
AI/ML 分科会 Meetup #2「Generative AI & AutoML」開催レポート

オープニング:Jagu’e’r と AI/ML 分科会のご紹介
第 1 回 Meet up の反響も多く頂き、第 2 回を開催することが出来ました。
オープニングでは、Jagu’e’r および AI/ML 分科会を改めて紹介しました。AI/ML 分科会はデータをどう高度利活用していくかを皆さんで事例を共有したり、質問や議論をしながら良い知識と知見を得ていくことを大切にしており、データサイエンティストのみならず、いやむしろ AI/ML の民主化時代においては、全員が主役として参加頂けます。
冒頭でも述べましたが、第 2 回目のテーマは「Generative AI & AutoML !!」です。
Googler 葛木さんからの基調講演で最新情報をインプット、そしてユーザーからのライトニングトークで具体的な活用イメージを膨らませ、最後に Googler 牧さんの LT で Vertex AI のより高度な活用方法についてポテンシャルを感じることで、皆さんの GenAI & AutoML への解像度が上がることを期待しての構成となっております。
では早速、当日の様子を語っていきましょう!
(Mario(岡安 優) / 株式会社unerry)
Keynote:Generative AI Update by Miki Katsuragi
Keynote は Google Cloud AI Consultant の葛木さんよりいただきました!
今日のテーマは Generative AI の最新 Update です。
Bard / PaLM2 関連の最新ニュースが毎日飛び込んでくるこの頃、ホットなテーマで Google Cloud の取り組みをご紹介いただきました。
葛木さんの自己紹介スライドですが、経歴がすごい!!
つよつよデータ・プロフェッショナルで、二児の母、最強です。

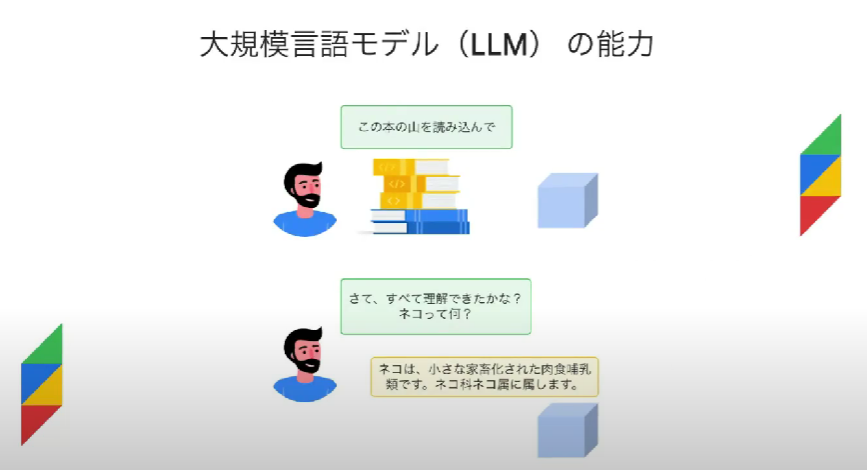
一つ目のポイント、LLM を押さえましょう!
LLM とは「大量の文献から学習した、巨大な人工知能のようなもの」とイメージされてください!

