
O11y-SRE × クラウドネイティブ 分科会 コラボ Meetup

こんにちは、クラウドネイティブ分科会運営です。
2024年6月28日に開催されたO11y-SRE分科会とクラウドネイティブ分科会合同のMeetupを開催しましたので、そちらの開催レポートをお届けします。
今回はDatadog 様の東京オフィスとMeetのハイブリット開催でGoogle Cloudイベント登壇者をお招きして生の声をお届け&最新イベントの振り返りをしました!
そして、今回は全て Gemini さんに、画像の選定から、レポートの作成をお願いしました。
クラウドネイティブ時代にo11yを
3-shake 吉田さん
- クラウドネイティブ時代の observability
はじめの講演はスリーシェイクの CEO である吉田さんにお話しいただきました。Datadog 東京オフィスも初めてということで、Datadog T シャツが欲しいというお言葉を途中途中で挟まれていました笑

まず初めは、タイトルのクラウドネイティブ時代のオブザーバビリティについてです。
従来の監視はシステムの構成やパフォーマンスの監視が中心でしたが、クラウドネイティブ時代では、ビジネスの状況・ユーザーの行動・システムの構成・パフォーマンス・信頼性など、より幅広い観点からの監視が必要です。特に、ユーザーの行動やビジネスの状況を理解し、システムの改善につなげることが重要であり、またシステム全体で発生する問題を迅速に特定し、解決することも不可欠だというお話しから始まりました。
- 「信頼」の時代におけるオブザーバビリティの重要性
続いて、オブザーバビリティの重要性を「信頼」という観点から捉え、ビジネスサイド・エンジニア・ユーザーそれぞれの立場における重要性をお話しいただきました。
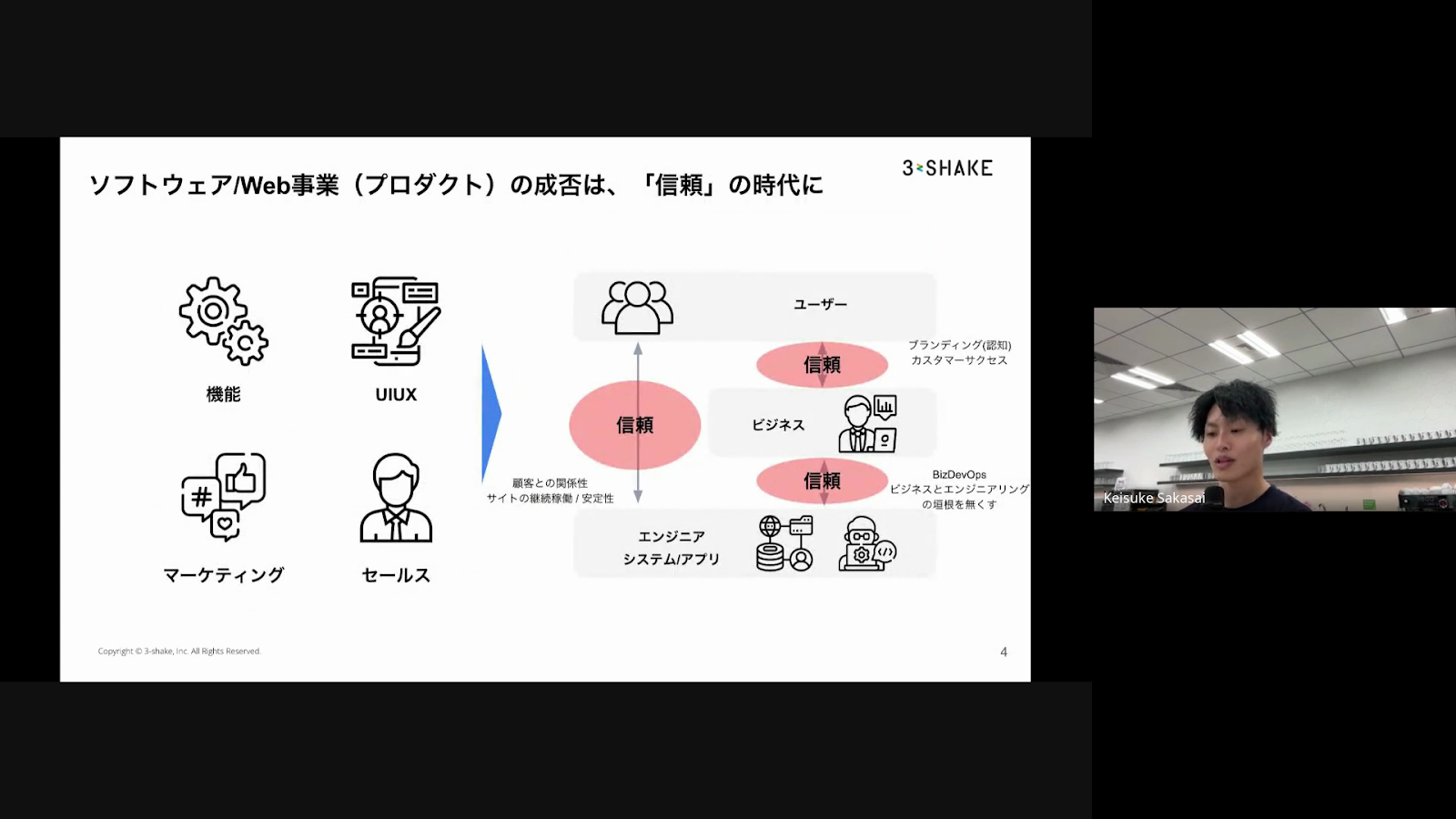
