
活動報告: ヘルスケア分科会 第6回イベントレポート

第6回のMeeupはオンラインでの開催となりました。
お昼の時間に40分程のMeetupでしたが大変密度の濃い充実した回となりました。
それでは、最後までご覧ください。
ヘルスケア分科会について
ヘルスケア分科会では運営メンバー、参加者共に募集しております。
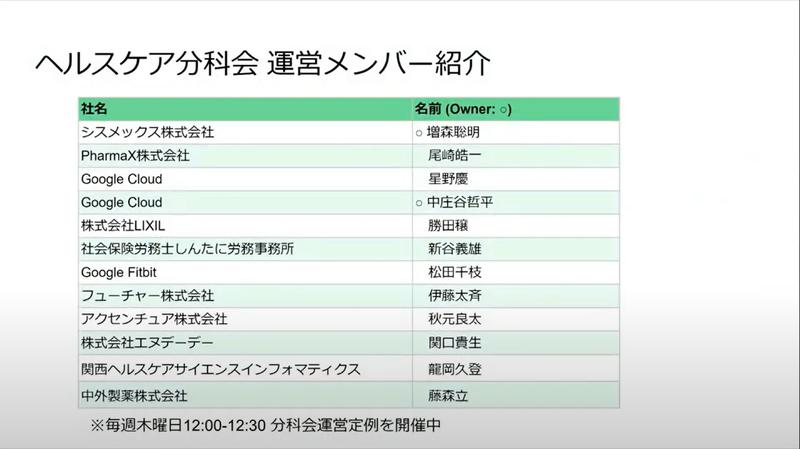
現在の運営メンバーを紹介します
(TD SYNNEX株式会社 / 吉川 洋太郎)
中外製薬株式会社 / 藤森 立様「Next Tokyo ’23 Recap」
最初に中外製薬の藤森立(ふじもりりゅう)さんにGoogle Cloud Next Tokyo ‘23にて行われた中外製薬セッションのRecapをお話いただきました。

Google Cloud Next Tokyo ‘23では45分のセッションでしたが、10分程度に内容をギュッと圧縮してお話いただきました。

藤森さんはマーケティングへのデータサイエンスの活用でご活躍中です。
その一環でGoogle Cloudの導入・活用を担当されています。Professional Data Engineerでもあるのですね!
中外製薬の進めるDX
中外製薬はがん・バイオに強みを持つ、研究開発型製薬企業
医療用医薬品メーカーとして日本トップクラスの売り上げを誇ります!
DXをキードライバーとした成長戦略「TOP I 2030」を掲げています

