
Observability/SRE 分科会 【第3回】MeetUp開催しました!
皆様、こんにちは。Observability/SRE分科会です。
これまではGoogle山口さん、中丸さんにObservability/SREのイロハを教えていただいてまいりましたが
8月30日に開催した第3回のObservability/SRE分科会では
Belong福井さん、NTTデータ宇都宮さんにそれぞれ「ご自身で実践しているObservabilityって?」という題材で
LTを行っていただきました!
お二人とも内容が全く異なり、示唆に富んだ内容でした!
Belong福井さん、NTTデータ宇都宮さん、お疲れ様でした&ありがとうございました!
=================
LT1:Belong 福井さんからObservability の概要と GCP での適用例。
[ポイント]
Observability(o11y)とは”システムで何が起こっているかをどれだけ理解できるか”を示すもの。システムは(特にクラウドは)突然壊れるたo11yを高めて問題により早く気づき対処につなげることが大切。

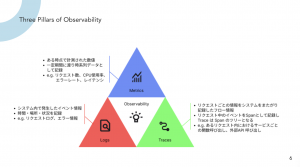
最初に福井さんが考えるObservabilityについてご説明いただきました。
- 時系列データ、監視されているパフォーマンスデータなど
- ゴールデンシグナル
- GCPでは特にCloud Monitoringで監視、ビジュアライズ、アラートまで全て行うことができる
- Belongではモニタリング専用のプロジェクトのCloudMonitoringにメトリクスを集約している。
ということを教えていただきました。
福井さんのすごいところは、ご自身がCTOというお立場だからなのか、元々好きなのか、それは神のみ知るところですが、
Google Cloudを使ってObservabilityを実践し、常にトライアンドエラーを繰り返しているというではないでしょうか。

- Traces
- アプリケーションのリクエスト処理の経路やボトルネックの明確化
- Belongでは主要関数毎にSpan作成するポリシー

- Logs
- Cloud Loggingでログの構造化の活用
- Belongではガイドライン策定による正規化をしている
- Log SinkによりBigQueryなどへの書き出し、SQLによる分析などが可能
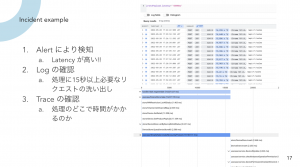
- 例としてMetricsアラートで検知→Logで事象の絞り込み→さらなる分析をTraceという流れ
[まとめ]
- GCPでo11yのツールセット(Cloud MonitoringやLogging、Traceなど)が揃っている
- 監視の目的を明確にし継続的に改善をすることが重要
- o11yはSRE/SWE双方の取り組みが大切
- ただ記録するだけではない。何を記録して何を追跡するか・分析するか

これぞ、王道のObservabilityという感じでした。
やっぱり、ストリートファイトしている(実践している)人の言葉和深いなー、その一言です。
たくさんの示唆があり、素晴らしかったです!
Q&A
- Iret堂原さん
- Q: Logは取れば取るほどコストが上がる、ガイドライン取り組みがあれば教えて
- A:
- 一定のサンプリングレート(Cloud LoggingのExclusionsなどで%割合で残すログ量を決める。50%だと全量の半分だけ残す。)でログを減らすことができる
- Belongでは100%の量でも多くないので、100%取っている。
- ミッションクリティカル度によってコストとサンプリングレートを折り合わせる。
- ミッションクリティカルが低ければ、サンプリングレートを下げてもやむなし。
- スクエニ橋本さん
- Q(参加者の人たちに向けて) Cloud Loggingを使っている方何人いらっしゃるか
- 8名 / 全22名
- Q(参加者の人たちに向けて) 3rd Partyを使っている方何人いらっしゃるか
- 4名
- Q(参加者の人たちに向けて) Cloud Loggingを使っている方何人いらっしゃるか
LT2:NTTデータ 宇都宮さんからのGoogle Cloud と SaaS で Observability を一歩前へ。
[ポイント]
- 最新の仕組みてんこ盛りですごい(ただの感想になってしまった)
- ユーザに対してGoogle Cloud や SaaS を活用したマルチテナントなコンテナ基盤に取り組んでいる
大手SIerであるNTTデータ所属の宇都宮さんからとある Observability ユースケースを説明いただきました。
最初は参加者も「なるほど、なるほど」と聞いており、この後どんな話をするのだろうと半信半疑だった人も多かったと思います。
と、基本的にはユーザ会内でのお話なので、これ以上の公開は・・・。
ヒントは「Chos Engineering」。
Faultをさせないシステムを作る会社という認識があったNTTデータさんで、まさかこんなに進んでいる取り組みをしているなんて・・・。
それが私の率直な感想ですw
[まとめ]
- Google CloudとSaaSサービスを活用したo11y環境の紹介。まだまだ試行錯誤中
- Google Cloudでもマネージドなカオスエンジニアリングサービスが欲しい!
[最後に筆者から]
繰り返しとなりますが、Belong福井さんの王道・実践ObservabilityとChaos Engineeringというチャレンジを行っているNTTデータ宇都宮さんのObservability、非常に示唆に富んだ、素晴らしい内容でした。
第一回目から素晴らしいLTだったので、ハードル上がっちゃったなーwww
次回は11月12月ごろに開催したいと思いますので、ご興味ある方は是非Observability/SRE 分科会へ!!!