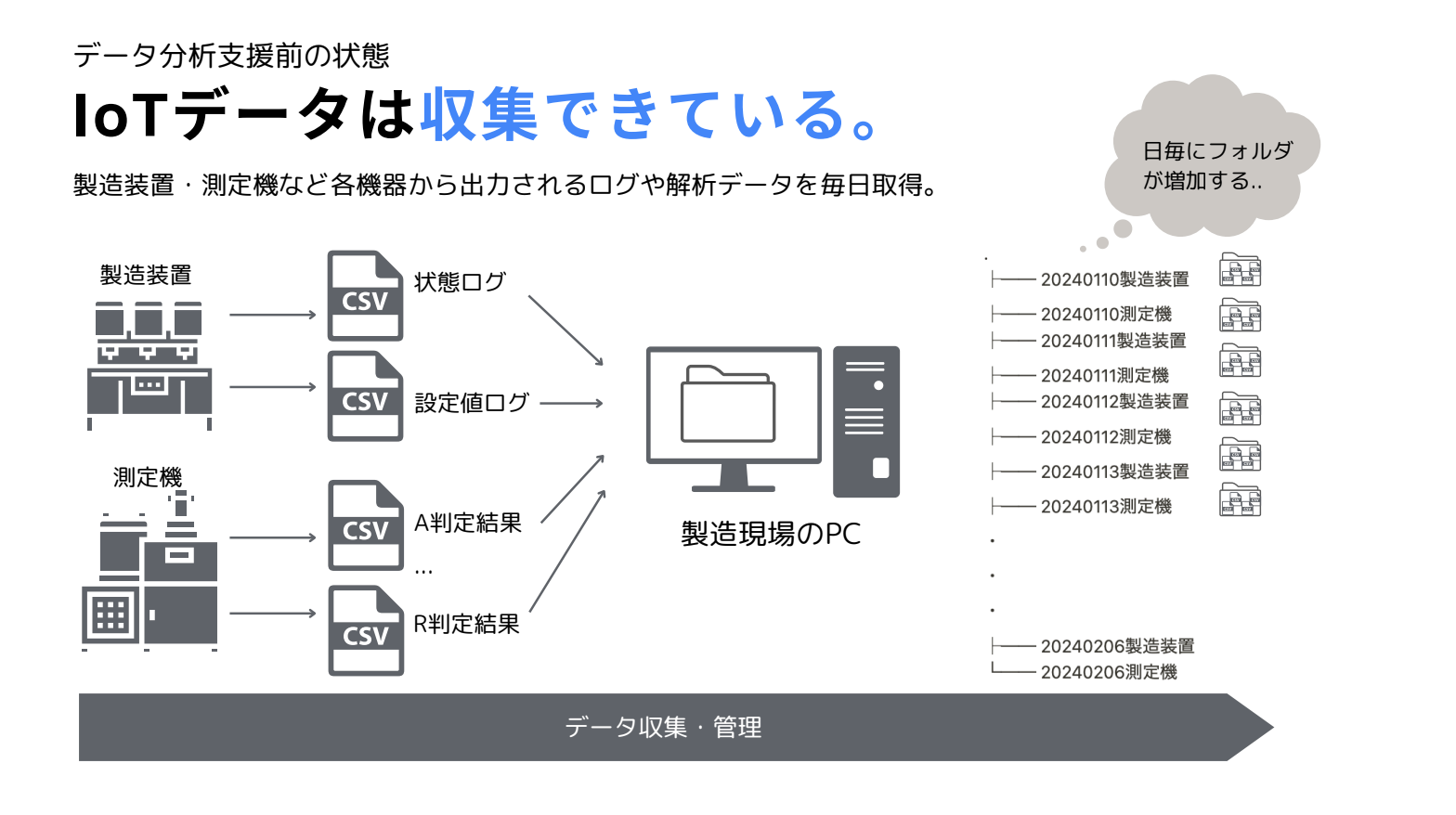
遠藤さんが関わったケースの場合、製造業で使用する様々な機器から発生するデータを収集はできていたものの、それらデータのファイルが毎日毎日増えてくるので、管理がとても大変になってしまっていました。個人的に似たような経験をしたことがあったので、この話を聞いていた時は「あるある……」と思っていました。
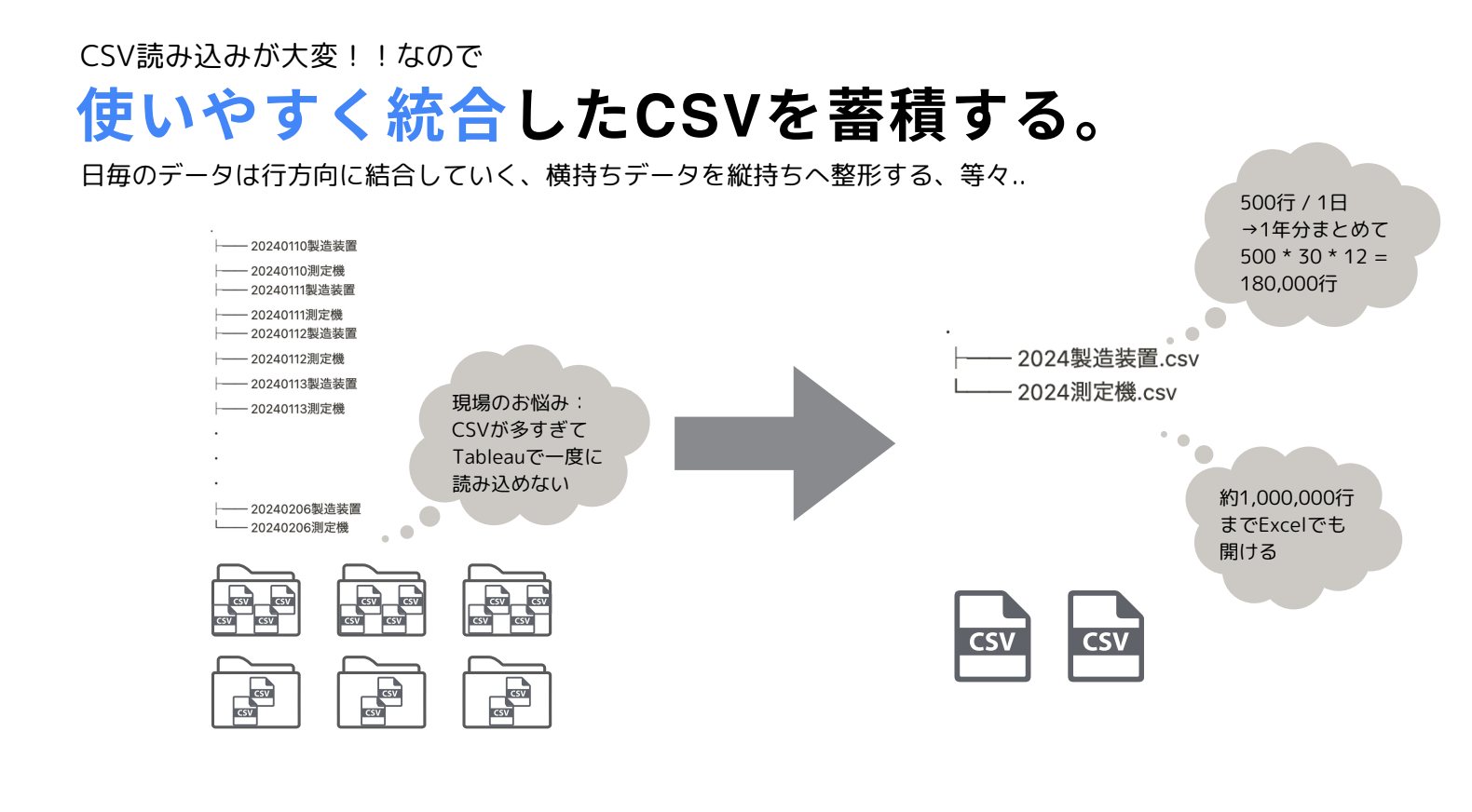
遠藤さんは現場の方々の困りごとを踏まえ、これらのそのままだと扱いづらいファイルを加工し、データ分析などの後工程で使いやすいデータを蓄積していくことから始めたそうです。
こうしたデータ加工において、特に以下の 3 つのタスクをご紹介いただきました
- 整理: CSV の解読
- 統合: データの結合
- 診断: データと現場感覚のすりあわせ
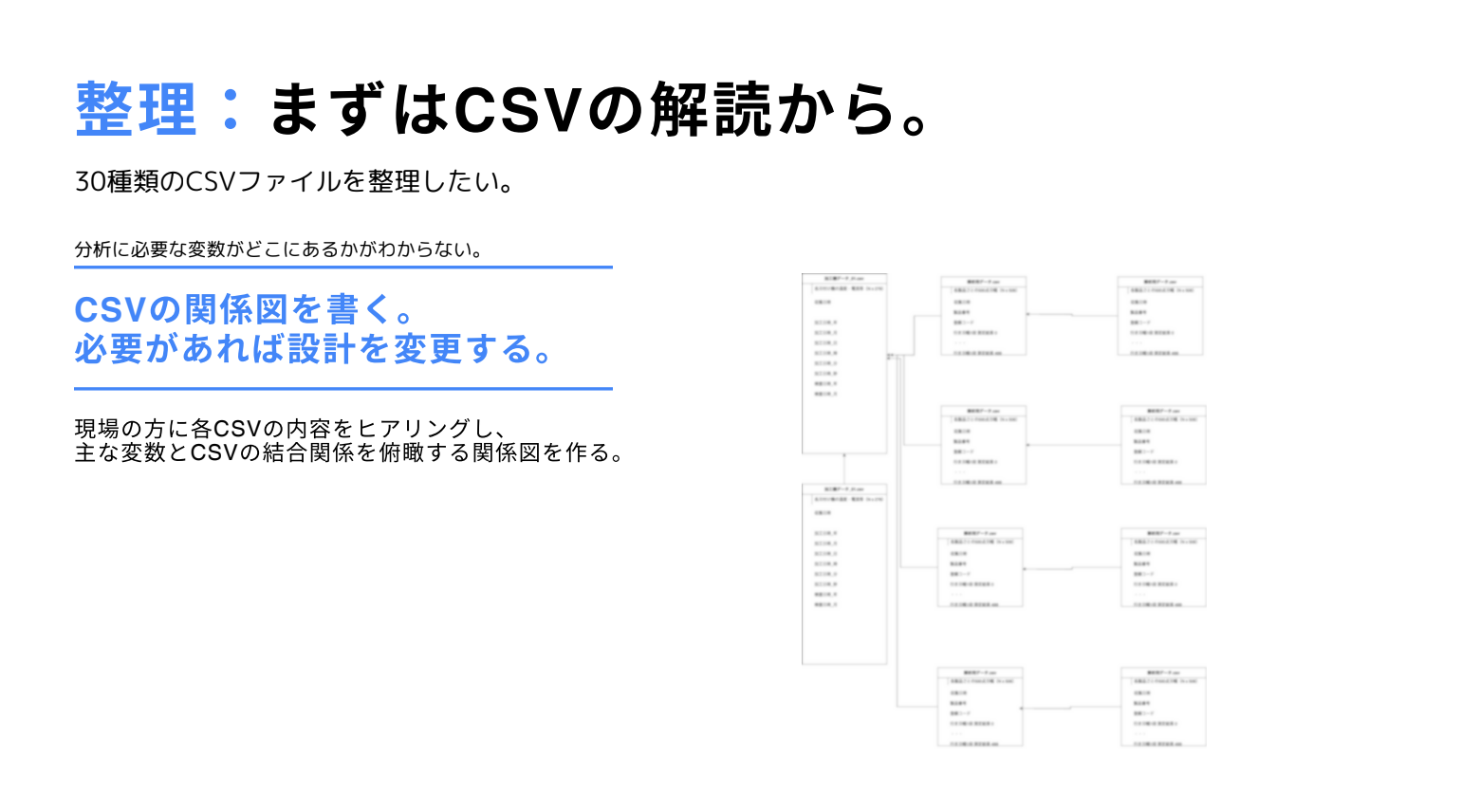