AWSやMicrosoft Azureを利用している中、2023年からはGoogle Cloudも利用を開始しています。
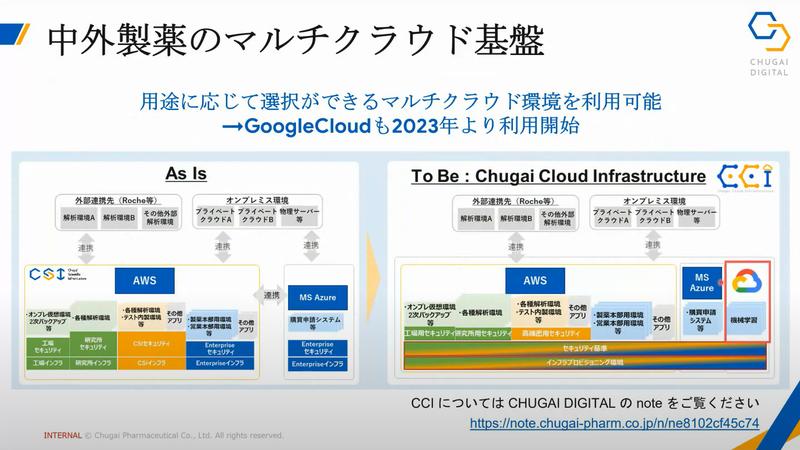
主に機械学習分野で使用されているのですね。
創薬におけるAI活用
テーマは「Cloud Workflowsを用いたAlphaFold2並列計算パイプラインの開発」
ハイパフォーマンスコンピューティングをいかにして実現したのでしょう?
まずは創薬研究について説明がされました。
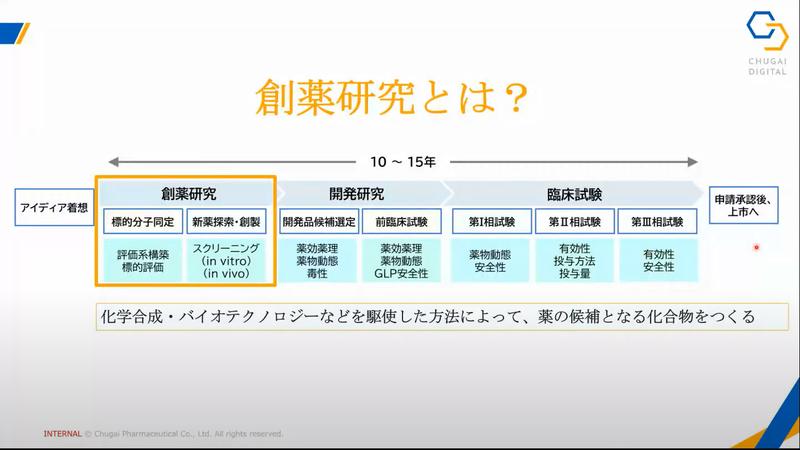
アイデアが実際の薬品となるまでに10~15年という莫大な時間がかかっていますが、創薬研究はその最初の部分となります。この創薬研究で当たりがでないと次に進めないことから、この創薬研究プロセスをいかに効率化し、成功確率を上げるかということが大変重要になっているようです。
現在、様々な研究機関や企業から新しい学習モデルが次々と公開されています。
(MegaMolBART、Diff-dock、AlphaFold2、OpenFold、Geneformer、RF diffusion、ESMFold等)
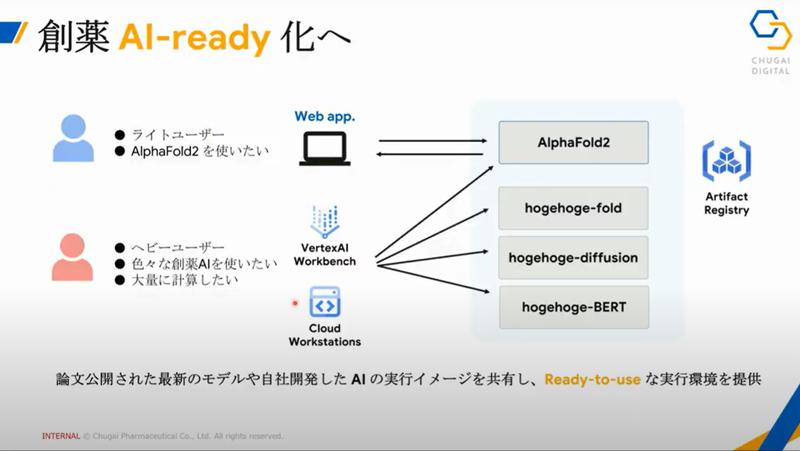
これらを順次Google Cloudで使用できるようにしようとしているようです。
今回はAlphaFold2に対応しました。
AlphaFold2はアミノ酸塩基配列から推論をするモデルとなります。