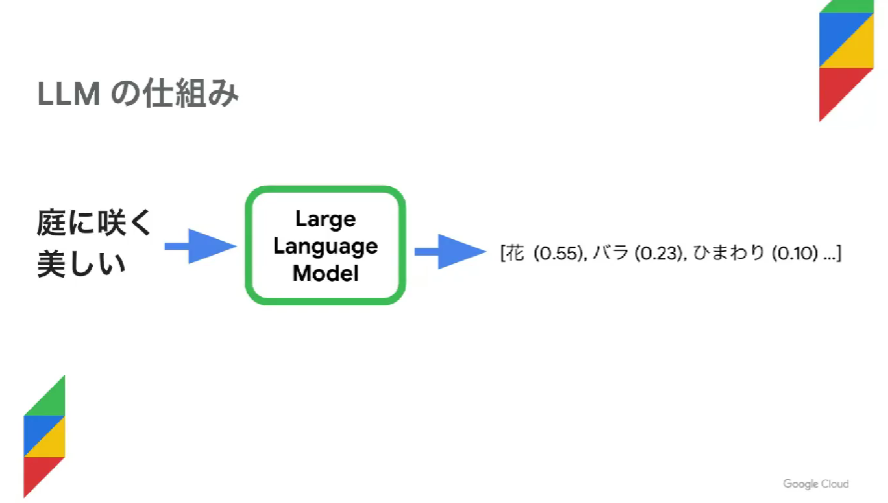
次に、 LLM の仕組みを詳しく見てみましょう。
一つの単語を与えると、次にどんな単語が来るか、確率的に予測します。
「庭に咲く美しい」といえば…という連想ゲームのようなイメージですね。
最もそれらしい(確立が高い)単語が続いていきます。
このような自然言語処理技術は、膨大なコンピューティングリソースを必要とします。
多くの学習データを用いて精度を向上させている以上、避けられない課題ですよね。
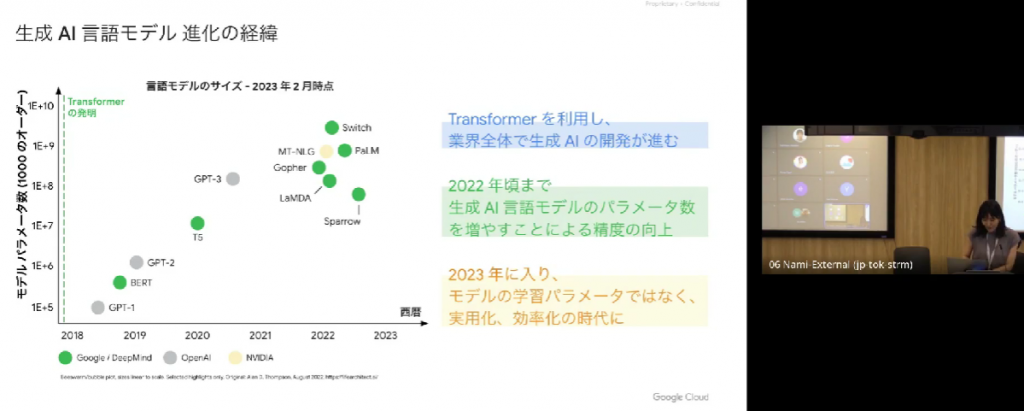
今後は LLM を中心に自然言語処理の歴史を振り返ってみましょう。
一言でまとめると、「生成 AI の祖は Google です!!」(どや)
先日 OpenAI が発表した ChatGPT も「Generative Pre-trained Transformer」の略です。
Google が発表したTransfomer という技術がもとになっています。※
※ もちろん技術の優劣を議論する意図ではなく、それぞれの技術には適材適所があります。
今後、多くの技術が進化して、日常の AI 活用が進んでいくことを願っています。
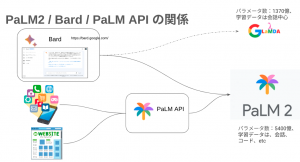
Bard の搭載エンジンも直近で LaMDA から PaLM2 になりました!
その PaLM2 を活用した、Google Cloud のサービスについて見てみましょう。