多種多様な機械が生成する CSV ファイルを整理し、分析に必要な変数はどれなのかを絞り込んでいくこと。これが整理となります。その際に作成されたのが、上図の CSV の関係図となっています。
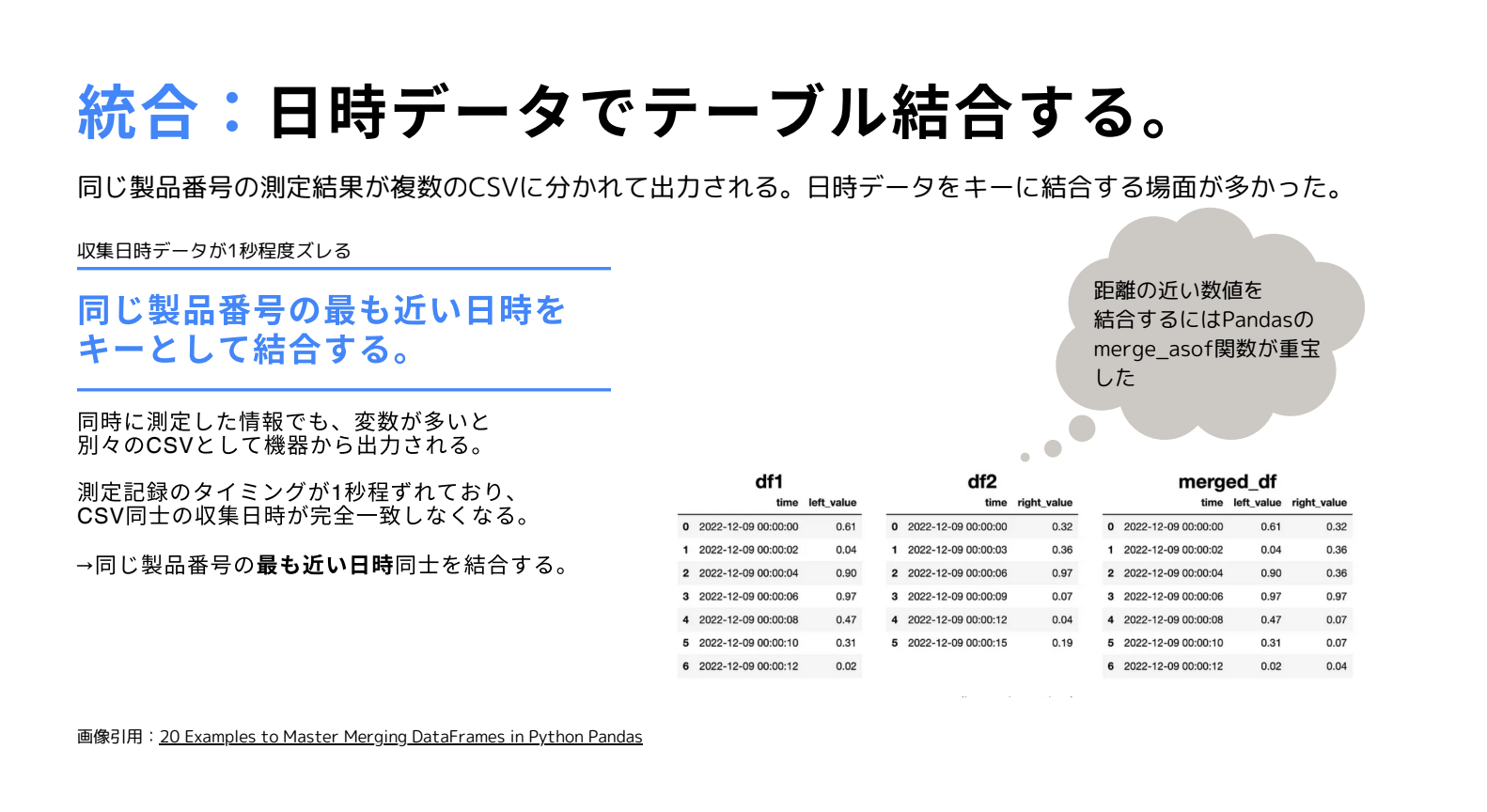
次にご紹介があったのは統合です。同じ製品番号に対する測定結果データを結合していく作業となります。機械によっては同一データが同一時刻に生成されていないなど結合に対する困りごともありましたが、Pandas 等のライブラリを使って同じ製品番号の最も近い日時同士のデータを結合できたとのことでした。

最後が診断です。判定データによれば不良品率が 80% なのに、現場の感覚では 1% 未満というふうに、機器が判定した結果のデータと現場の感覚がずれてしまった時のことでした。現場と相談しながら数値の出し方をすり合わせていくことで、こちらの問題を解決したとのことです。