ビジネスサイドでは、機能やマーケティング、営業などそれぞれの視点でシステムを評価し、ビジネス目標達成に近づけることを期待しています。一方でエンジニアは、ログ・トレース・メトリクスなどのデータを用いて、システムの内部的な状態を監視し、問題発生時には迅速な対応を目標にします。さらにユーザーは、常に安定して稼働し、期待通りの機能を提供するシステムを通じて、信頼感を高め、サービスの継続的な利用へとつながるとのことでした。
- 「小さな声」を拾う observability
続いて、オブザーバビリティを通じて、ユーザーの「小さな声」を拾う重要性をお話しいただきました。
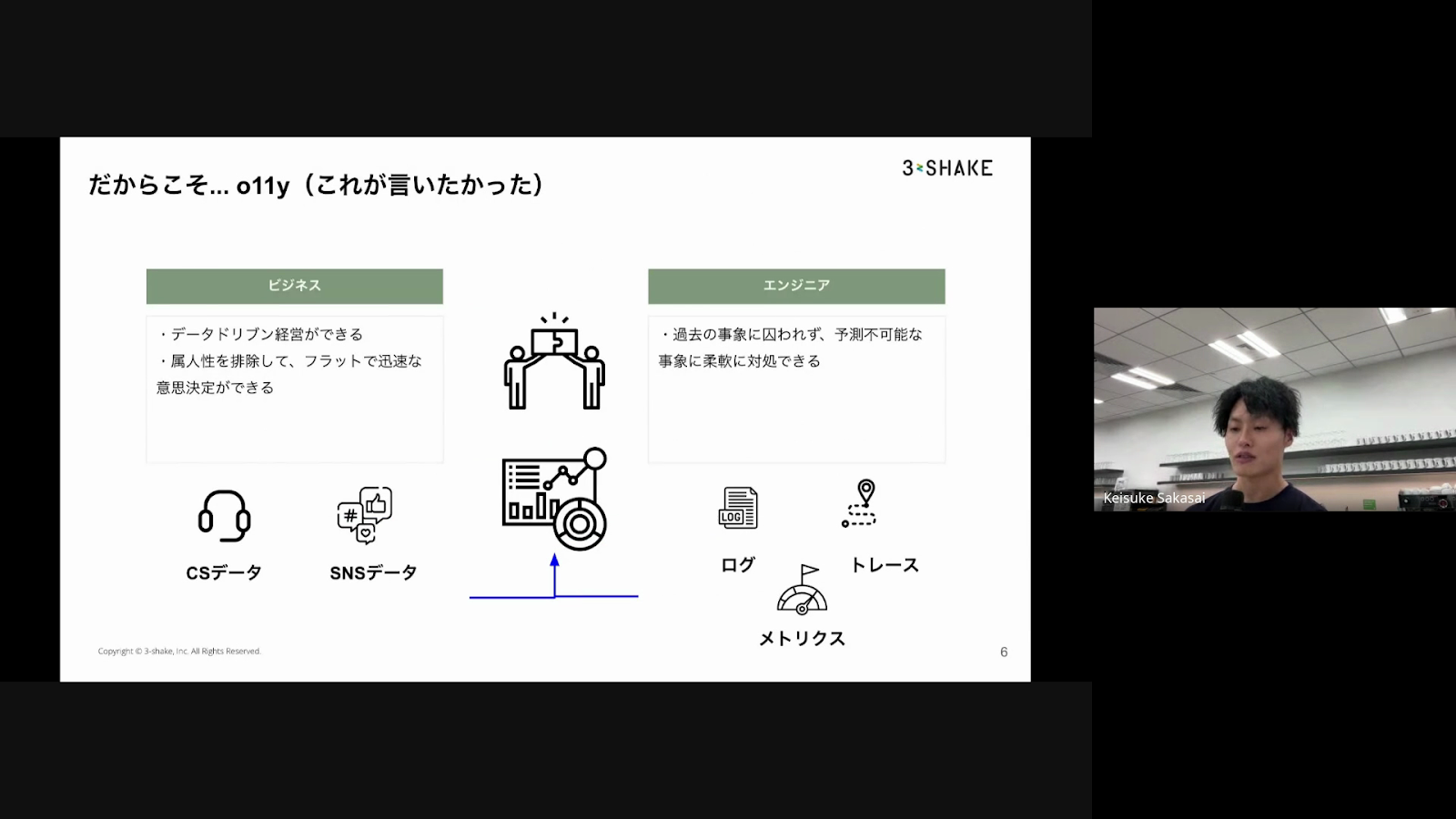
ユーザーからの問い合わせ・SNS の書き込み・メトリクス・ログ・トレースなどの情報を集め、ユーザーがどのような問題を抱えているのか、何を期待しているのかを分析する必要があるということです。そして、ユーザーの期待に応えられるよう、システムの改善や機能の追加を迅速に行うことで、ユーザー満足度を高め、より良いサービスを提供していくことが重要だと強調されていました。
- オブザーバビリティの実現に向けたステップ
続いて、オブザーバビリティを実現するためのステップを3つに分けお話しいただきました。

まず、従来の監視で用いられていたメトリクスを分析し、重要な指標を明確にすることが重要です。次に、CUJ(Critical User Journey)を意識したオブザーバビリティを構築することで、ユーザー視点での監視を強化します。まさに、ここで先ほどのユーザーの「小さな声」を拾う重要性が出てきますね。
最後に、Biz/Dev/Ops チームが連携し、オブザーバビリティの情報を共有することで、共通認識を形成し、信頼性の高いシステムを構築していくことが重要であるということです。
- Datadog を活用したオブザーバビリティ
最後は、Datadog を例にした実例をもとに、オブザーバビリティを実現するためのポイントをまとめていただきました。