AlphaFold2の計算は大変高度で複雑です。
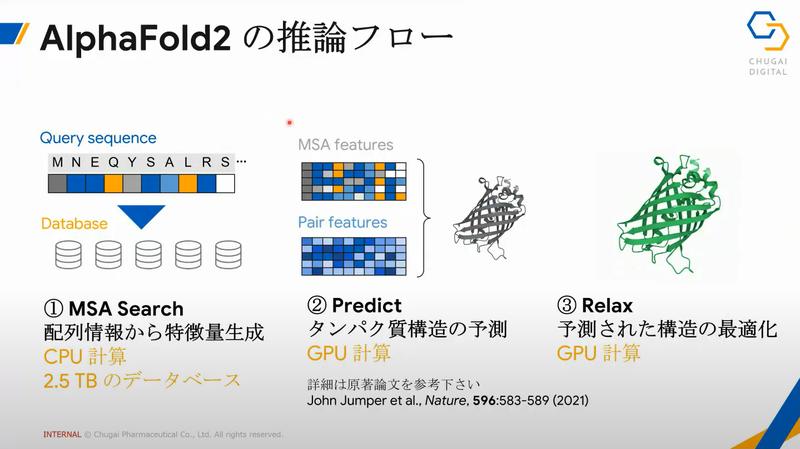
CPUでもGPUでもヘビーな計算が必要です。HPCでも数時間かかったりします。
Google Cloudはこうしたヘビーな計算も得意!Cloud WorkflowsのBatchを使うことにしました。
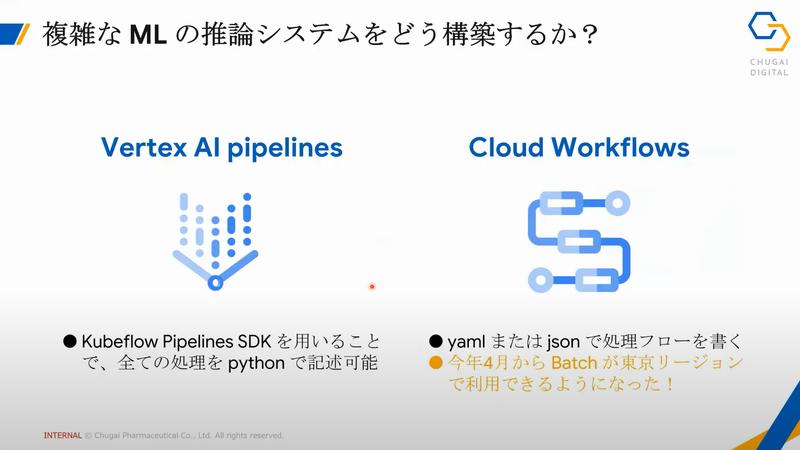
Batchを使うことでCompute Engineを使うことになります。
SpotVMが利用可能だったり、Cloud Storageをマウントできたりというのはコスト面でも嬉しいですね。
SpotVMを使える点は現場でも盛り上がりポイントだったとのことです。

1日に1000以上のタンパク質の構造予測を可能にしました。
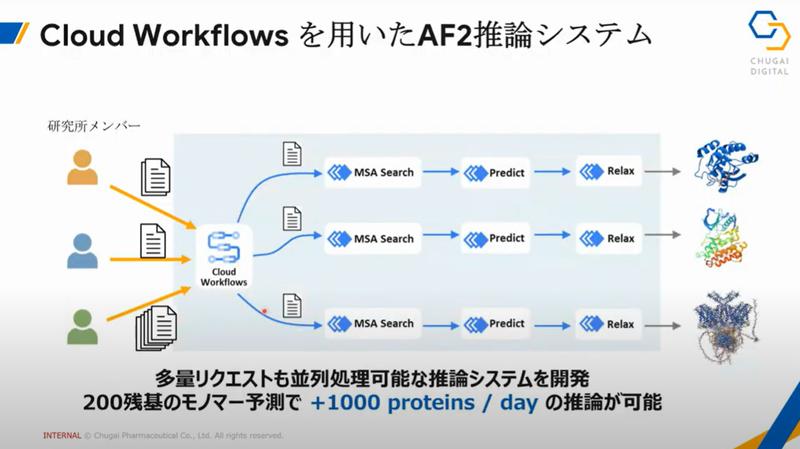
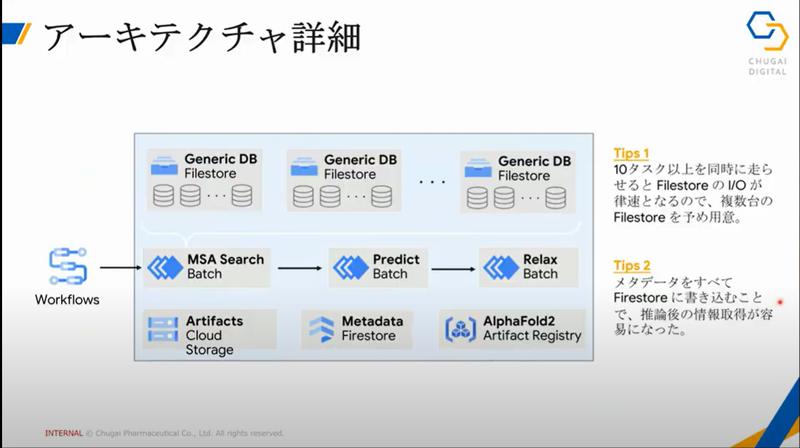
内製開発グループ、GoogleのTAP (Technical Acceleration Program)と共同でアーキテクチャを検討しました。
WebアプリとAlphaFold2本体をしっかりとつなぎあわせることでユーザーフレンドリーなWebアプリの開発に成功しました!
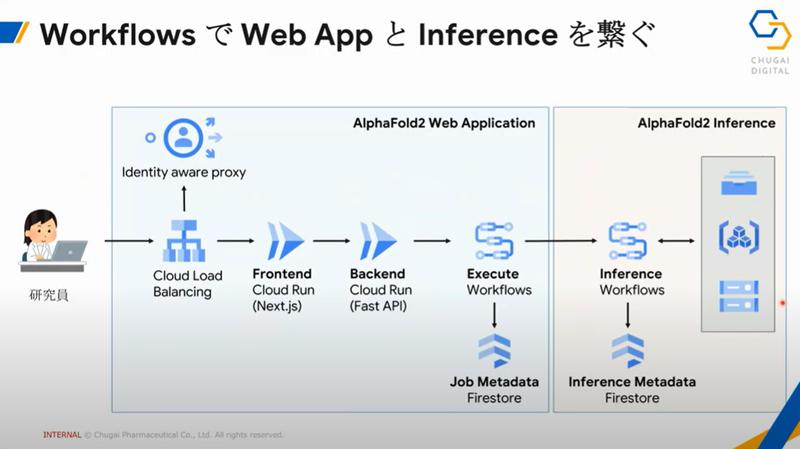
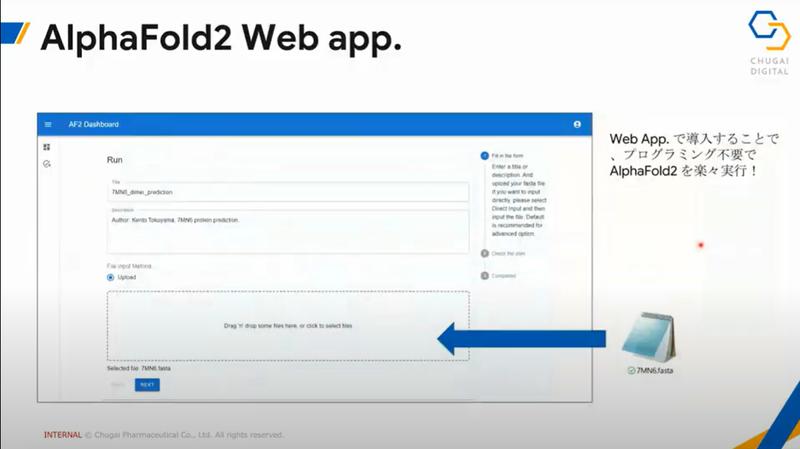
プログラミングのできない研究員でも利用可能な形になりました。
そしてヘビーなユーザーもバリバリ使えます。
Generative AIの取り組み
ここまでで時間を使いすぎたのでここからはざっくりと笑
LangChainを利用して類似したスライドを検索するシステムを構築しています。