個人的に印象的だったのは、遠藤さんの発表では、最後の部分に限らず「現場の方々」というフレーズがよく出てきたことです。現場の方々を様々なプロセスで巻き込んでいくことは、(特に製造業における)データ分析支援ではとても大切であり、また大変なことだとも思います。そうした仕事から逃げずに取り組む、これがデータ利活用において重要なスタンスなんだなと、改めて実感した発表でした。ありがとうございました!
(クラウドエース 株式会社 / 田中 万葉)
「不動産情報サイトにおけるデータ収集で頑張ったこと」
Red Frasco 杉山様
続いて、Red Frasco 杉山さんからのデータ収集に対する頑張りについてのLTです。

よく使うサービスが、とってもデータエンジニアです。
使い方のレクチャー受けてみたいです。
今回は構築されたデータ分析基盤のデータ収集の部分についてお話いただきました。
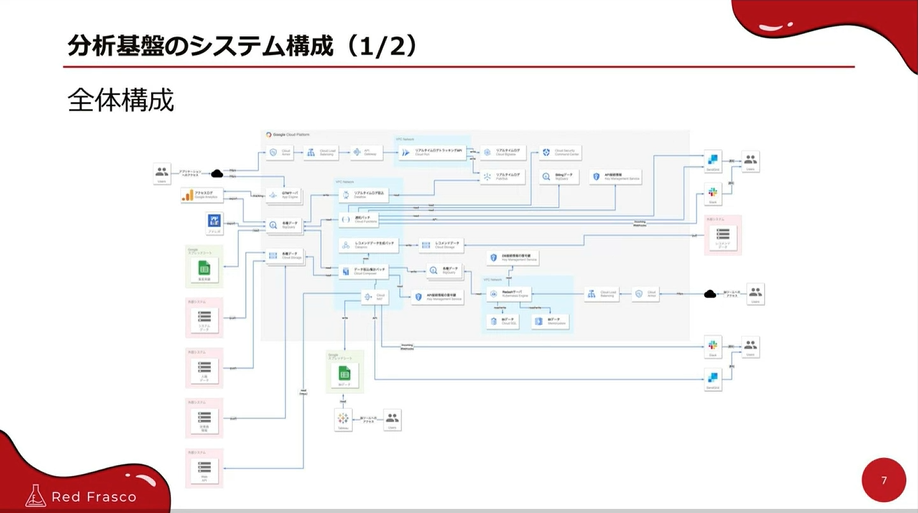
Cloud Composerをゴリゴリ使用された全体構成図です、スゴイ!
