
Observability/SRE 分科会 【第2回】MeetUp開催しました!
皆様、こんにちは。Observability分科会のGoogle Cloud でテクニカルアカウントマネジャーをしている加藤です。
このブログを作成している間に梅雨明けとなり、暑い季節になりました。
今回6月20日に第二回のObservability分科会でのMeetUpが開催されました。
この投稿では先日おこなわれたObservability 分科会 第二回をレポートします。
=================
6月20日に Observability 分科会がオンラインで開催されました。
今回は第2回、冒頭に分科会のリーダーに就任いただいたスクエアエニックス(以下SQEXと記載)の橋本さんとコアメンバーにご参加いただいたBelongの福井さんからご挨拶をいただきました。
弊社カスタマーエンジニアの中丸より、ObservabilityのスタートであるSLI/SLO Menuどう作っているか、どのように入門するのかというのをテーマにをどうやって始められるかということで、Google Meetを活用したワークショップ形式で開催をさせていただきました。

多くのベストプラクティスではまずは、SLI/SLOのMenuを作ることから推奨しておりますが、非常に抽象度が高く、中々これが難しいのですが、今回は具体的かつ身近なシュチュエーションを想像しながら実際にどのように作るのかを考えて行きました。今回のブログでは私自身のワークショップの振り返りも参考例に記載しておこうと思います。

自分の仕事をサービスとして考えたときにサービスレベルを捉える指標を定義するしていくところから始まります。ちなみにテクニカルアカウントマネージャのサービスレベルの一つは、お客様満足度です。

LOBの方であったり、エンドユーザなど、色々議論がありました。テクニカルアカウントマネジャーの場合はサービスをご利用頂いているお客様となります。

想定通りにシステムが稼働しているなど議論がありました。テクニカルアカウントマネジャーならば、お客様満足度を構成しているもの、例えばご利用頂いているお客様のサービスローンチがうまくいったとか、ケースが削減できたりだとか、コスト削減提案などがあげられます。

xx回のサービスローンチのうち○回成功した、1ヶ月のケース数が△%削減できた、コスト削減提案で□%削減できたなどでしょうか。

もう一段落とし込みが必要ですね。例えばxx回のうち仮に90%以上でうまく支援できているというような指標をおき、その上で○回成功したのはその90%を超えたので、うまく支援しているという判断になる、という論理ですね。


これをどのように計測し、改善していくか、これを繰り返ししていくののがSLI/SLOの基礎的な考え方になるのです。
中丸のセッションでは引き続きSLI /SLOの設定に関して給与明細システムの例をお話しました。


SLOも闇雲に設定するのではなく、ユーザありきで設定していくことをお伝えしました。
(みなさまからのコメント)
・SQEX)橋本さんのコメント
元のSLI/SLO設定をするのは難しいが、具体的かつ身近な例を踏まえた今日のセッションはわかりやすかった。
・unerry)蔵谷さんのコメント
システムが大きくなってきたことからSREにチャレンジをしよう考えていた中で、どこから取り掛かるかという今回のワークショップが役にたちました。
続いて橋本さんからSQEX様におけるSREの取り組みについてご紹介いただきました。

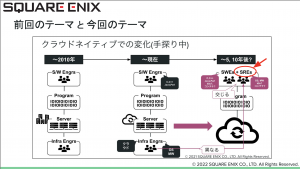
SREを足掛け4年近く取り組まれているといらっしゃるとのこと。
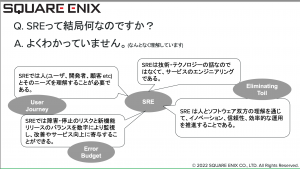
4年近く取り組まれていらっしゃいますが、いまだにかっちりとしたSREの定義はないとのコメント。