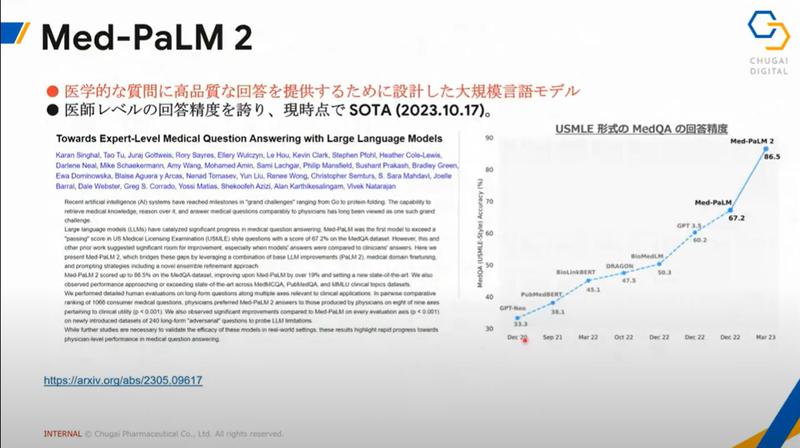
国内ではじめてユーザーとしてMed-PaLM2を使用しています。
かなりの精度での回答を実現しています。
今後の発展がとても楽しみです。
クラウド人財の育成
最後にクラウド人財の育成についてです。
製薬企業はデータの取り扱いに色々と制限があるため、社内でGoogle Cloudなどをしっかりと扱える人財はとても重要。

Googleの協力も得てスキルチャレンジを実施、結果的に22名の有資格者を育成できました。

TAPにとてもお世話になったとのことです。

Jagu’e’rにも積極的に参加してくださっています!!