GoogleアナリティクスをBigQuery ExportしたものやGoogleスプレッドシートを外部テーブル出力したもの等々を、Cloud Composerの使用でデータ収集されています。
リアルタイムのアクセスログもCloud Run のAPIを使用して収集されています。

収集元がどのようなものであってもだいたい対応できるというのはとても便利です。
Cloud Composer素晴らしいです。
Cloud Composerでは再取り込みを考慮する頑張りをされています。
・データが重複しないようにする
・特定日のデータを取得可能にする

Google アナリティクスでも色々頑張られています。
他にもGoogle スプレッドシートでは、外部テーブル化し、Cloud Composerを使いスナップショットみたいなことをされています。
それぞれのデータに応じて頑張って実装されており、苦労がしのばれます。

なぜリアルタイムデータが必要なのか
・ほとんど、初回訪問でコンバージョンされる
・セッション内での訴求が重要
・Google アナリティクス単体では要件を満たせなかった
リアルタイムデータの処理をする際に、最初Firestoreを利用されたけれど、書き込みエラーが多くBigtableにされたとのこと。
実践して、適した方法を導きだされているのは素晴らしい頑張りです。
今回はデータ収集のところに特化したお話をしていただきましたが、他の部分の頑張りも聞いてみたいです。
追記:杉山様の資料はこちらのリンクからどうぞ ↓
(CTCシステムマネジメント株式会社 / 古林 信吾)
「データの鮮度の重要性」
株式会社メビウス 高橋様 / 矢野様
続いて、株式会社メビウスの高橋さん、矢野さんからデータ鮮度の重要性についてのLTです。


まずは高橋さんから、そもそもクラウドとデータ活用を捉えているのかという話がありました。
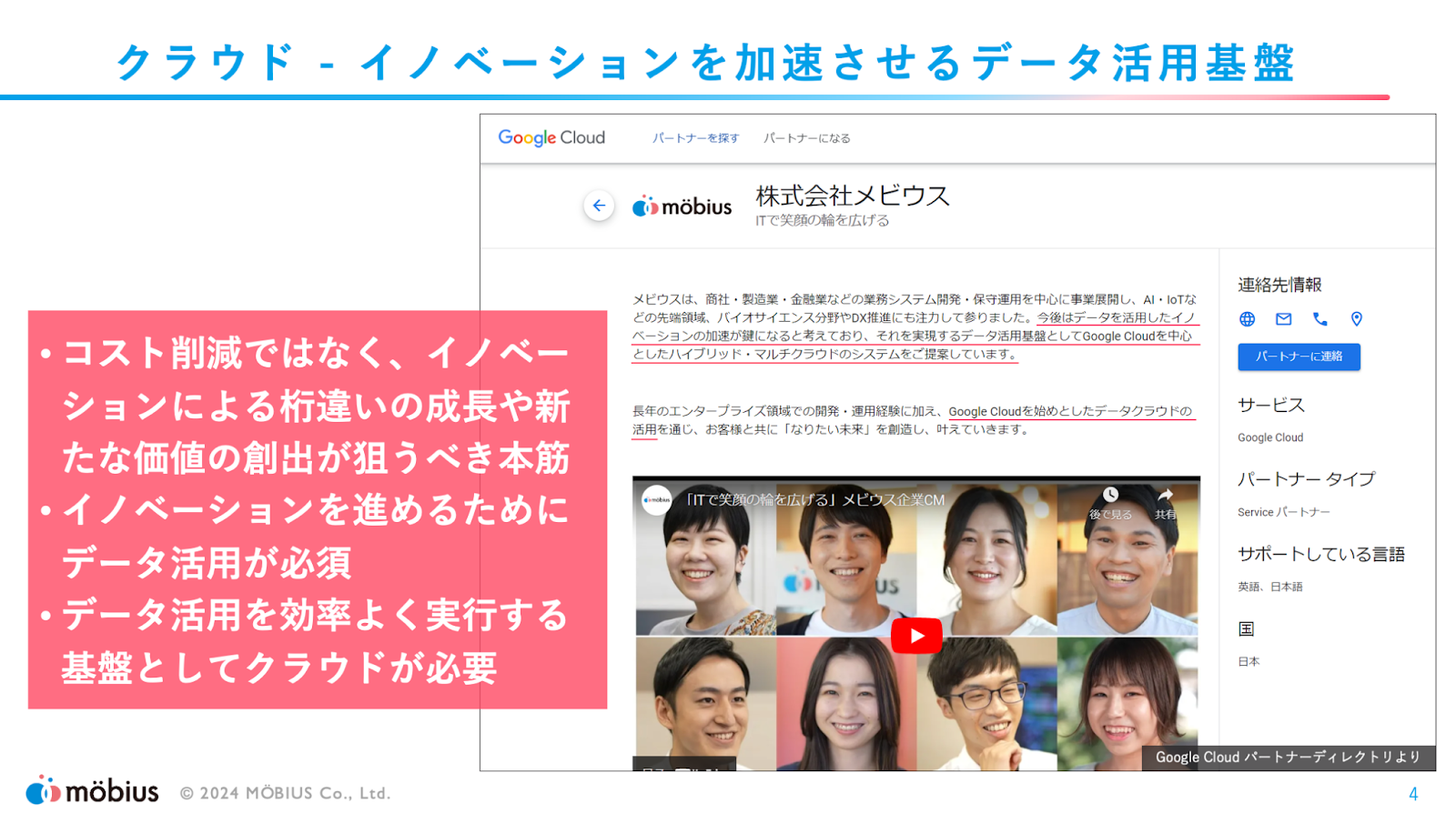
クラウドには様々なメリット(例えばコスト削減など)がありますが、目指すべき場所はイノベーションによる成長や価値創出が本質であり、その為のデータ活用を目指している、というお話がありました。
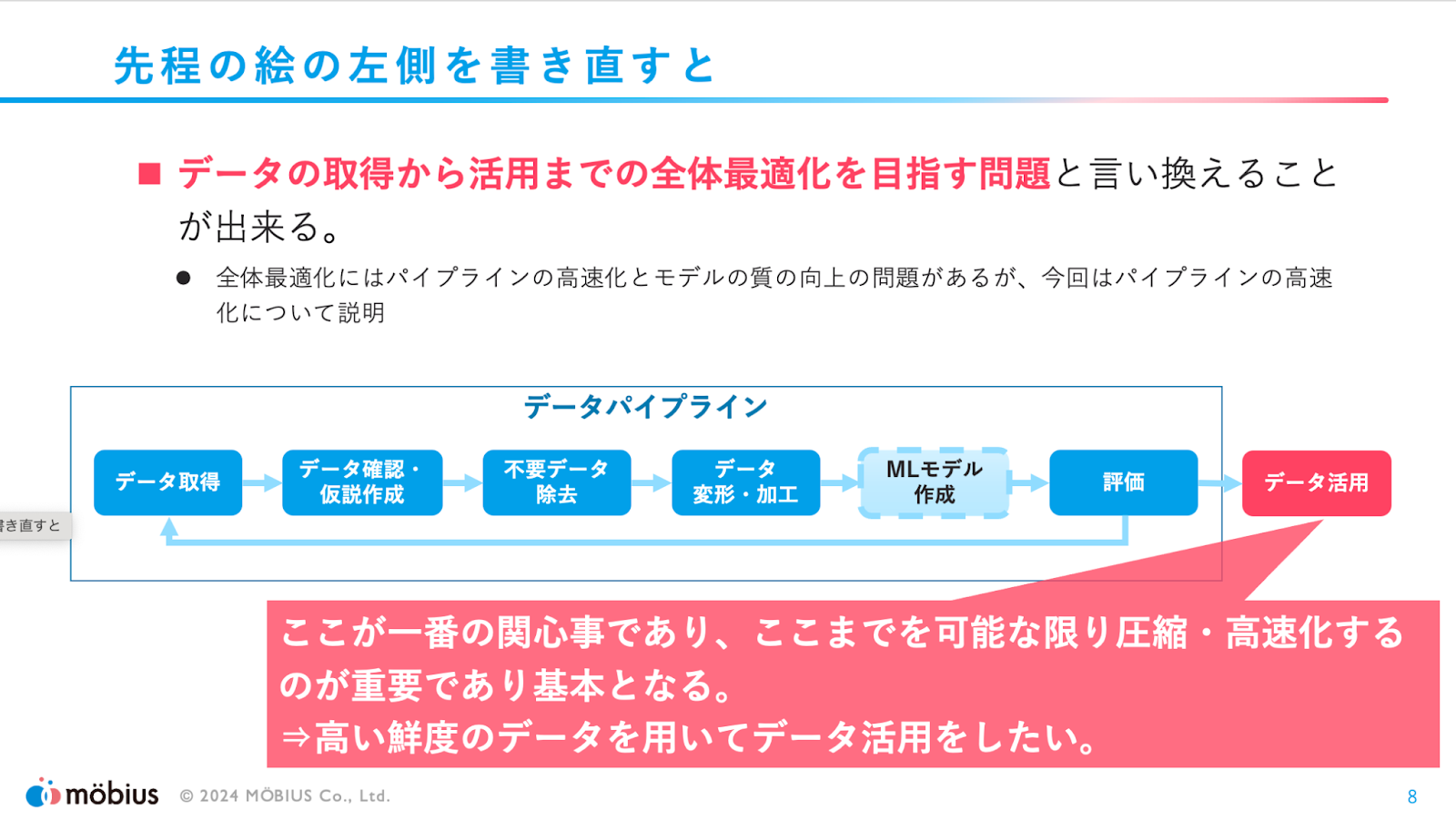
データ活用をしたいと考えても、データを収集してすぐに使えるようになるわけではなく、
データパイプラインを組んで活用できる形まで加工していく必要があります。
しかし、ユーザの関心事としては最後のデータ活用が最大の関心事となるので、「データ活用」が出来る形まで素早く持っていかなければならない、というお話をしていただきました。
最終的に価値創出を実現する箇所がユーザの関心事である、という点はデータ活用以外の案件をやっている場合でも意識する必要があるので、頷かれる方も多いのではないでしょうか?