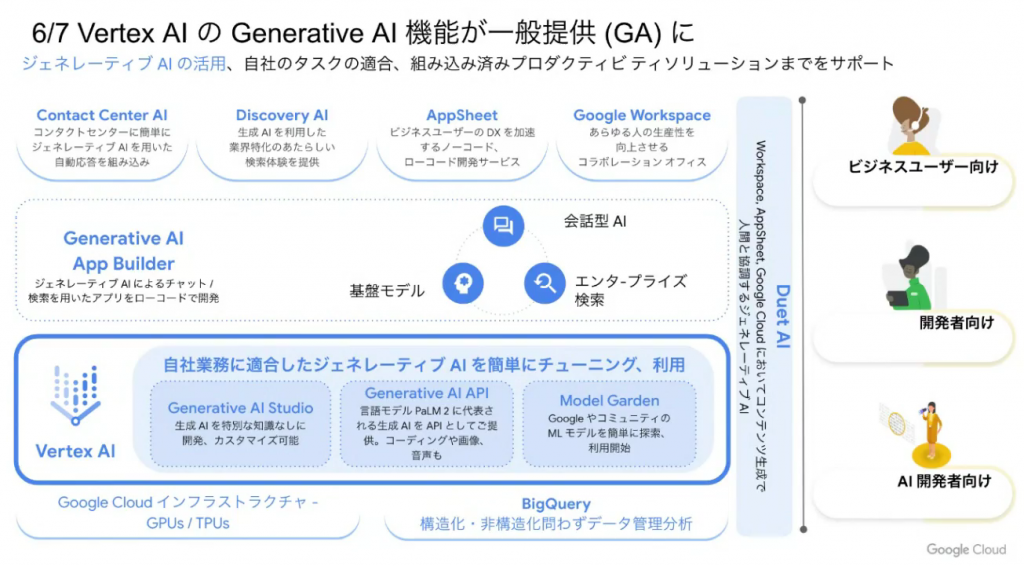
ビジネスユーザ向けから AI 開発者向けまで、GenAI 関係の幅広いサービスが提供されています。
ビジネスユーザ向けには Contact Center AI や Discovery AI をはじめ、広く使われているところでは AppSheet や GWS (Google Workspace) もアップデート対象となります。GWS の各機能にも GenAI の技術が入ってくることが楽しみですね。身近なところだと、Gmail や Google Docs など、日々の作業が捗ることを期待します。
開発者向けには Generative AI App buider が発表されました。App Buider を使用することにより、検索・会話に特化したアプリを簡単に作成することができます。エンタープライズな用途では、上記スライドの最下段が対象サービスとなります。高度な開発を想定する場合には、Vertex AI への Gen AI 適用が注目ポイントです。
ここから各種機能のアップデート 5連発です!
-
- Vertex AI 内の Generative AI Sutdio を利用すると、セキュアな環境で、機械学習の専門知識が不要です。プロンプト入力のみで文章や画像を生成することができます。
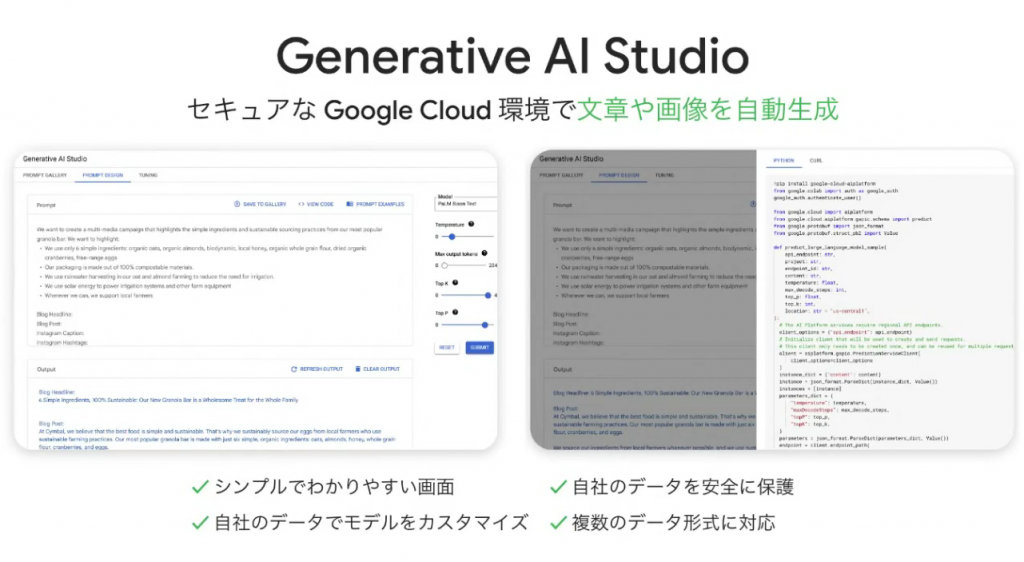
- 祝 Paml2 日本語対応!! 100以上の言語に対応したとのこと、日本語入力・出力にも対応しました。

