
AI/ML 分科会 Meetup #5「BigQuery 勉強会」開催レポート

みなさん、ご無沙汰です。三度の飯より BigQuery 大好き、Mario です。
昨年末(2023年12月12日)のお話で恐縮ですが、AI/ML 分科会としては初めての試みとして、「BigQuery を初めて触る方〜初心者向けの勉強会」を開催しました。
恐れ多くも私が講師を務めさせていただき、そもそも BigQuery って何?という基本のキから BigQuery ML や 生成AIによるテキスト生成といった最新の使い方を、デモとワークショップを交えてお送りしました。

開催前に皆さんの Google アカウントで Google Cloud でのセットアップをお願いしつつ、アンケートにも回答頂きました。
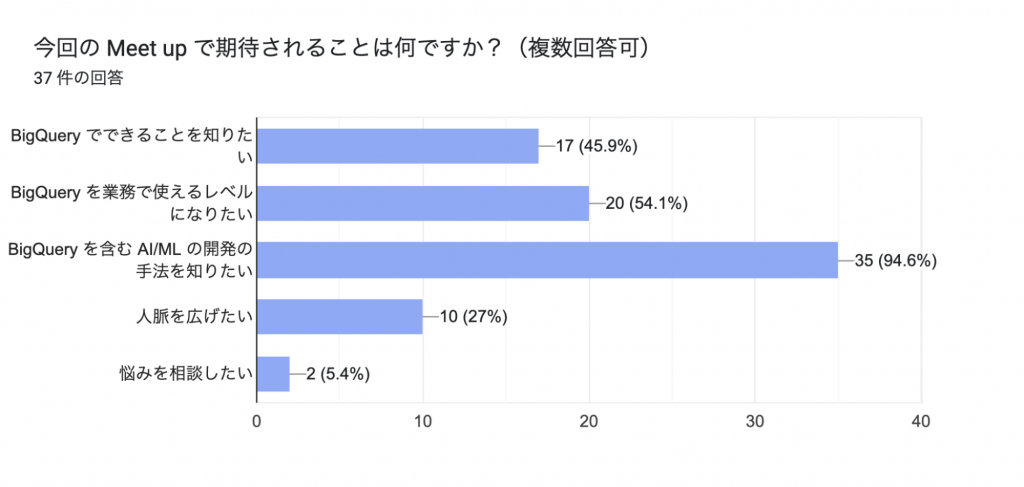
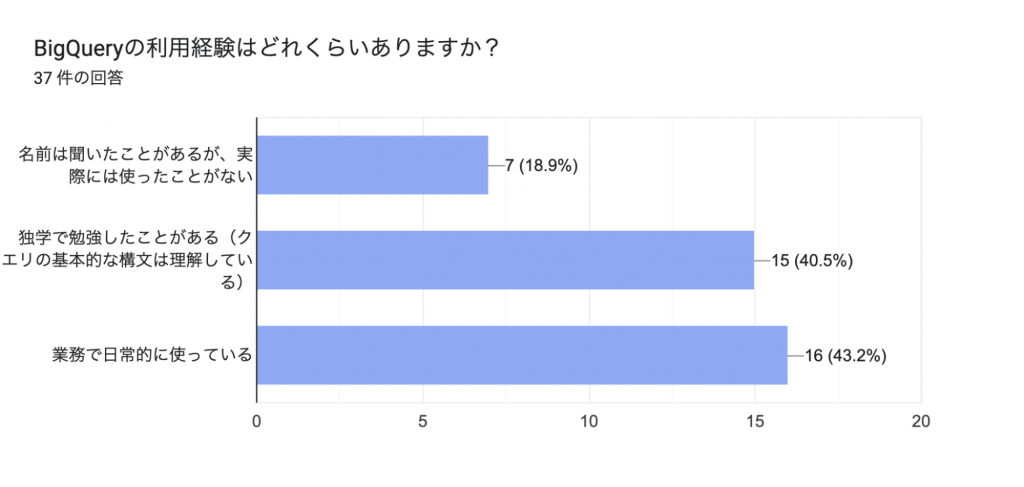
BigQuery は実際に使ったことがなく何が出来るのかを知りたいという方から、普段から使っているけれど AI/ML の開発手法が知りたい方まで、想定していたよりも BigQuery への経験に幅があり、どこまでを勉強範囲とするかは結構悩みどころでした。

全体構成としてなるべく要望にお答えしようと思った結果、広範な内容を 90 分で駆け抜ける内容でした。次回があれば、もう少し区切ってじっくりお伝えできるようにします。
資料の一部を抜粋して、どのような内容だったか振り返ってみます。