Datadog は、エンジニア・Biz/Dev/Ops チームなど、様々な立場の人が共通のダッシュボードで情報を確認できるため、コミュニケーションを円滑化し、迅速な問題解決に貢献できます。また、Datadog は RUM(Real User Monitoring) などでユーザー体験に関するデータも収集できるため、システムの改善や新機能の開発に役立つと強調いただきました。
オブザーバビリティの再考
木村さん
- オープニング

今回のイベントの運営で、会場の提供元でもある Datadog に所属している木村健人さんが、もう一つの講演として『オブザーバビリティの再考』というテーマでお話しされました。
- オプザーバビリティとは
まずは、そもそもオブザーバビリティとは、という内容から振り返りました。

ここでは、オブザーバビリティはシステムが動作する上で重要な内部状態の情報を取得できる状態であると『オブザーバビリティ・エンジニアリング』から引用しています。
従来のモニタリングは、システムの表面的な状態を可視化することに重点を置いていましたが、現代の複雑なシステムでは、表面的な情報だけでは問題の原因を特定することが難しい場合があります。そこで、近年注目されているのが、システムの内部状態を理解することに重点を置くオプザーバビリティだということです。
- オブザーバビリティへの誤解
続いて、オブザーバビリティに対してよくある誤解について、例を挙げてお話しされました。

ここでは、いくつかあった誤解例の一つを取り上げます。
オブザーバビリティはしばしばメトリクス・ログ・トレースの監視を行うことだと誤解されますが、単にこうしたテレメトリーの総称ではありません。特に APM(Application Performance Monitoring)やトレースはオブザーバビリティの代表例のように挙げられますが、実際にはそれらのテレメトリーを収集するだけではなく、個々の監視情報を相関し可視化することがオブザーバビリティの実現に繋がるとのことです。
- オブザーバビリティとモニタリング
最後に、オブザーバビリティとモニタリングの関係をお話しいただきました。