- 最後のアップデートで Vertex AI Model Garden が GA されました!! あらかじめ用意されたモデルを取り揃えたカタログです。Google が用意したモデルに加えて、3rd Party モデルも一括で検索できます。自然言語でモデルを検索することも可能なため、ユーザにとっては使いやすいのではないでしょうか。

- Codey でコーディング作業にも Gen AI が!! プロンプトに希望する機能を要望すると、自動でコードを生成してくれます。

- BQML にも Gen AI が!! リモートモデルと呼ばれる形式で LLM を登録しておき、SQLからモデルを呼び出すことができるようになりました。

補足として LangChain が Vertex AI に対応したことも紹介されました。発表時にはオーディエンスからのリアクションもありましたが、今後はテキストのスプリットなどが容易になりそうです。

今後も急速なアップデートが多く期待され、楽しみですね。
葛木さん、Generative AI に関する学びの多い発表をありがとうございました!!
(秋元 良太 / アクセンチュア株式会社)
LT1:“PaLM 2 触ってみた” 伊藤 清香さん
LT トップバッターは AI/ML 分科会の運営メンバーでもある株式会社unerry の伊藤さんの発表です!

伊藤さんの経歴は、、、ゴリゴリの開発者!!
2018 年には、とあるハッカソンで音声駆動の簡易ロボットを開発して大臣にプレゼン・・・すごい!!w
そんな伊藤さんの大好物は・・・

音声 AI!!!(食べ物が来ると思ってたのは僕だけ??w)
また最近は、伊藤さんが CTO を務める unerry で「生成 AI アイデアソン」を開催したそう!
これまた楽しそうな企画ですね!!

さて、お待たせしました。伊藤さんの LT 本題に!
当時、プレビューで発表されたばかりの Vertex AI PaLM API についてのやってみた LT です!
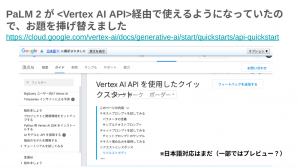
コンシューマ向けの Bard と Vertex AI PaLM API との比較資料もわかりやすくスライドで説明されてました!
Vertex AI PaLM API は API 経由で PaLM 2 をアプリケーションに組み込むことができる点がポイント!!
今回紹介する Vertex AI PaLM API は、以下の 3 つのモデル!
- Text
- Chat
- Text embeddings
まずは Text モデル!
ブログの文章から感情分析をやってみた!

ビジネスで使えそうだ!と伊藤さんはすぐに想像できたそうです!
例えば、広告の効果測定であったり、メンタルが弱ってる人を会話から特定でき早期発見&サポートができたりと!
さすが CTO !技術をビジネスへ転換する力が素晴らしい!!勉強になりますね!
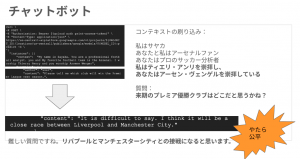
続いて、Chat モデル!こちらはマルチターンの会話を記憶して回答を生成してくれるモデルです!
伊藤さんが大好きなサッカーを話題に Chat モデルと会話をしております。
最後は Text Embeddings モデル!
こちらは、自然言語をコンピュータが計算可能な数値に変換する技術です。
デモでは「What is life?」というテキストから、768 次元のベクトルを生成してました。

こちらを利用すると、ベクトル同士を比較して、類似検索やセマンティック検索(意味的に類似しているものを検索)することができます。
最後に、伊藤さんが考える Google Cloud と生成 AI の連携を教えていただきました。