BigQuery には誰でも使えるパブリックデータセット `bigquery-public-data` というのがあります。(検索欄から探してみてね)
今回は表計算ソフトでは扱いづらい約 10GB のデータサイズである、ロンドンのレンタル自転車の利用ログデータを拝借して練習してみることとしました。
下にテーブルのフルパスはこちら ↓
`bigquery-public-data.london_bicycles.cycle_hire`

最初の座学では BigQuery の概要や利点、SQL の基本構文や型など、利用する上で最低限身につけなければならない知識をお伝えしました。特に構文は記載する順番と実行の順番が異なるため、慣れてしまえば当たり前になりますが、初見はつまづきやすいポイントかもしれません。

コンソールの使い方や簡単な関数の説明も加え、早速演習問題に入りました。
SELECT FROM は勿論必須なのですが、GROUP BY 句や、WHERE 句は次によく使う句として是非覚えて頂きたいです。

簡単な分析ができるようになったら、もう次は BigQuery での ML 開発です。
BigQuery ML はその名の通り、BigQuery 上で機械学習モデルが作れるのですが、すごいのが Python の知識は不要で SQL さえ分かっていれば良いという点です。
使えるモデルタイプも多種多様にあり、設定できるハイパーパラメータも多く用意されているので、初心者から上級者まで利用することができます。
テーブルデータにおいては最速で ML モデルが作れるプラットフォームなのではないかと思います。
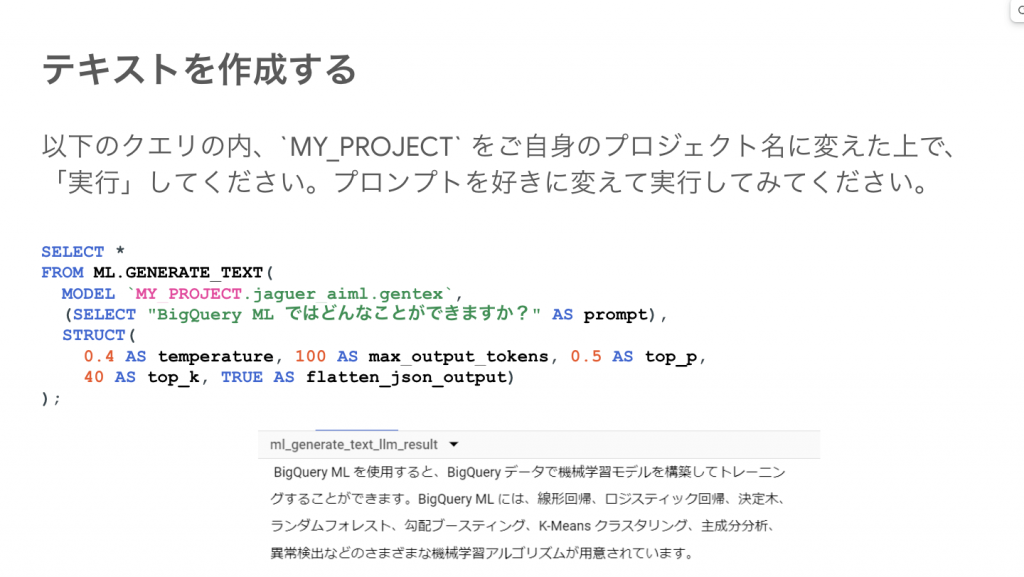
最後のおまけに、BigQuery でのテキスト生成デモを行いました。
そうなんです、BigQuery では LLM が使えるんです。テキスト生成、感情分析、テキストエンベディングなど、DB・DWH の領域を超える使い方ができてしまうんです!
テキスト生成はエンドポイントを変えることで Gemini 1.5 pro や Gemkni 1.5 fast など最新のモデルを使えるだけでなく、Google Search によるグラウンディングやRAGもできるので、かなり奥深い使い方ができそうです。
ブログ締めの言葉
こんな感じで基礎から最新の使い方まで広範に渡る内容でお送りしました。参加後のアンケートが別の設問で上書きされてしまったので記憶を頼りに書きますが、勉強になった、BigQuery のことの凄さを感じたとポジティブな回答を頂けましたが、上記の通り内容が広範になってしまったが故についていけなくなってしまったとのお声も頂きました。
オンラインのみの開催でしたので、次回またやるとしたらサポートがしっかりできるようにオフラインでの開催も企画して参ります。
ご参加頂いた皆様、本当にありがとうございました!
(Mario(岡安 優) / 株式会社unerry)