よくあるオブザーバビリティとモニタリングの関係図を用いて説明をしていましたが、スライドは非公開とのことで、本ブログでは文章での簡潔なまとめとなります。

ここで発表者の木村から補足です。 どうやら Gemini さんには概念的なお話は難しかったようで、発表の意図とは逆の内容がまとめられてしまいました。 そのため、ここからは発表の要旨を記載します。
モニタリングは、システムの現在の状態を把握するための手段であり、モニタリングをきちんと行えばオブザーバビリティは向上します。一方でオブザーバビリティは、システムの挙動を深く理解するために必要な情報を得るために、モニタリングを活用する。モニタリングは、オプザーバビリティの基盤となる重要な要素であると考えられるとのことです。
つまり、これらの二つの概念はそれぞれベクトルが異なるものであり、同一の図の上で語るのが難しいとのことです。
これらの考え方は誤解が多く、オブザーバビリティとモニタリングを比べたり比較する内容が多いように思いますが、そうではなくオブザーバビリティの概念自体を正しく理解してモニタリングとの関係性を理解することが重要とのことでした!
LT1
有馬さんは、「o11yを活用したSLI/SLOへの取り組み」というタイトルで発表していただきました。
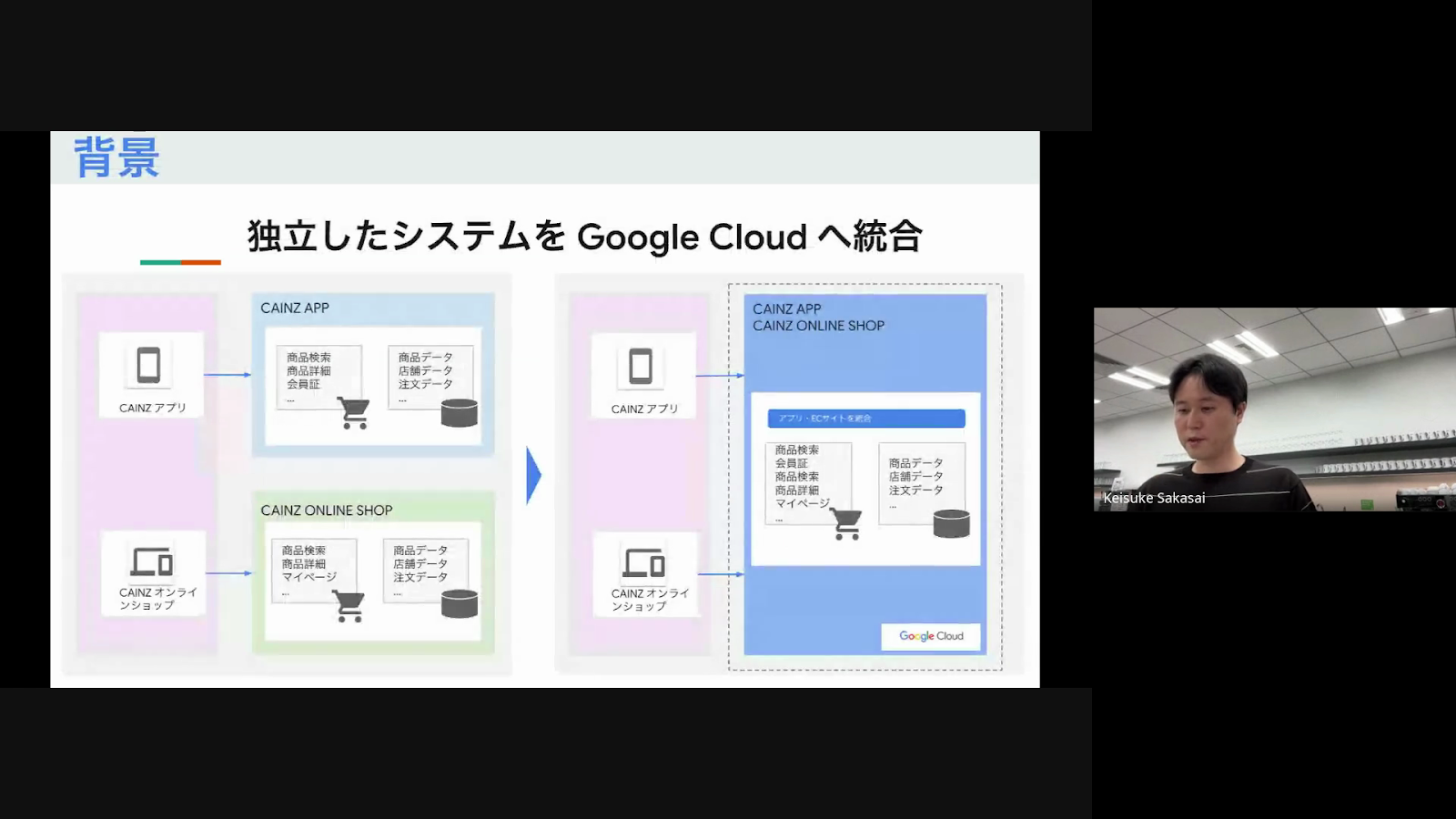
有馬さんが所属する株式会社カインズでは、スマホアプリやECサイトなど複数のプラットフォームでサービスを展開しています。しかし、それぞれ異なるプラットフォームとデータを持つため、利用者それぞれが異なる環境ごとにデータ登録や様々な対応をする必要があり、大きな負担となっていたそうです。そのため、サービスをGoogle Cloudへ統合し、一元管理することを検討しました。
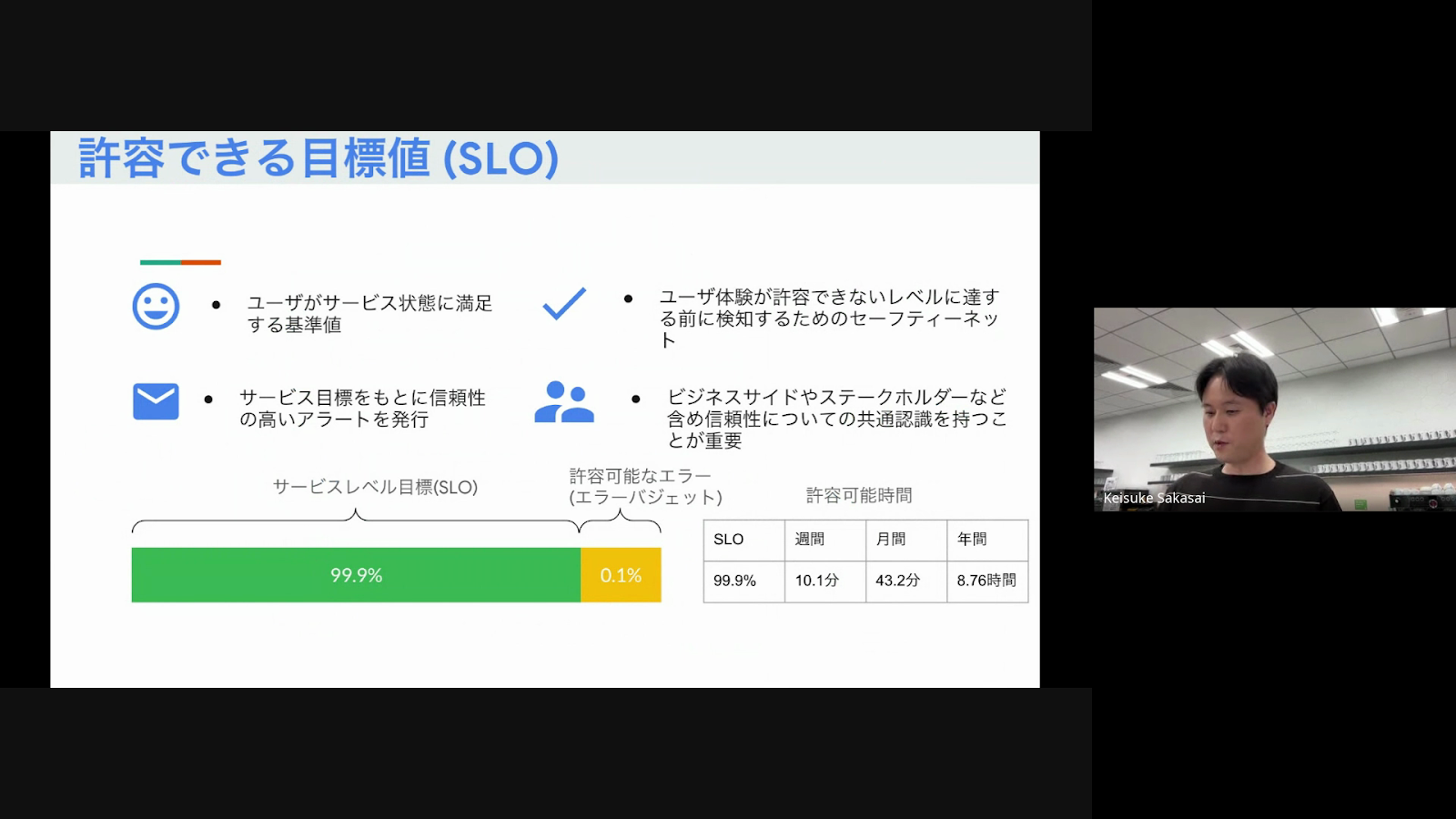