エンジニアとしてはついつい作り込みの部分に関心が向いてしまうこともあるので、この意識は大事だなと改めて感じました!
さて、出来るだけ早くデータを活用出来るようにした方が良い、となんとなく感じる方は多いのではないかと思います。では、何故早く活用できるようにするべきなのか?ということで、
本題である「データ鮮度の重要性」についてのお話です!

データ鮮度は「活用方法の選択肢の数」に直結する為、とても重要です。
例えば、お魚の調理しようと考えた場合、鮮度が良ければ刺身など色々な調理法が考えられますが、
鮮度が悪くなるにつれて、選択できる調理方法が少なくなってしまいます。
データの鮮度についても同じようなことが言えて、データの鮮度によって取れる選択肢が変わってくるので、なるべく鮮度の良いデータを収集し、取るべきアクションを決めるのが良いのではないか、とのことでした。
何故データ鮮度が重要なのか、とても分かりやすく説明されていて画面の前で頷いてしまいました!
私も過去にリアルタイムなデータを求められるデータ分析基盤を担当してことがありましたが、遅延が発生するともう業務ではそのデータは使えないと言われてしまうようなこともあったので、データ鮮度が業務活用できるか否かに直結するというのは、個人的にも非常に腹落ちのする内容でした!

まとめです。以下2点が強調されていました。
- 前述の通り、データ鮮度は取れる選択肢の幅に直結する
- 機械学習モデルの精度も大事だが、過去事例を見ているとデータの鮮度の影響が圧倒的に大きいので、しっかりと鮮度の良いデータを集めた方が良い
最終的な評価にデータの鮮度が大きく影響するというのは聞いていて意外性がありました。
検証をしていても機械学習モデルの性能に意識がいきそうですが、改めてそもそもインプットとなるデータが重要なんだということを強く感じられました。

続いて、矢野さんから金属製品を取り扱う企業での事例をご紹介いただきました。
金属製品の全数検査を目視で行っていたものの、人によって判断基準にブレが生じており、またベテランの人材に依存している状態だったとのことです。