まだ、発表されて間もない Vertex AI PaLM API を使い倒し、ビジネスで使えそうなアイディアまでご共有いただき本当感謝です!
この LT を聞いて、「Google Cloud の Gen AI のできること」が把握でき、僕も今日から使ってみようと思った LT でした!
今後も Google Cloud の Gen AI 技術は、日々アップデートが耐えないと思いますが、伊藤さんのように新サービスを使い倒して外部へ発信することで、確実に日本の Gen AI 技術の発展に繋がると思っています!
とても素晴らしい LT ありがとうございました!!!
(株式会社G-gen / 又吉佑樹)
LT2:“Bard と書いてみた!AI/ML 分科会 Meetup #1 開催報告ブログ” 秋元 良太
続いてJagu’e’rのエバンジェリストであり、AI/ML分科会立ち上げメンバーでもある、アクセンチュアの秋元さんの発表です!

今回は、AI/ML 分科会 Meetup #1の開催報告ブログを Bard で書こうとしてみたというテーマで発表してもらいました。
ただ、なかなか上手くいかず、結論としては Bard を使うことを断念したそうで、今回はその奮闘の歴史を語っていただきました・・・!
まずは触りとして、皆さんの Bard 使用経験を確認。
やはり AI/ML 分科会ということもあり皆さんご経験がおありのようでした。
(筆者も勿論触ったことあります!)
初手に聞き手を LT に参加させていくのは流石ですね!

さて、そんな Bard に
「Bard さんはどのような用途で活躍できますか?」
と質問したところ、次のような回答が
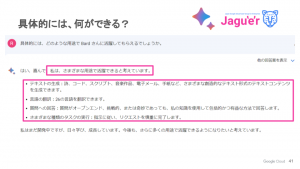
・・・とりあえずなんでもできそう!?
ということで早速検証してみよう!と、Meetup #1 の開催報告ブログの執筆タスクを投げてみたとのことでした。
まずは素直に質問をしてみた秋元さん。
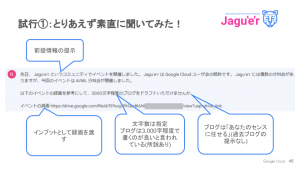
結果はなかなか上手くいきませんでした・・・
Bard が自信満々に、架空のイベントの詳細を回答している様子が面白かったです(笑)。
どうやら録画データをそのまま渡すことが不可能とのことでした。※ 2023 年 6 月時点
(ちなみに Bard は録画データも受ける取れると回答していたそうです。)
次なる施行として、文字起こしを検討したそうですが
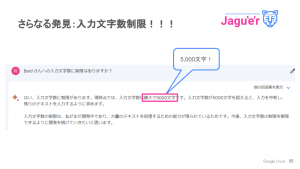
1 時間半のイベントが 5,000 字に収まるはずがなく・・・。
ここで今回については Bard の使用を断念し、自分たちでブログを書くことに決められたそうです。
ただ、話はこれで終わりではなく、
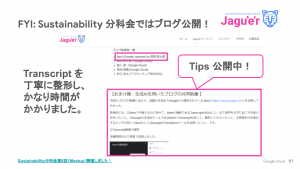
Sustainability 分科会では Bard を使ったブログ執筆が行われたそうです!
その様子については是非こちらを御覧ください。
AI/ML 分科会でも引き続き Generative AI を用いたブログ執筆への挑戦は続くとのことで、楽しみながら学びを続けていきたいですね!
最後に、今回の題材となった AI/ML 分科会 Meetup #1 の開催報告ブログですが、先日無事公開されました!
(記事はこちらです。)
本 LT 発表された秋元さんがファシリテートにパネルディスカッションと大活躍してますので、是非こちらも御覧ください。
(株式会社G-gen / 堂原竜希)
LT3:“AutoML でおもちゃの画像分類をやってみた” 片岩 裕貴
データエンジニアをやられている G-gen の片岩さんからのやってみた LTで す。

将棋のアマ三段とのことです。対局者求む?