その統合の中で、従来のモニタリングでは、決められた指標に対するリクエストをするだけで、実際にユーザーが利用する際の体験に沿った指標でモニタリングできていませんでした。そこで、有馬さんは、従来のシステムのモニタリングを見直し、ユーザー体験に近い形でAPIのリクエストを計測するなど、新たな指標で計測していくことを決定したそうです。具体的には、スマホアプリやWeb、API、Cloud RunなどのサービスをGoogle Cloudに統合し、それぞれのサービスに対して、レイテンシー、HTTPステータス、エラーサチュレーションなどの指標で計測し、これらの指標を可視化することで、サービス全体の信頼性を把握することができ、ユーザー体験の向上に繋げることを期待しているそうです。
o11yデータの集約にはDatadogを採用しており、理由としては、Google Cloudと連携が容易で使いやすいインターフェースを提供しているためだそうです。

今回の取り組みを通じて、有馬さんは、ユーザー体験(顧客体験)に焦点を当てた信頼性の重要性を認識し、SLI/SLOを活用したサービスの開発に注力していく考えを示しました。また、将来的な取り組みとして、ビジネスサイド、ステークホルダーなどを含めた、よりユーザー体験に近い形で信頼性を計測していくことの重要性を訴えていただきました。そして、今後の展開として、Google Next Tokyoでより詳しい内容を発表する機会を設けているそうですので、より詳しく参照したい方はぜひ!。
LT2
アイレット株式会社に所属する松田さんは、自社開発案件を担当され、従来のインフラエンジニアとしての知識では、オブザーバビリティについて理解が不足していると感じ、改めてオブザーバビリティを学ぼうと思い立ち、その経験を共有しようと考えたということでした。
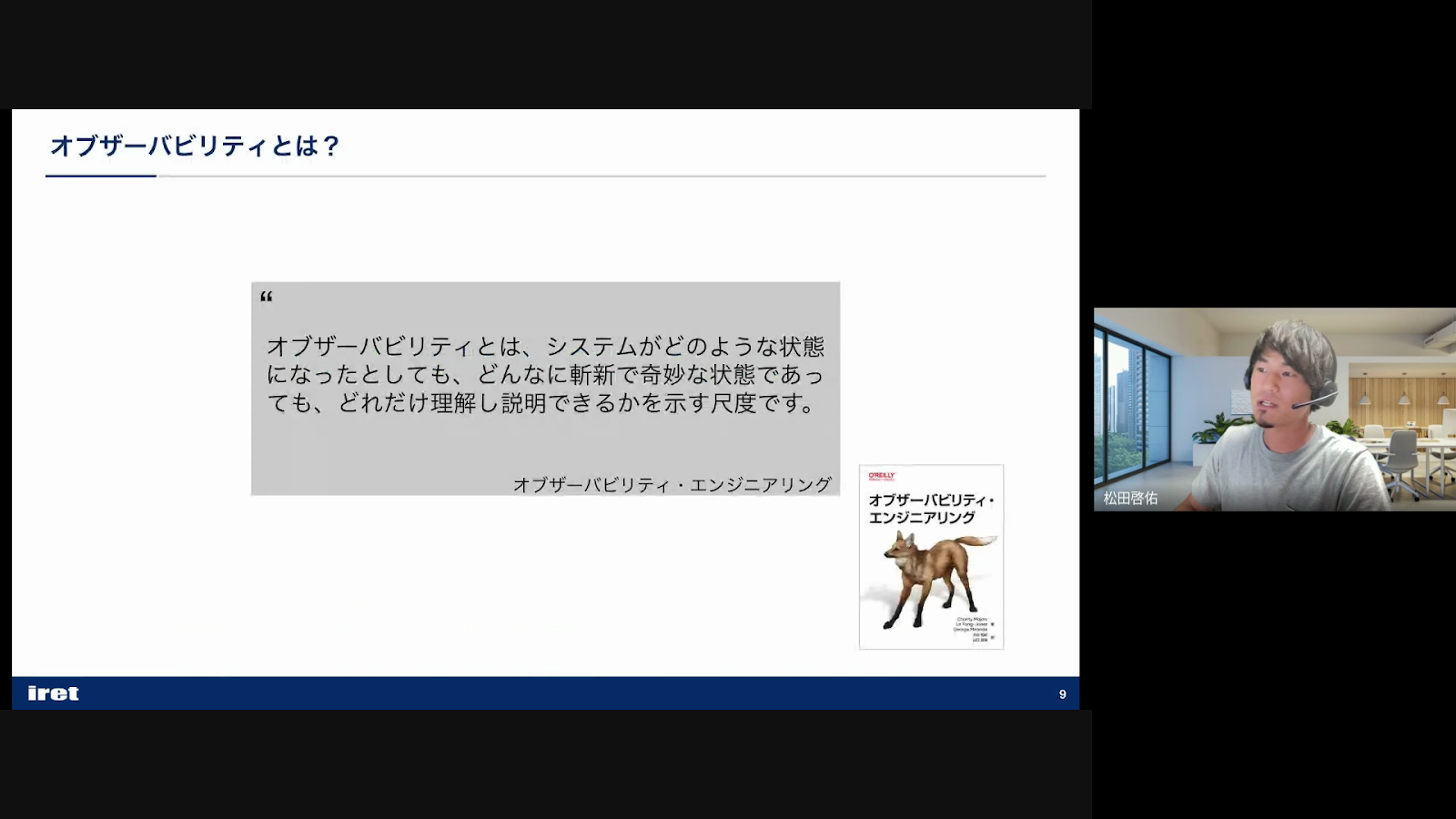
オブザーバビリティについて、システムがどのような状態になっているかを理解するために必要な概念であると説明していただきました。オブザーバビリティとは、システムの状態を理解するために、メトリクス、ログ、トレースといったデータを収集し、分析することで、システムの状態を可視化し、問題を診断、解決する能力という説明です。