まとめ

- AF2を基幹として様々な創薬AIを構築しています。
- ハイレベルなモデルを手間をかけずに運用するにはBatch + Workflowsによる実装がお勧め!
- 生成AIも頑張って活用中です!
TAPは2~3日、Googleのオフィスに缶詰になる密度の濃い時間。是非実施してみてください。
(TD SYNNEX株式会社 / 吉川洋太郎)
株式会社MICIN / 硴﨑 裕晃様「ChatGPTで医師国家試験に合格した話と、ヘルスケア領域における生成AIに関する論文紹介」
(本記事で掲載している画像はConfidentialと記載のあるものを掲載していますが、MICIN様の許可を得て掲載しております)
つづいてMICIN(マイシン)の硴﨑さんによる、ChatGPTで医師国家試験に合格したという論文の共著者という立場から、その内容の概要や見えてきた課題などを紹介していただきました。

硴﨑さんのプロフィールを拝見すると、ずっとAIに関わっていらっしゃるようです。すごいですね。
現在、MICINさんでは2023年4月にオンライン公開した金沢大学と実施した研究を始め、複数の大学との共同研究や、日本デジタルヘルス・アライアンス(JaDHA)といった業界団体において生成AIに関わる研究やヘルスケア領域におけるガイドラインの作成などに関わっていらっしゃるとのこと。
医療分野における生成AIの全体観について説明していただきました。私たちが病気になって医療機関で治療を受けている時にLLMなどの生成AIを用いるのは、現状ではまだまだ厳しいとのこと。一方で、問診や薬局関連など治療の前後のフェーズではLLMは活動できるだろうというのが総論だそうです。
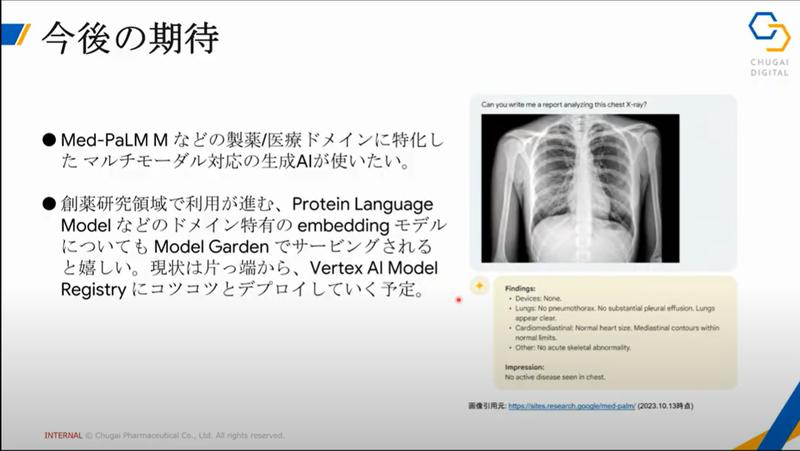
一方、医療のデータにフォーカスした場合は、今までうまく扱うことができなかった非構造化データ(画像や文章)をマルチモーダル系のモデルで使える様になってくることで、データ活用がさらに進むという点で生成AIに期待しているというのが硴﨑さんの意見だそうです。
確かに生成AIもまだまだ途上なので、治療に使うイメージはまだありませんね。硴﨑さんのおっしゃるとおり、これからデータを利用できるようになるというのが現実的だと思いました。
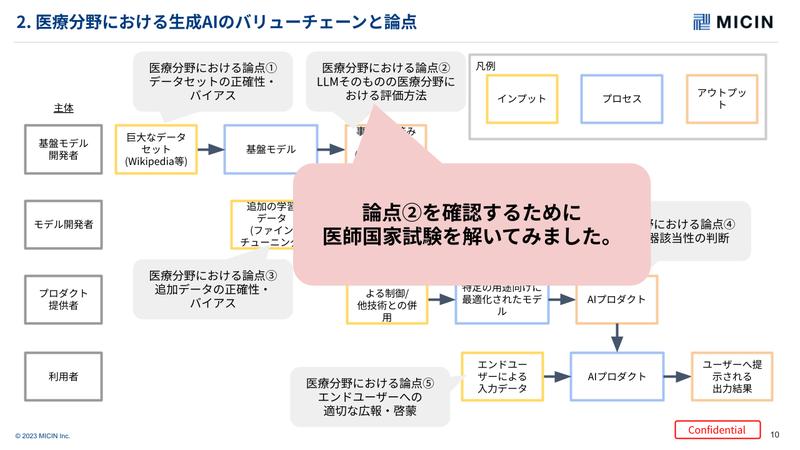
生成AIのモデルを作っていくプロダクトマネージャとしての視点からそのステップなどを考えていくと、各ステップや関係者おいてさまざまな課題があるそうです。
さまざまな課題がある中で、今回の発表では一般的なLLMの評価指標とは異なる視点で医師の視点から見たときに医療分野に特化したLLMの評価はどうなっているのか?という観点を紹介していただきました。
冒頭に紹介のあった、今年の4月に発表されたMICINさんのプレスリリースでは、ChatGPTとGPT-4を使って医師国家試験に合格できたということが発表されています。
合格はできたものの研究チームとしては、20%の誤りという部分に課題を感じたそうです。
何故なんでしょう?