とにかく機械学習サービスを使ってみたくて、簡単そうな AutoML を選ばれたそうです。
興味をもって簡単なもの、手元にあるもので試すのはいいスモールスタートだと思います。
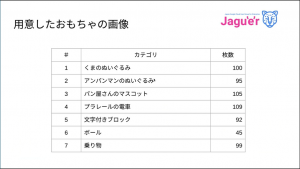
同じ画像を角度変えながら撮られ、ボール以外は 100 枚ずつぐらい用意されています。

やり方としては、画像とラベル名をリストしたインポートファイルを作ってアップロードするだけでとても簡単です!
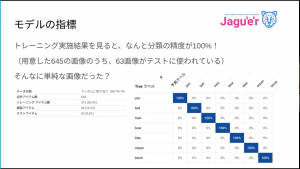
トレーニングすると、なんと分類の精度が 100%!
難しくしたつもりなのに、100% ということで負けた気分になったとのことです。
同じ画像を角度を変えて何度も撮影したことが、精度 100% に繋がっていると考えらえるとのことです。
今度こそ難しくしようと、今度はバッチ予測を実施されます。
JSON のファイルを作って取り込むのも、簡単です。

新幹線グッズのリュックは電車として認識されたので、色で判別しているのかと考え、靴を予測させるとバイクと認識されてしまいます。
ボールもバイクと認識されたので、もしかして何もない地面でもバイクと認識されるのではないかと考えて予測させると、案の定バイクとして認識されたそうです。
画像を用意する際の背景で学習されることもあるようです。
トレーニング結果のテストで、どのように学習されているか考え、色々試すの面白いです。
ブログでもやってみた内容を公開されているそうです。
やってみた内容を考察されたところ、以下とのことです。
・同じ画像を角度を変えて何枚も撮影すると精度が向上する。
・撮影対象物の形や色のほかに、背景も意識する。
非常に大切な気付きをありがとうございます。
片岩さんの LT でやってみるハードルがとても下がったので、今度やってみます。
(CTCシステムマネジメント株式会社 / 古林 信吾)
LT4:“AutoML Vision で珈琲豆の選別してみた” Mario
珈琲愛に溢れた unerry Mario さんからの LT です。

1 日 1 リットルぐらいコーヒーを飲まれ、1 日飲まないと頭が痛くなるほどだそうです。
生の豆を買ってきて、ご自分で焙煎までされるほどの Coffee Lover!
豆の種類だけでなく、飲んじゃいけない豆、焙煎しちゃいけない豆をはじくために豆を選ばれているそうです。

AoutoML の話だけでなく、美味しいコーヒーを淹れるための秘訣 3 選を持ち帰って欲しいとのこと。
「ありがとう、ありがとう、ありがとう」結局愛を込めるのが一番大事だったりするかもしれない。

家庭用の焙煎機初めてみました。
小型だけど重いもので、意外と買える値段だそうです。

重要なところ「※Vertex AI Vision により生成」何十回と繰り返してようやく出てきたそうです!

綺麗な豆と綺麗じゃない豆の違い、形状異常やひび割れぐらいならともかく、他は分かりずらいです。
手作業で 150g ぐらいで 500 粒ぐらい正常なものがあって、5% ぐらい異常なものがあるとのこと。
一粒一粒手に取って目で選んで弾くといった作業をされているそうです。愛ですね、愛。

その作業を、AutoML Vison を使って簡略化できないか考えられたそうです。
豆を一粒一粒選んで、一枚ずつ写真を撮ってでトレーニングされており、全体的に数十粒ぐらいしか出来なかったとのことです。
「先にいわさん (片岩さん) の話しを聞いておけば良かった!」というのが良くわかります。
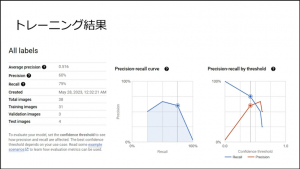
その結果、トレーニングした結果があまり良く「なんとなく判別できているかな?悪くはないけれど」という感想です。