松田さんは、今まで担当していた案件において、システムの最適な監視ができていなかったことを課題として挙げています。具体的には、CPU使用率やメモリ使用率といったリソース監視は行っていましたが、システム全体の挙動を把握できるような監視ができていなかったとのことです。そのため、現在参画している自社開発案件では、システムの挙動や利用状況を把握するといった、より適切な監視方法を検討する必要性を感じたとのことです。
松田さんは、監視の改善策として、監視項目を明確化し、監視対象をシステム全体の挙動に焦点を当てて見直すことを提案しています。これにより、システム全体の状態をより適切に把握し、問題発生時の対応を迅速化することが可能になると説明しています。松田さんは、具体的な監視ツールとして、New Relicを使用していることを紹介してくださいました。
LT3
株式会社スリーシェイクに所属している岩崎さんは、アプリケーションのコードを変更せずにトレース情報を取得したいという悩みを持つ人は多いのではないか、そして、その悩みを解決するGrafana Beylaについて話していただきました。
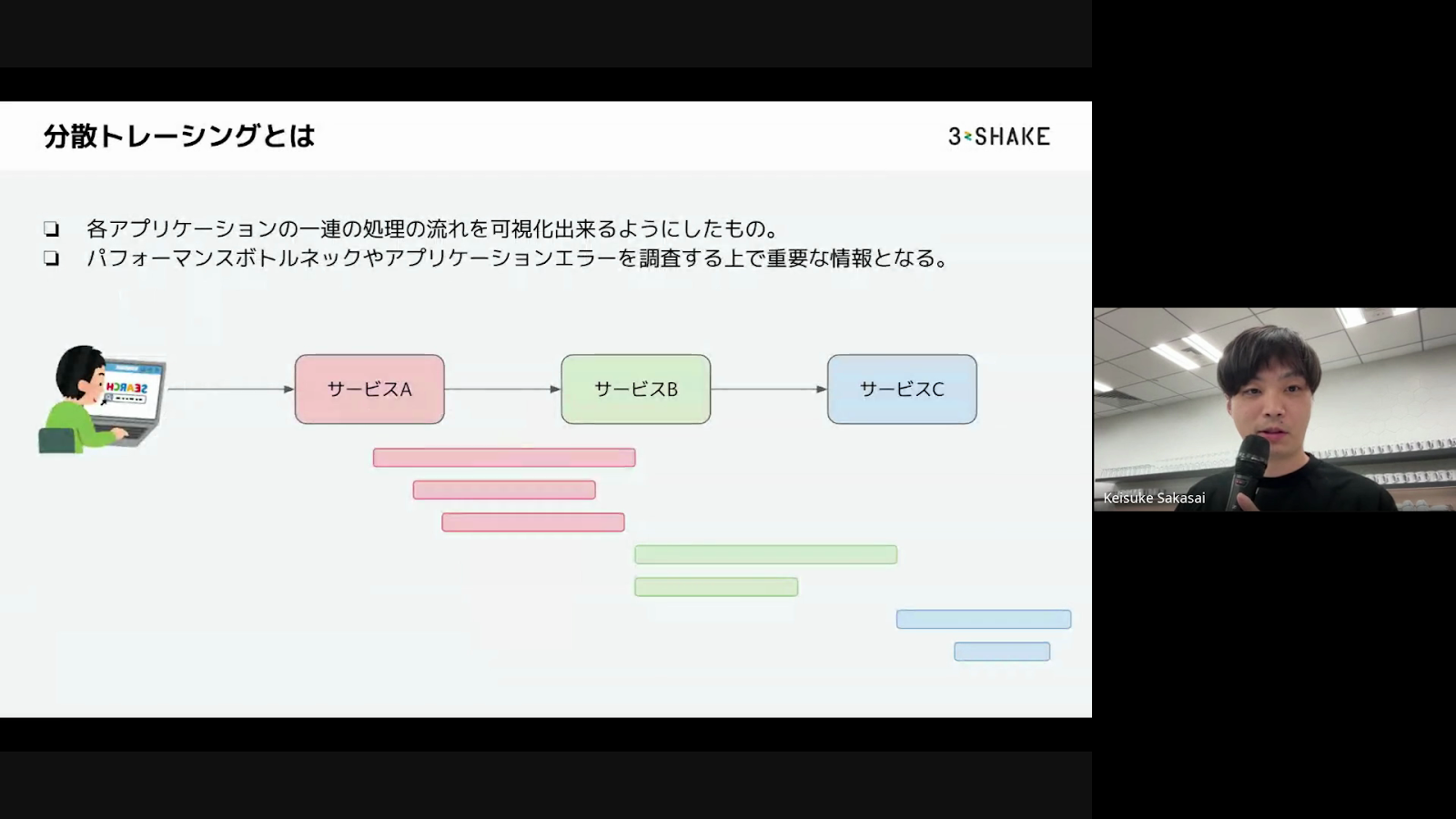
岩崎さんは、分散トレーシングについて、複数のアプリケーションの一連の処理の流れを可視化できる仕組みで、パフォーマンスのボトルネックやアプリケーションのエラーを調査する上で重要な情報になることを説明しています。分散トレーシングの方法は大きく3つあり、手動でアプリケーションコードにトレース情報を追加する手動計装、アプリケーション起動時にライブラリを通して情報を付加してトレース情報を収集する自動技法(アプリ)、eBPFを使って動的に起動しているアプリケーションに情報を付加する自動技法(インフラ)が考えられるそうです。今回のGrafana Beylaは自動技法(インフラ)の部分になります。
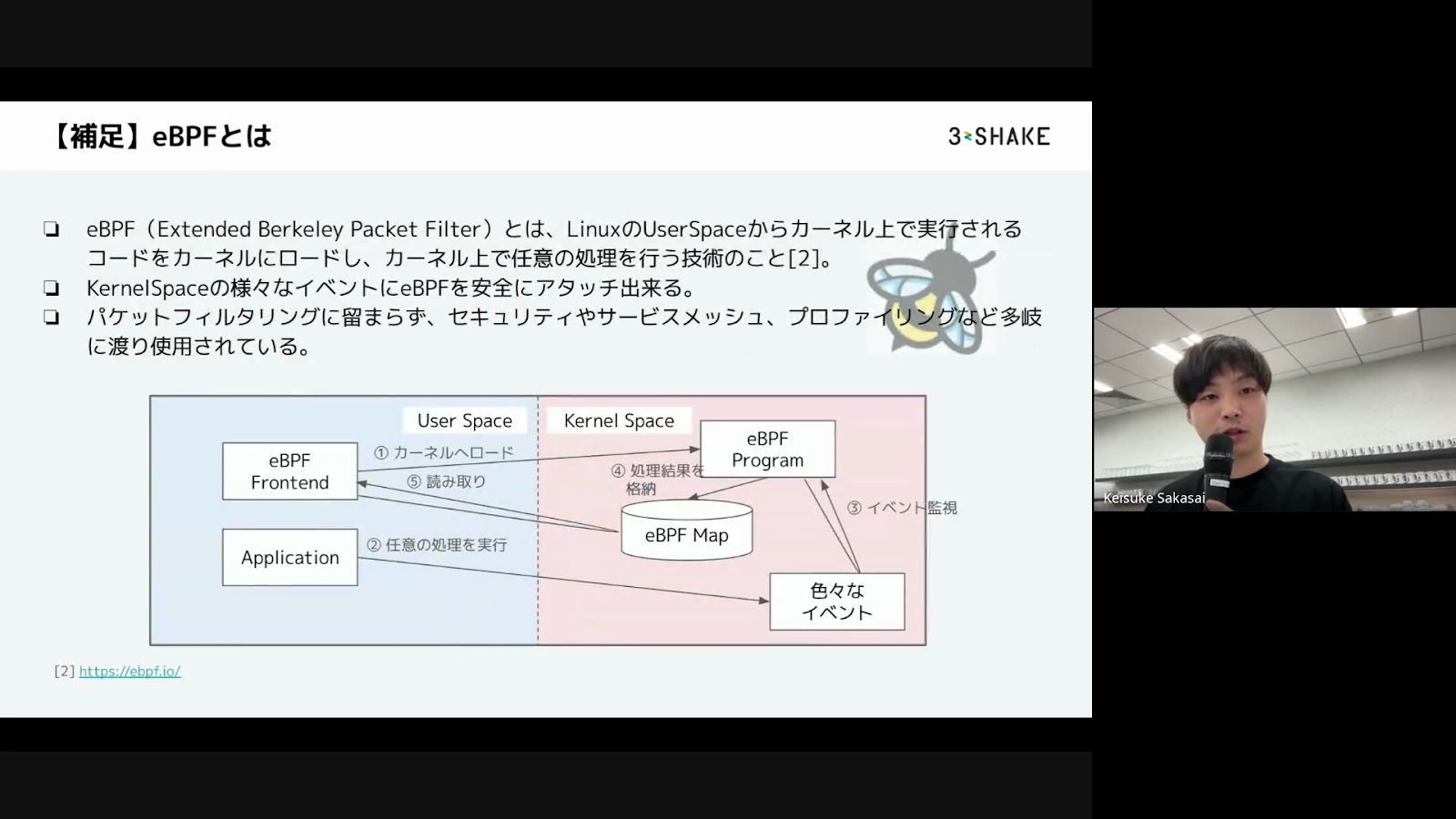