それは、間違えた問題を分析していくと、特定の疾患について誤りが集中しているわけではなく、多岐にわたる疾患において少しずつ医療知識の不足が原因で間違いが発生していたということだそうです。
「少しずつならばいいではないか?」と思うかも知れません。しかし、実際は特定の疾患にだけ誤りが集中している方が、その領域について精度を上げる対策がしやすく、全体の性能を上げるためにはベースモデルのアップグレードや医療ドメインに特化したモデルが必要になることが予想されるそうです。
たしかに、その方が大変ですね・・・受験勉強で不得意分野だけ対策すれば良い!と言われたことを思い出しました。
もう一つ間違いの特徴があり、それはLLMが英語圏のデータセットを元に学習していて、日本に特化した医療知識に関する問題は不正解が出てしまうという点だそうで、こう言った理由から日本語特有のLLMの登場も期待されているとのことでした。
実施方法としては、日本語の問題を英語にして、英語のプロンプトで質問に回答させるということをやったそうで、GTP-3.5からGPT-4では飛躍的な精度の向上が見られたという結果も出ているそうです。
やはり、話題のLLMといっても、日本語に関して言えば、データセットが世界から見るとごく一部でしか無いので、英語でにならざるを得ないのでしょうね。
それから、先行研究の中には、特定の疾患には合格しても、他の疾患では合格できないという結果も出ているそうで、臨床に用いるためにはまだ検証が必要だということがわかっているそうです。

医療特化したLLMはBERTをベースにしたものが以前より数種類発表されているそうで、今回はその中でMediTronという最新の医療特化型のLLMについて説明をしていただきました。
MediTronはオープンソースLLMのLlama2をベースに作成されており、学習コーパスにも医療特化したPubMedや臨床実践ガイドラインなどを用いているそうです。いずれもオープンな技術、オープンなデータを用いているというところが特徴で、精度についてはMed-PaLM2には劣るものの、GPT-3.5には勝る結果がでていることから、クローズドな技術に頼らずとも、それなりに精度が上がることに期待がされているそうです。
しかし、やはり学習コーパスは英語圏のものになっている可能性もあるため、日本の臨床現場に合うのか?というところには課題があると感じているとのこと。
最後にマルチモーダルの分野ついては放射線領域の研究を注目するといいという話も伺いました。放射線分野では、画像とレポートがペアのデータセットがあるということから、それらをセットで学習させて推論させる数年前から先行研究が行われているそうです。
医療向けの生成AIには多くの課題がありつつも、着実に進んでいるのだという事を教えていただきました。現状は英語による研究が先行しているようですが、MICINさんをはじめ、他の日本企業も日本向け医療AIの開発に力を入れているようですので、今後に期待しましょう!
(株式会社エヌデーデー / 関口 貴生)
所感・まとめ
今年最後のMeetupとなりましたが、お昼の時間帯にも関わらず、非常に内容の濃いMeetupとなりました。創薬や臨床においてもMLやAIの活用が注目されていることを改めて知ることができました。
今年も多くの方に発表していただきありがとうございました!2024年も引き続きヘルスケア分科会では、有益な情報共有や双方向の学びにつながる活動や企画を続けていきます!
この記事を読んでご興味を持たれた方は是非 Jagu’e’rへの会員申し込み & ヘルスケア分科会へ申し込み をお願いします!
(株式会社エヌデーデー / 関口 貴生)