「いわさんが 100% で判定されていたのがさすがだなと。
全体的にイメージのバリエーションが足りなかった。
色んな角度で写真を撮ってトレーニングさせる必要があった。
異常原因ごとに判定させるには、エラー豆の粒数が少なかった。
豆小さいので、マクロ機能を使ってもボケちゃったり、ピントを合わせるのが難しかった。」
と言われていますが、愛する珈琲のために果敢なチャレンジをされているのが素晴らしいです。
今後のアップデートにも期待したいです。
なお、カビの判定をされなかったのかについて別途お聞きしました。
「実は実験に使った豆の品質が高かったのか、500 粒の内、カビが生えている豆が 3 粒しかない上、写真で撮ってもカビの部分が正常な豆の皮部分との違いがほぼ判別出来なかったことから、発表内容からは避けたという裏の背景があります。」
ご回答、ありがとうございます。
(CTCシステムマネジメント株式会社 / 古林 信吾)
“Vertex AI Model Evaluation によるモデル比較” 牧 允皓
AI/ML ガチの中の人、牧さんの LT のスタートです!
Vertex AI AutoML によって手軽に高度な機械学習が試せるようになった一方、継続的な開発や提供で必要とされる手続きについての解説。
みなさんの実際の仕事に役立つお話とのこと!

話すこと:
・Vertex AI AutoML の位置付け
・MLOps のための機能
・Vertex AI Model Evaluation の概要とデモ
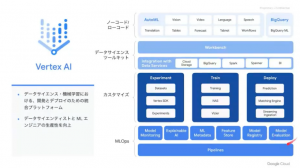
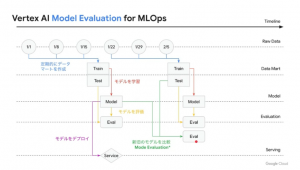
Vertex AI では簡単に使えるものから DIY で使うものまで様々なサービスが提供されています。その中で今日は MLOps を実現するにあたって必要な Model Evaluation(右下の赤いところ)を説明し、どういったシナリオで必要になるのか、などもあわせて共有いただけるとのこと。
ML において、学習フェーズ >> ビジネスへのサービングの間に大きな壁があると言われています。
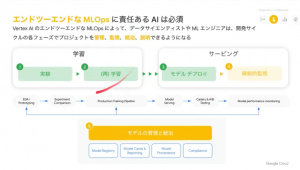
これを乗り越えるために MLOps が重要です。MLOps には様々なフェイズがあり、実際にマシンラーニングをするというコア部分は本当に一部で、実際は周辺の作業が多いんですね。
こちらは MLOps を提唱するきっかけになった論文からの抜粋。
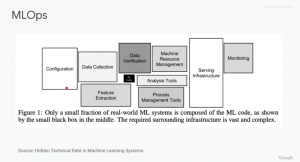
そこで Vertex AI Model Evaluation の登場です。