加えて細かくヒアリングをしたところ、現在の業務フローでは不良の発生をリアルタイムに検知出来ていないという課題も見えてきたことから、そうした課題の改善もターゲットにしたとのことでした。
課題の整理結果を踏まえ、課題に対応することに加え、不良の種別の具体的な分類まで実施する方針としたそうです。
単純な不良の分類だけでは人手でやるのと変わらない、ということで不良種別の分類までやることになったようですが、単純に人手でやっていた部分を置き換えるだけではなく、AIでなら実現できる価値を創出している点が素晴らしいと感じました!

資料中では導入前後で検査時間が27.8%削減されたと書いてありますが、最新の状況だと50%以上削減されているとのことです。凄い!
またリアルタイムでモニタリングできるようになったので、不良品の状況から不具合が発生している/発生しそうな生産ラインの箇所に予防的な対策を行うことも可能になったようです。
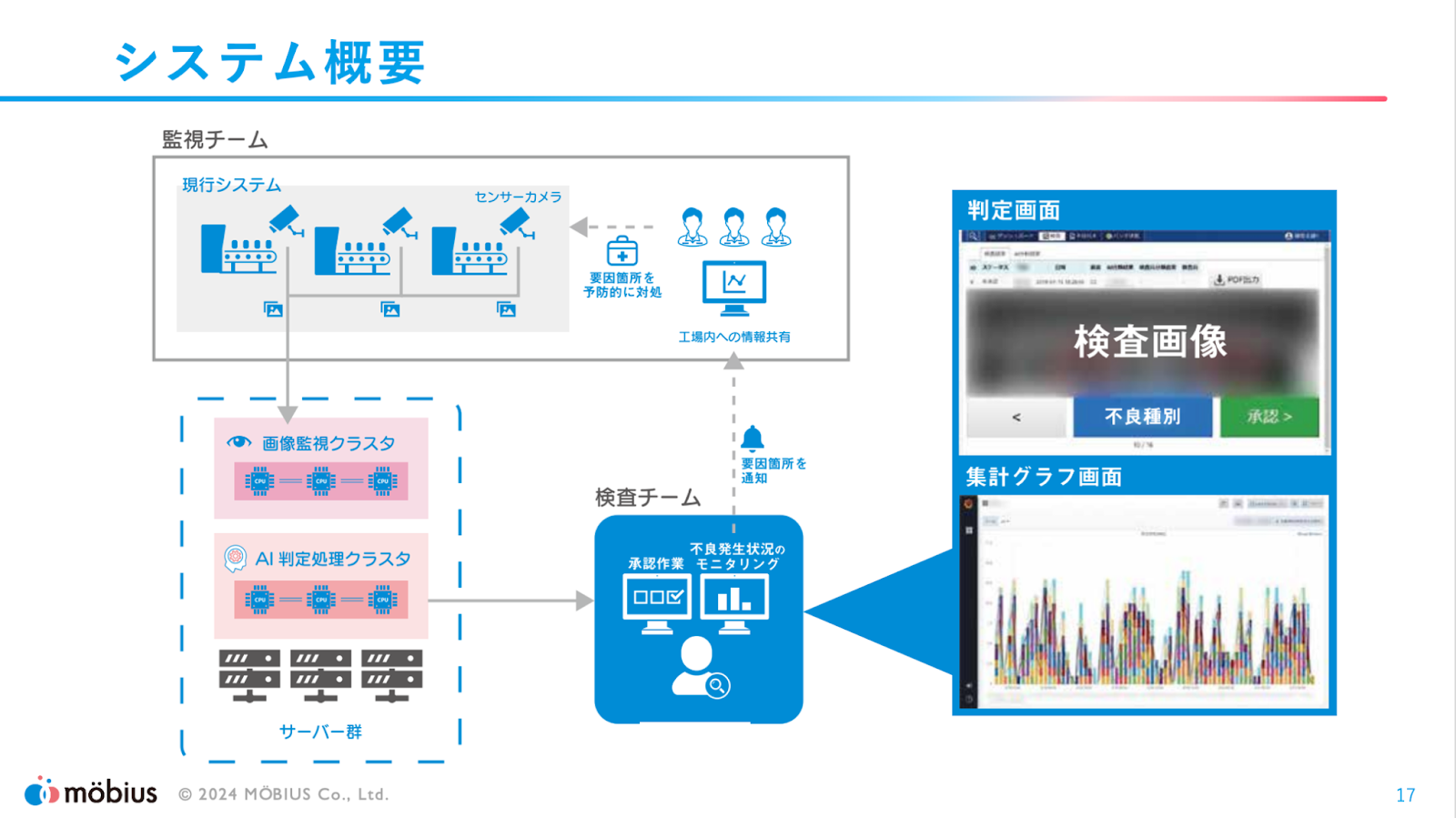
実際のシステム構成はこのようになっており、現在はオンプレミスの環境で稼動しているそうです。
今後Google Cloud上へ移行されるとのことです。
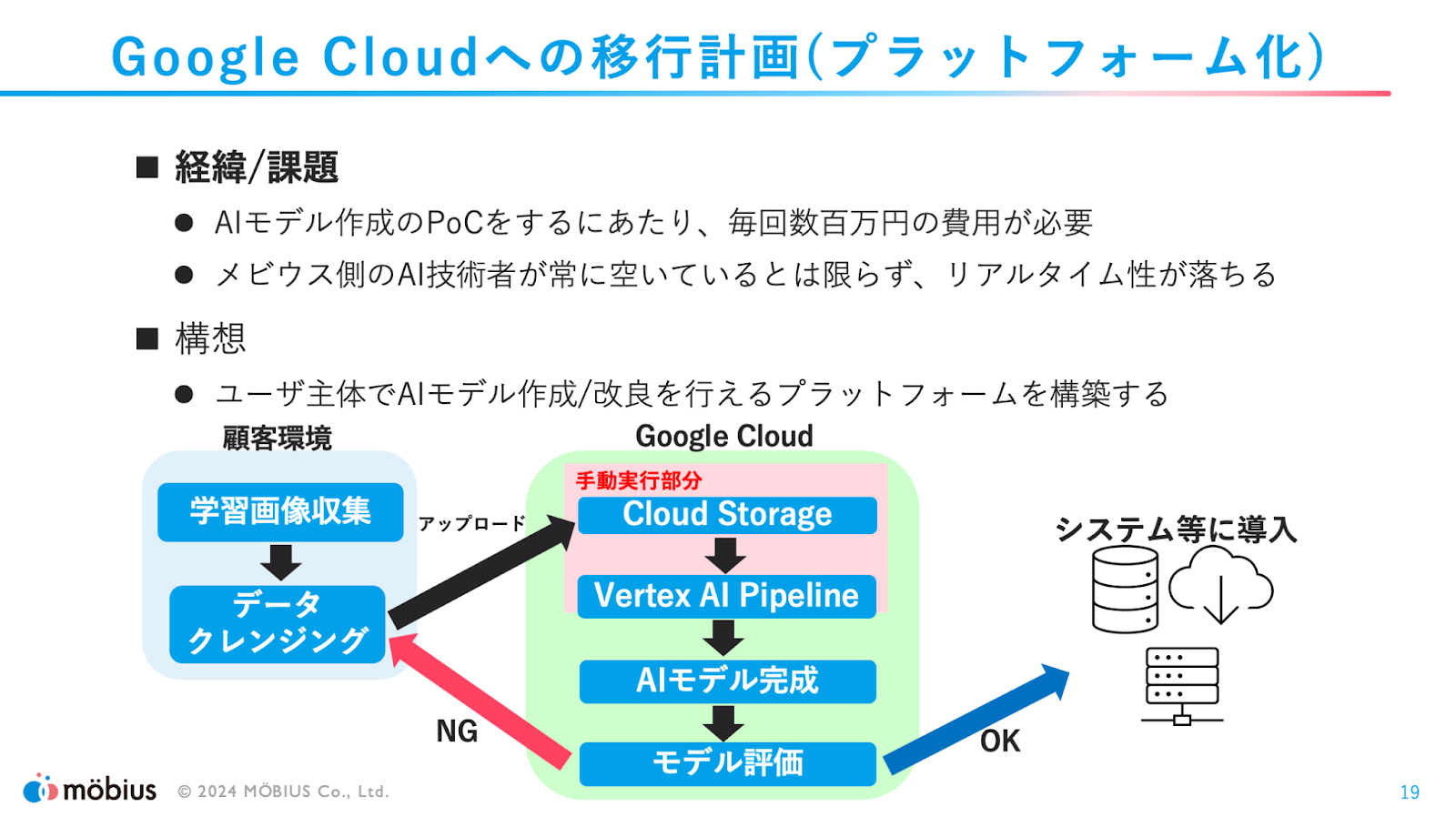
Google Cloud上へ移行する際は、ユーザー主体でAIモデルを作成/改良が出来るプラットフォームの構築を行う予定とのことでした。AIモデルの作成や改良は一度リリースした後も継続的に取り組む必要があるのだと思いますが、それがユーザー側で出来るようになったらとても便利ですね!
このプラットフォームの構築をテーマとしたLTも是非聞いてみたいと思いました!
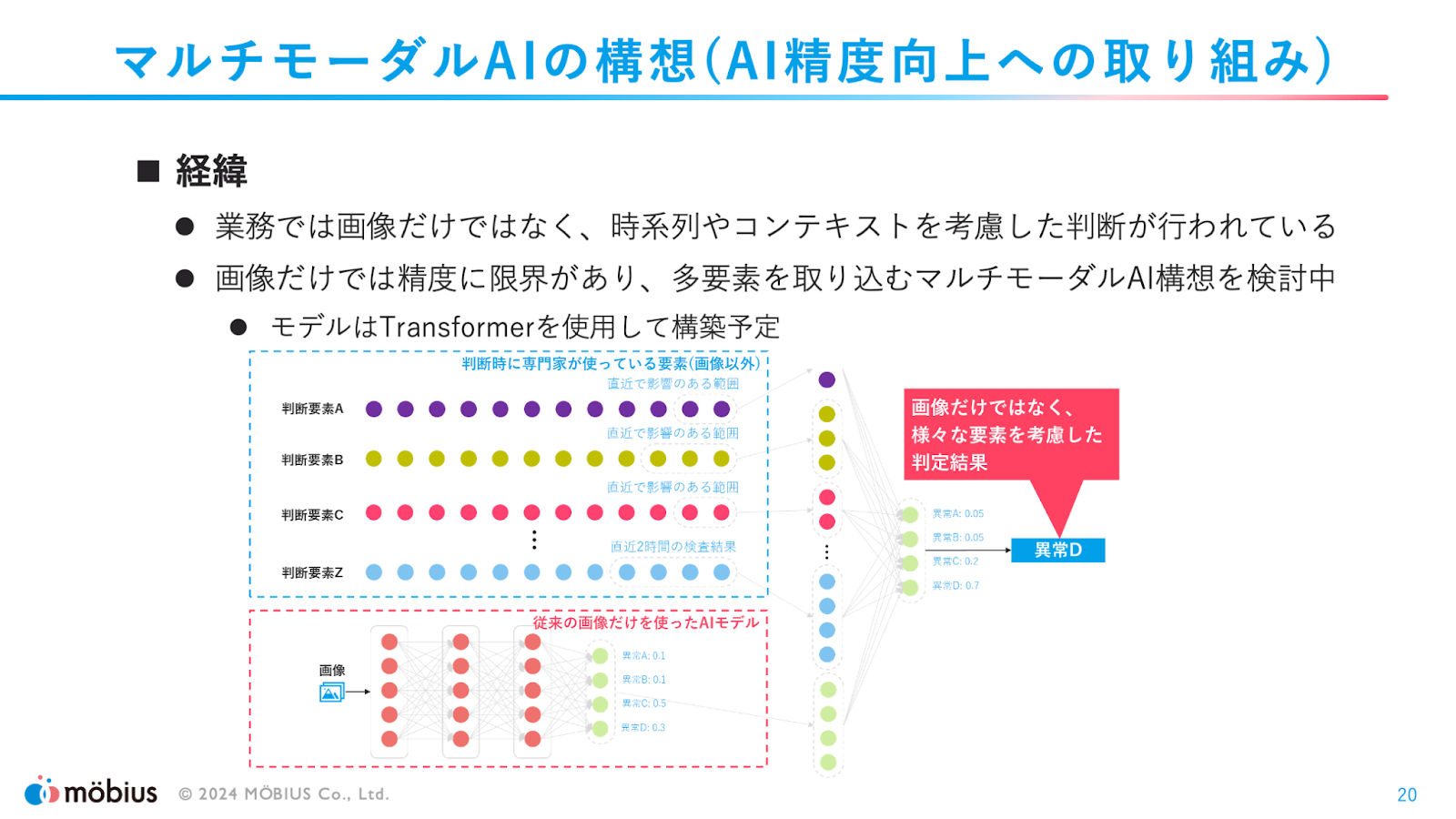
また、現在は画像データから異常判定を行っているものの、精度の限界が見えてきたので、直近の生産状況や機械の状況、機械への入力データ等も入力データとして取り込んだAIモデルの構築も予定しているとのことでした。こちらも構築後にどのような結果となったのか、改めて聞いてみたいですね!