岩崎さんは、eBPFについて説明しています。eBPFはLinuxのユーザー空間からカーネル上で実行できるコードをロードし、カーネルで任意の処理を実行することのできる技術です。カーネル空間の様々なイベントをフックして監視したり、セキュリティやサービスメトリック、プロファイリングなど様々な用途で使われているそうです。
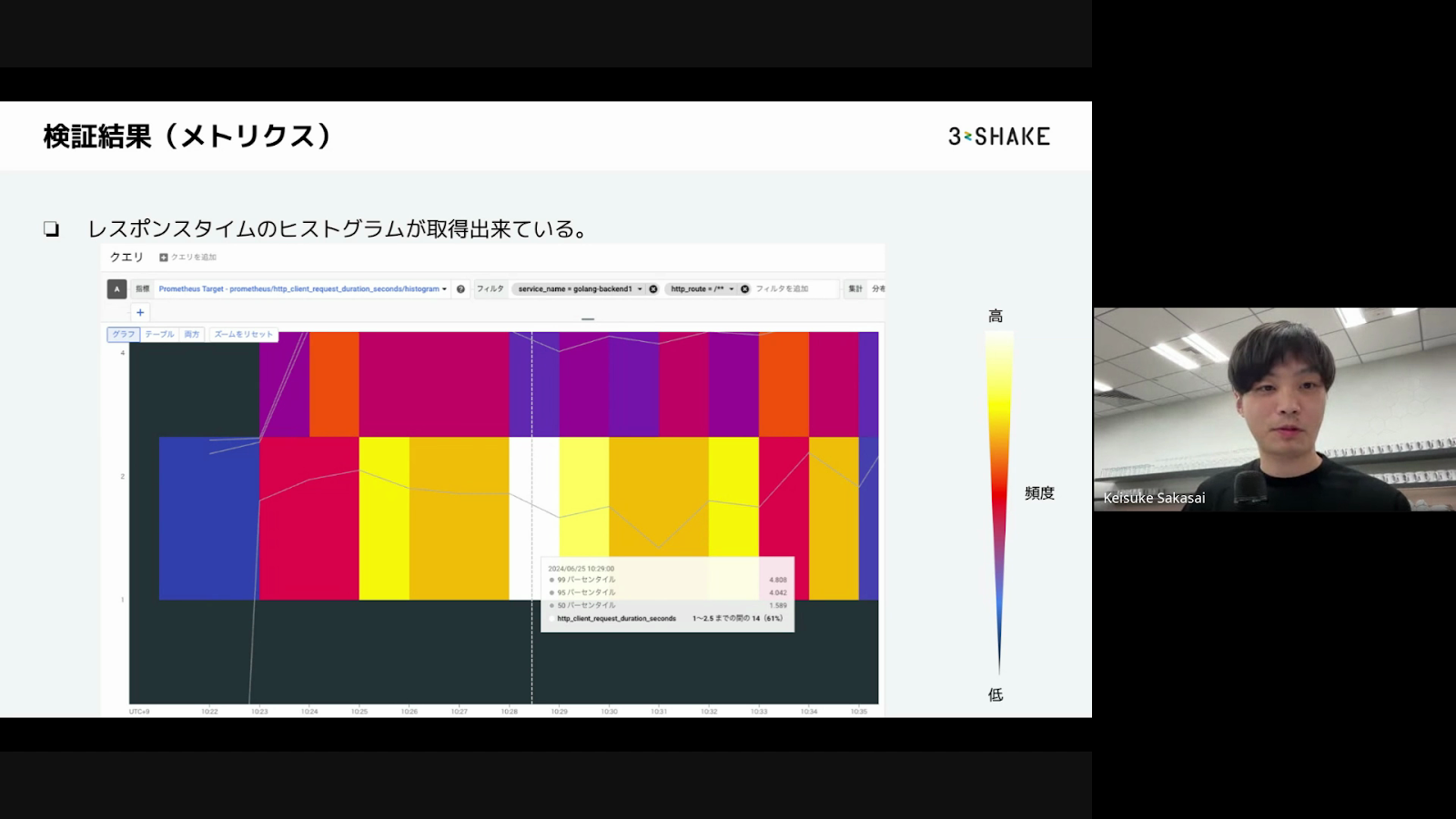
岩崎さんは、サンプルの構成で実行を行い、Beylaでの見え方についてお話していただきました。Beylaはアプリケーションコードを一切触らずに分散トレーシングを実現できる技術です。ただし、現状ではGolangしか対応しておらず、アプリケーションの形式によっては対応するライブラリが少なく、詳細なトレーシング情報を取得できないといった課題も抱えているそうです。今後の発展に期待していると岩崎さんは話しています。
座談会
最後に、本イベントのタイトルである『クラウドに依らないオブザーバビリティ』をテーマに、座談会を行いました。
座談会には以下の3名にお話しいただきました。
- 株式会社ユーザベース 安藤 裕紀 さん
- 株式会社スリーシェイク吉田 拓真 さん
- 株式会社サーバーエージェント 岩見 彰太 さん
トークテーマとしては以下3つになります

- 「ちゃんとやろうとすると、お金がかからないですか?」
- 「O11yを実装するツールと選定理由は?」
- 「普段どういう監視情報を見られますか?」
最初のトークテーマ「ちゃんとやろうとすると、お金がかからないですか?」について、吉田さんは、オプザバビリティツールを使用すると、お金がかかるという認識は間違っているとし、むしろ費用対効果が高いと考えていると回答しました。具体的には、従来は人手に頼っていた監視をツールによって自動化することで、人件費削減につながることを説明しました。また、ツール導入によって監視の精度が向上し、より的確な対応が可能になるため、サービスの品質向上にもつながると説明しました。