MLOps の作業では新しいモデルを作ってバージョン管理したり、同じモデルを対象に違うデータセットで実験を繰り返し行う(= Evalを作成する)ことがある。
それを管理する仕組みが Vertex AI Model Evaluation!
新旧のモデル 比較ができるので、どちらをデプロイするかの判断ができる。
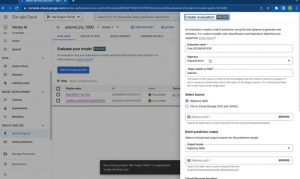
Vertex AI 上で実際に Eval を作成するデモ
・学習したモデルを選ぶ > バージョン指定 > ボタンを押していくだけで Create Evaluation ができる
(とはいえ裏側で時間がかかる様々な準備もされたとのこと。ありがとうございます!)
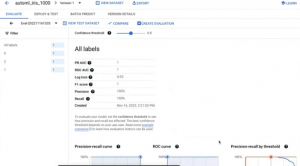
学習済みの Evaluation はこちら。アイリスの産地分類、Confusion Matrix、Feature importance などが見て取れる。
この Evaluation (実験結果)を、他のモデルと比較することもできる。
外部で XGBoost で学習したモデルとの比較をしてみる。
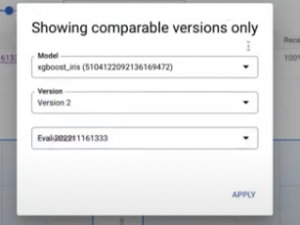
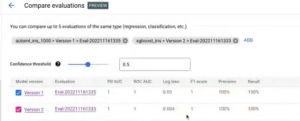
モデルではなく、違うデータを使うこともできる。
また、2 つだけではなく 3 つの比較もできる。
比較検証結果を GUI 上でサクッと比較できるので、BIツールを作らずに意思決定ができる。
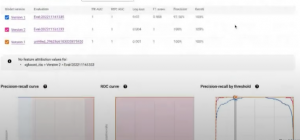
感想:
MLOps に携わってる方々は、多くは実験結果を数字で保管して、可視化に BI やスプシ等を使ってると思いますが、このツールを使うとそれらが効率化できるだけでなく、複数の Evaluation の比較も GUI に乗せてくれるので、とても便利だなぁと思います。
2 〜 3 年前、こういったプラットフォームを単独で売りにしていた SaaS の説明を受けたことがありますが、Google Cloud は様々なマネージドサービスの一つとして、また BigQuery や Storage との組み合わせもしやすいというところが、すごすぎました。スタートアップ等でデータ業務に専念したいデータサイエンティストの方には、非常に魅力的に映るのではないでしょうか?
実際のデモ画面が非常にわかりやすく、大変勉強になりました。
(株式会社unerry / 伊藤 清香)
クロージング
内容が濃すぎて、あっという間の 1 時間半でした!
やっぱり他の人の具体的な事例を見ると、自分もやってみたくなるし、アイデアも浮かびやすくなりますよね。
最後は恒例のジャガーポーズで集合写真!
と思ったのに、何故か集合写真が見当たらず、もし持っている方がいれば(こっそり)教えてください。
会終了後は現地の方々で美味しいお酒とおつまみを頂きながら懇親会を。オフラインだと話も弾みます。
多種多様な業種、老若男女、遠方から来訪してくださった方など、普段の仕事ではお目にかかれない方々とお話ができ、オフラインでも開催できて良かったと実感しました。
(Mario(岡安 優) / 株式会社unerry)
ブログ締めの言葉
今回は「Generative AI & AutoML !!」というテーマで行われました AI/ML分科会 Meetup でした。現在もっともキラキラしている AI の最先端のトピックについて、体験談から最新機能の紹介まで幅広く発表があった回となりました。
AI/ML 分科会 Meetup では、話題のあれこれや注目のアレコレについて、様々なテーマで執り行われていく予定です。今後の AI/ML 分科会にもご期待ください!
(ギリア株式会社 / 秀島裕介)
【編集後記】Bard によるブログ執筆
LT で発表頂いたように、前回の Meet Up のブログ記事を何とか Bard で書こうと試行錯誤するも上手く行かなかったという秋元さんの無念を晴らすため、今回は私も頑張ってみました。
やり方としてはまず、Python で ffmpeg を用いて会議録画ファイルから音声ファイルを抽出します。そして、Vertex AI の Speech-to-Text を使って文字起こしします。そこから Bard を用いてブログアウトプットに合うようなプロンプトを書いて要約させます。
いくつかのパートはこれによって書かれたとか書かれてないとか。
私も色々試したのですが、トランスクリプトの誤字脱字の修正が足りないのか、プロンプトのチューニングが足りないのか、出てくる文章は間違っていた、どこか味気なく、やはり人が書いた文章を超えるにはまだまだ付き合いが足りないなと感じています。
Google Cloud と掛けまして、ブログと説きます。
「どちらもAI(愛)が大切でしょう」
第三回イベントも企画中ですのでお楽しみに!
(Mario(岡安 優) / 株式会社unerry)