事例紹介のまとめです。ユーザは当初リアルタイム性の部分については目標としていなかった(ニーズに無自覚)だったものの、実際に運用を始めた後は、リアルタイム性に大きな価値を感じていただいているとのことでした。データの鮮度の重要性が分かる、素晴らしい事例紹介でした!
データ鮮度は高い方が良い、とは直感的には感じる方は多くいらっしゃるのではないかと思います。
ただ、では何故鮮度が高い必要があるのか?という部分について自分でも具体的に言語化したことはありませんした。
重要性について理解できていないと、具体的な要件が無い限りは、システム的な制約から鮮度については最低限の部分で妥協してしまうようなこともあると思うので、こうして改めて具体的な価値創出の例を実感できたのはとても良かったです!
高橋さん、矢野さん、貴重なお話をありがとうございました!
(株式会社 野村総合研究所 / 鎌田 康太郎)
「データ利活用分科会#19 データ収集編」
GoogleCloud 梅川様
最後に、データ利活用分科会の運営メンバーの 1 人である、Google Cloud の梅川さんにお話しいただきました。

「データ利活用するためにデータ収集って必要?」という問いかけから始まった本 LT。
この問いかけの背景には「分析システムですら、サイロ化が進んでいる」という課題がありました。
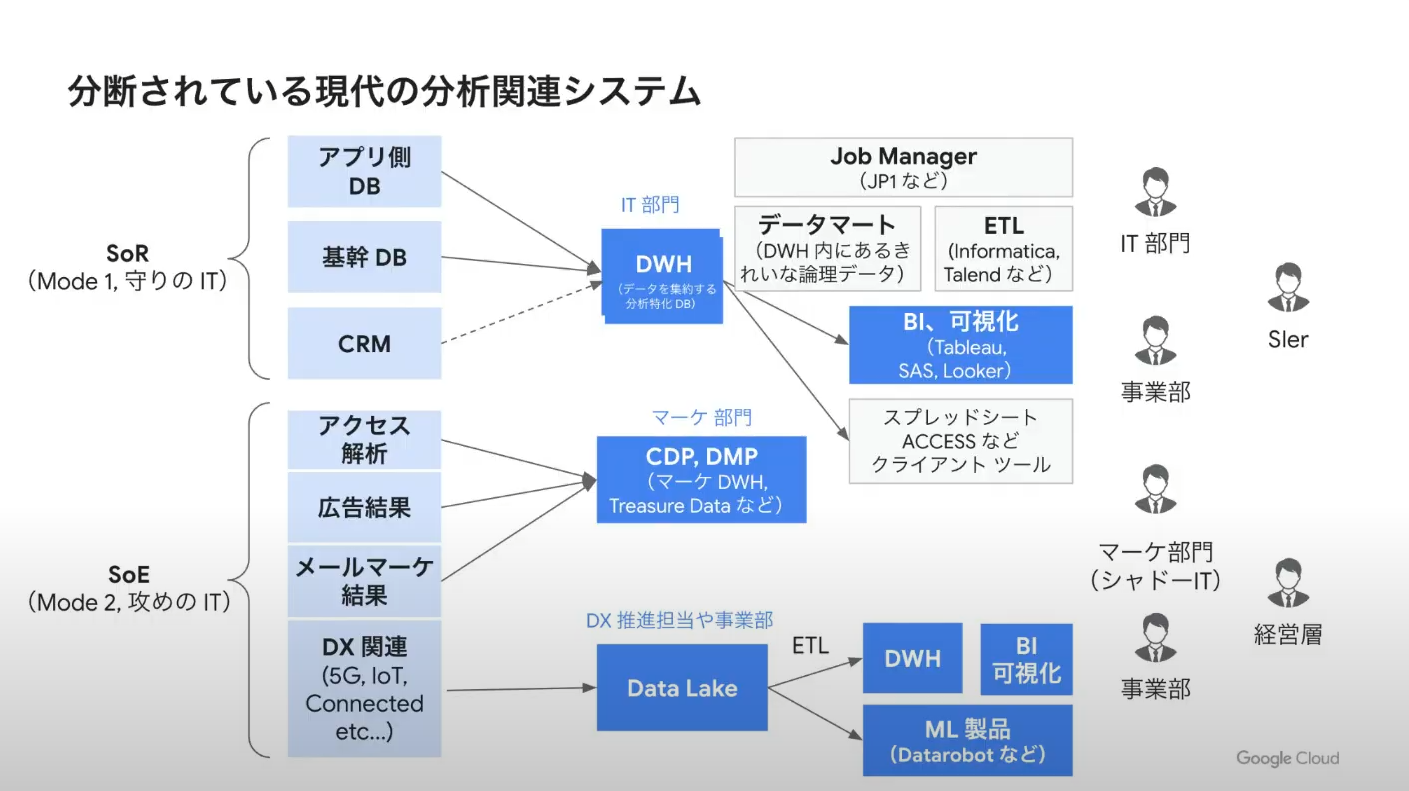
こちらは一般的なエンタープライズ企業における分析関連システムを俯瞰してみた図となります。
エンタープライズ企業においては様々なシステムが動いており、時にはデータウェアハウス (DWH)、時にはデータレイクなどバラバラな分析システムにデータが蓄積されてしまうという問題が起きています。
そんな「分析システムのサイロ化」の根本的な原因は、
各情報ごとに見せたいユーザーが異なり、「個別最適化」されていることにあると梅川さんは説明しました。
なら 1 つのシステムでどうにかできないかという話になるかと思いますが、予算や運用、マシンリソースといった理由から、それもなかなか難しいというのが現状とのことです。
更に、今までは「構造化データの活用」をメインに考えれば良かったものが、生成 AI の登場により「非構造化データ (動画、音声、画像など)」の活用も意識する必要が出てきました。
Vertex AI で非構造化データを分析することも、「生成 AI データ向きの個別最適化が行われているに過ぎない」という言葉は、私の心にすごく響きました。

そんな中、Google Cloud は構造化データも非構造化データも半構造化データも 1 つのプラットフォームで分析・可視化ができる環境を目指しています。
その一例として、昨年の Google Cloud Next Tokyo ’23 で行われた、非構造化データを BigQuery を用いて解析するデモ動画が紹介されました。
https://www.youtube.com/watch?v=jCsV6rEurcI&t=2433s
コールセンターの音声データの文字起こしをし、生成 AI で解析、Looker Studio で可視化するまでの流れが紹介されています。
BigQuery と生成 AI のパワーと、その使い方が良くわかる動画となっているので、見たことがない方はぜひご覧ください!