「O11yを実装するツールと選定理由は?」について、岩見さんは、自社では主にDatadogとトレースを使用していることを説明しました。Datadogは、社内におけるデータのログ管理に利用しており、トレースは、システムの動作状況を詳細に追跡するために使用しています。Datadogは、比較的安価で使いやすく、大規模なデータの収集と分析に適していることから選択したと説明しました。トレースは、システム全体の動作を把握し、ボトルネックを特定するために使用しており、より深いレベルの分析や問題解決に役立っていると説明しました。
「普段どういう監視情報を見られますか?」について、あんどぅさんは、自社では、ユーザーの行動ログ、システムのエラーログ、ビジネス指標などを監視していることを説明しました。また、監視対象となる情報は、サービスの規模や複雑さによって異なることを説明しました。例えば、小規模なサービスであれば、ユーザーの行動ログを監視するだけでも十分な場合があります。しかし、大規模なサービスや複雑なシステムでは、エラーログ、ビジネス指標など、より多くの情報を監視する必要があると説明しました。さらに、監視情報は、システムの安定稼働を確保するために不可欠であり、常に監視情報をチェックし、必要に応じて対応することが重要であると説明しました。
途中Datadogの木村さんも参加していただきDatadogでのAIを使った機能についても話ししていただいたりなどより深い話が展開されていきました。
会場の様子


集合写真

最後に
クラウドネイティブ分科会では、今後もおよそ3ヶ月に1回のペースでのMeetupを開催していく予定です。次回は、8/30 にはビアバッシュ LT をしていきます https://connpass.com/event/324998/edit/。
こんな回をやって欲しいなどの要望はクラウドネイティブ分科会の slack チャネルにていつでも募集しています。
また、Meetup以外にもSlackでの交流も実施しております。
この記事を読んでご興味を持たれた方は、ぜひJagu’e’r への会員申込みをお願いします!