しかし、それをいかに解釈するかがポイントと橋本様はおっしゃっており、実際SQEX様のキャリアサイトのJD(Job Disicpiton)では以下のように記載されています。
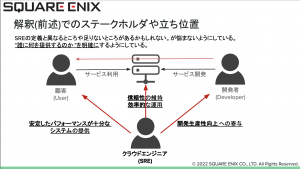
そのためにSQEX様ではステークホルダーや立ち位置を明確にしているとのことです。
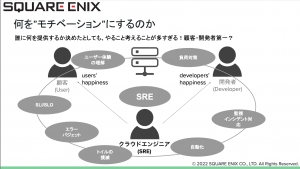
一方でSREの活動は何をモチベーションにするのかという点があります。
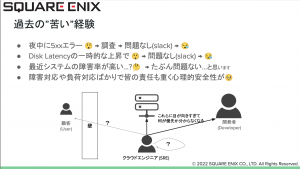
ここで過去の経験をお話しいただきました。(特にゲーム業界では)インフラが止まると機会損失となることから障害対応プレッシャーもあり、これをどのようにステークホルダーに理解してもらうかということに苦慮されたとのことでした。
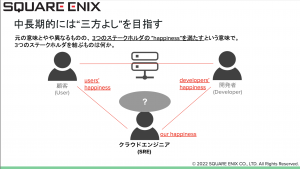
短期的には自分達のツラミを解決することなのですが、3つのステークホルダーがHappinessを満たす(=三方よし)というのが大変印象深いお話でした。
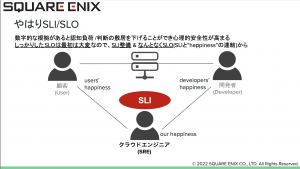
そしてステークホルダー間を結ぶのがSLI&なのでなんとなくSLO(いきなりちゃんとしたSLOをいきなり定めるのは難しい。)とのお話でした。。
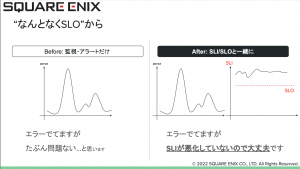
なんとなくSLOを決めていくことで、監視・アラートで漠然とした運用がSLIをベースにすることで心理的安全性を高めるためには自分達が説明しやすい数字的な指標と根拠になっていくというのはどの組織においても共通ではないでしょうか。
(参加者から橋本さんへのご質問&コメント)
New Relic)岩田さんからご質問
- SREに至るキャリアについて
SQEX)橋本さんのご回答
- ネットワークエンジニアからサーバインフラに少しづつ領域を広げていった。コンテナも触るので、ある程度コードが書けることは必要だと思う。
KDDI)須田さんからのコメント
- SLI/SLOを決めるの悩んでるんですけど、SLIも一つで判断できるものを決めるのは難しいので、運用実績か らユーザの不満に繋がったものを測定可能にして、SLIとしていくって感じかなあと思いました.
フロントエンドのモニタリングに苦労している。
Belong)福井さんからのコメントと質問
インシデント発生時のオンコールの担当フローや責務の切り分け等は決めていますか?
例えば 「API のレスポンスが遅い」と言った時に NW / ソフトウェアロジック / DB など調べるべきポイントは色々あると思いますが、初手が誰でいつ誰に引き継ぐのかなどをどう管理しているのか気になりました。
SQEX)橋本さんのご回答
- まだ手探り・その都度対応している
パナソニック)藤井さんからのご質問
- SREの経営層の理解で苦労されている連などありますでしょうか。(理解してくれない、など)
SQEX)橋本さんのご回答
- 基本は内製を進めることがポイント。HCの予算を内部で確保する方が簡単。外部のSREを採用するのは難しい。。。
SQEX)橋本さんからの締めのコメント
悩んでいることをみんなで共有して行きたいので、積極的な議論のご参加をお願いします。
Google Cloudのテクニカルアカウントマネジャーがご支援しているお客様でもSREの組織作りに取り組まれている会社様は多く、Observabilityに対する関心が高いことを感じている今日このごろです。
幸いこの分科会も発足して3ヶ月で50名以上のメンバーが参加して頂いております。
ぜひこの分科会の活動を通してお互いの悩みを語りながらよりよりObservability、SREの組織化について議論できると幸いです。