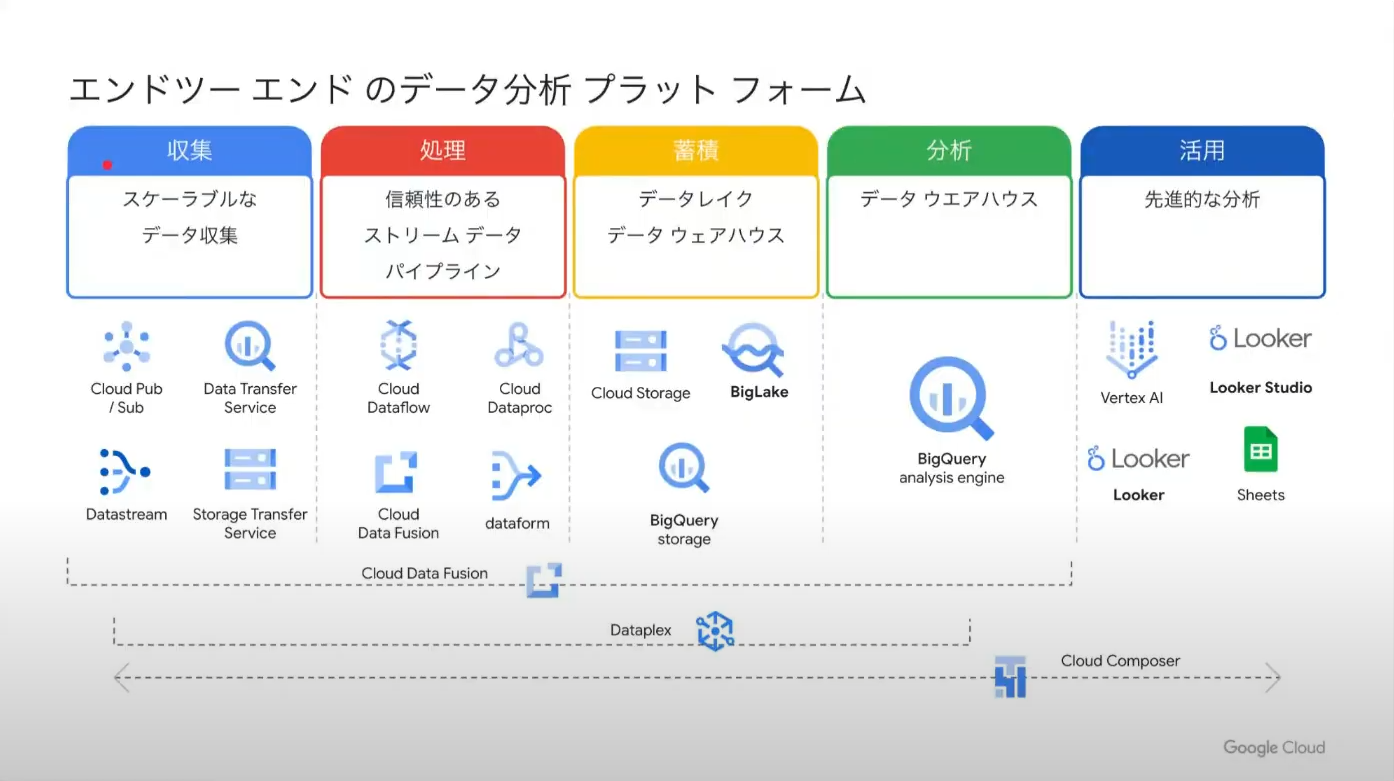
最後に、収集から処理、分析、活用まで、様々な用途向けに提供されている Google Cloud のサービス群の中から、データ収集向けのサービスとして
- BigQuery Data Transfer Service
- Datastream for BigQuery
- Cloud Data Fusion
について紹介いただきました。
BigQuery Data Transfer Service は、Google の各種サービスや他社のクラウドのストレージサービス、データウェアハウスから BigQuery にデータを収集するためのサービスです。
サードパーティ転送を用いれば、200 を超えるシステムからデータを転送することができます。
Datastream for BigQuery は、Oracle Database や MySQL といったリレーショナルデータベースから BigQuery にデータ転送できるサービスです。
3 つ目の Cloud Data Fusion は、本来は ETL サービスであるものの様々なデータソースに対応しており、GUI で操作可能であるという点から紹介されていました。
データのサイロ化を防ぐために組織を横断してデータ収集を行うはずのデータ分析システムですらサイロ化が進んでいるという問題に一石を投じ、その問題に 1 つのプラットフォームで対処することができることが、 Google Cloud の 1 つの強みであることを再認識させていただいた LT でした!
(株式会社 G-gen / 堂原 竜希)
所感・まとめ
ご登壇者の皆様、ありがとうございました!
今回はData Journeyシリーズの記念すべき第1回Meetupでした。第1回?シリーズ?ということは…そうです。これからもData Journeyは続いていきます。「データ収集」ということで分析を行う前の準備段階にどんな苦労があるのかがよく分かり大変勉強になりました。そして、データの収集・最適化の課題がGoogle Cloudにより解決されることもよく分かりました。データ分析プラットフォームを構築して運用がはじまりますとなんとなく完成した感を持ってしまいますが、現場の肌感覚とすり合わせたり、分析結果と向き合ったりすることで課題を発見し改善していくことがいかに重要かを改めて認識しました。
ではまた次回のデータ利活用分科会イベントでお会いしましょう!!
次回予告
次回はデータ利活用分科会Meetup #20 3周年記念「新時代のデータ利活用」となります。この分科会のオーナーである増森氏が3年間の歴史を語ります。新しいデータの使い方やニーズについてLTも募集しております。奮ってご参加ください。
(TD SYNNEX株式会社 / 吉川洋太郎)